XiaoMi-AI文件搜索系统
World File Search System视觉



稳态视觉诱发电位识别与便携式脑机接口系统实现
致谢 ............................................................................................................................. 67
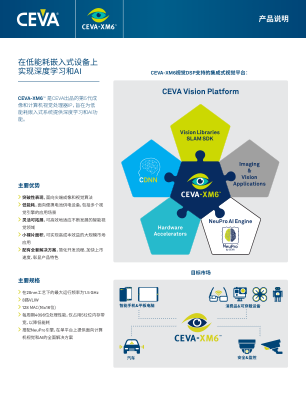
在低能耗嵌入式设备上实现深度学习和AI - Ceva, Inc.
智能嵌入式视觉应用的设计变得前所未有 的快捷而安全,这要归功于围绕 CEVA-XM6 DSP 而构建的全方位视觉平台。该平台包含 CEVA 深度神经网络( CDNN )编译器图表、计 算机视觉软件库以及一系列算法。


视觉
试卷系列 试卷综合研究 (P) 2020 – 测试 –2977 允许时间:两小时 最高分数:200 说明 1. 考试开始后,您应立即检查此手册是否没有任何未打印或翻转或缺失的页面或项目等。如果有,请用完整的试卷替换它。 2. 在答题纸的适当位置清楚地编码试卷系列 A、B、C 或 D(视情况而定)。 3. 您必须在试卷旁边提供的框中输入您的学号。不要在试卷上写任何其他内容。 4. 本试卷包含 100 个题目(问题)。每个题目都以英文印刷。每个题目包含四个答案。您可以选择要在答题纸上标记的答案。如果您认为有多个正确答案,请考虑最佳答案。无论如何,每个题目只能选择一个答案。 5. 您必须在单独提供的答题纸上标记所有答案。请参阅答题纸上的说明。 6. 所有题目的分数相同。尝试回答所有题目。您的总分将仅取决于您在答题纸上标记的正确答案数量。对于每个错误答案,将扣除分配分数的 1/3。 7. 在答题纸上标记试卷中各个题目的答案之前,您必须按照随准考证发送给您的说明在答题纸上填写一些详细信息。 8. 在您完成填写答题纸上的所有答案并考试结束后,您应该只将答题纸交给监考人员。试卷可以带走。9. 试卷最后附有草稿纸。

视觉
试卷系列 试卷综合研究 (P) 2020 – 测试 – 2976 允许时间:两小时 最高分数:200 说明 1. 考试开始后,您应立即检查此手册是否没有任何未打印或翻转或缺失的页面或项目等。如果有,请用完整的试卷替换它。 2. 在答题纸的适当位置清楚地编码试卷系列 A、B、C 或 D(视情况而定)。 3. 您必须在试卷旁边提供的框中输入您的学号。不要在试卷上写任何其他东西。 4. 本试卷包含 100 个题目(问题)。每个题目都以英文印刷。每个题目包含四个答案。您可以选择要在答题纸上标记的答案。如果您认为有多个正确答案,请考虑最佳答案。无论如何,每个题目只能选择一个答案。 5. 您必须在单独提供的答题纸上标记所有答案。请参阅答题纸上的说明。 6. 所有题目的分数相同。尝试回答所有题目。您的总分将仅取决于您在答题纸上标记的正确答案数量。对于每个错误答案,将扣除分配分数的 1/3。 7. 在答题纸上标记试卷中各个题目的答案之前,您必须按照随准考证发送给您的说明在答题纸上填写一些详细信息。 8. 在您完成填写答题纸上的所有答案并考试结束后,您应该只将答题纸交给监考人员。试卷可以带走。9. 试卷最后附有草稿纸。

基于视觉反应的脑部疾病计算机视觉
4 BIAI INC.,美国马萨诸塞州切姆斯福德,5 BIAI Intelligence Biotech LLC,中国深圳,6 哈佛大学医学院神经内科,美国马萨诸塞州波士顿,7 波士顿大学眼科协会眼科系视网膜分部,美国马萨诸塞州波士顿,8 中国科学院深圳先进技术研究院高性能计算中心,中国深圳,9 广州医科大学附属脑科医院(广州惠爱医院)情感障碍科和情绪与脑科学院士工作站,中国广州,10 暨南大学粤港澳中枢神经系统 (CNS) 再生研究所,中国广州,11 复旦大学数学科学学院非线性数学模型与方法重点实验室,中国上海,12 麻省总医院精神病学系抑郁症临床与研究项目,美国马萨诸塞州波士顿, 13 香港大学眼科学系脑与认知科学国家重点实验室,香港薄扶林

