XiaoMi-AI文件搜索系统
World File Search SystemAda

ADA 过渡计划
• 必须以这样的方式运行其程序,即当程序完整浏览时,残障人士可以访问和使用这些程序(28 CFR Sec.35.150)。 • 不得仅仅因为残疾人有残疾而拒绝其参与服务、计划或活动(28 CFR 第 35.130 (a) 条)。 • 必须对拒绝残疾人平等参与的政策、做法和程序做出合理修改,除非会导致计划发生根本性改变(28 CFR 第 35.130(b) (7) 条)。 • 不得通过独立或不同的计划向残疾人提供服务或福利,除非需要采取独立或不同的措施来确保福利和服务具有同等效力(28 CFR 第 35.130(b)(iv) 和 (d) 条)。 • 必须采取适当措施确保与申请人、参与者和残疾公众成员的沟通与与其他人沟通一样有效(29 CFR 第 35.160(a) 条)。 • 必须指定至少一名负责协调 ADA 合规性的员工 [28 CFR 第 35.107(a) 条]。此人通常被称为“ADA协调员。”公共实体必须向所有相关个人提供 ADA 协调员的姓名、办公地址和电话号码 [28 CFR Sec. 35.107(a)]。 • 必须提供 ADA 要求的通知。所有公共实体,无论规模大小,都必须向申请人、参与者、受益人、员工和其他相关人员提供有关第二章权利和保护的信息 [28 CFR Sec. 35,106]。通知必须包括担任 ADA 协调员的员工的身份证明,并且必须持续提供此信息 [28 CFR Sec. 104.8(a)]。 • 必须建立申诉程序。公共实体必须采用并公布申诉程序,以便迅速公平地解决投诉 [28 CFR Sec. 35.107(b)]。此要求及时解决与 ADA 合规性相关的所有问题或冲突,以免它们升级为诉讼和/或联邦申诉程序。
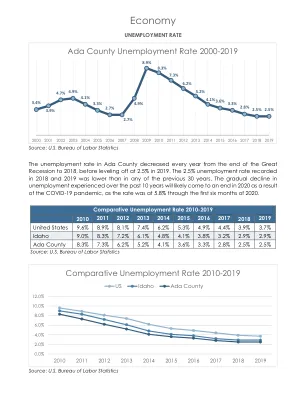
经济 - 艾达县
总计 62,649 71,173 8,524 14% 艾达县拥有三个公立学区。西艾达学区是该州最大的学区,包括 6 所高中、11 所中学、26 所小学和 13 所替代学校,学生入学人数超过 40,000 人。西艾达学区从 2010 年到 2020 年增加了 7,000 多名学生,因为它服务的地区在过去十年中经历了显着增长。博伊西学区拥有 5 所高中、8 所中学和 33 所小学,覆盖了该县增长较慢的地区,该地区大部分已经开发完毕。因此,其学生入学人数在过去十年中变化不大,仅增加了 200 多名学生。库纳学区虽然比西阿达和博伊西学区小得多,但自 2010 年以来,其学生人数增长了 12%,增长率显著。库纳学区目前包括 2 所高中、2 所初中和 6 所小学。

Dry-Creek-Ranch-Recreation-Plan.pdf - 艾达县
休闲计划执行摘要 以下计划描述了 Dry Creek Ranch 计划社区步道系统、公园和村庄中心的使用和维护的现有和未来规划指南。本文档的目标是提供指定概述,以便在以保护为重点的社区内提供优质的休闲体验。如果 Dry Creek Ranch 休闲计划 (DCRRP) 和 Dry Creek Ranch 野生动物缓解计划 (WMP) 之间存在冲突,则 WMP 应在所有方面进行管理。DCRRP 概述了与用户安全、野生动物栖息地管理、步道维护和可持续性指南相关的使用指定。DCRRP 的目的是创建一个可持续的步道和社区公园系统,并限制用户冲突和对野生动物及相关栖息地的影响。DCRRP 还概述了审查社区活动、制定年度工作计划、有关新步道或设计的建议以及季节关闭(如有必要)的决策过程。这些想法将提交给 Dry Creek Ranch 休闲委员会 (DCRRB)。 DCRRB 将向 Dry Creek Ranch 保护咨询委员会 (DCRCAC) 提出建议。该计划旨在创建一个流程,以满足社区公园和步道系统不断变化的需求和条件。随着娱乐模式、区域步道系统和相邻土地所有权的变化,DCRRP 流程将适应需求和机会,以提供最佳用户体验和娱乐机会,同时保持保护目标。用户指定和指南社区公园和步道系统为所有类型的用户提供了广泛的娱乐机会。为了在平衡保护要求、用户安全和步道限制的同时创造最愉快的娱乐体验,Dry Creek Ranch 为特定区域和步道制定了使用指定。了解到这可能会限制某些用户进入理想的区域和步道,这是尝试管理用户冲突并为所有类型的用户提供最佳整体用户体验的最佳方式。除了指定区域和步道以减少用户冲突外,步道系统的某些部分可能会因天气相关条件而受到限制。在冬季,将监测步道状况,以确定是否需要进行调整以保护步道的稳定性。用户类型如前所述,Dry Creek Ranch 内的部分步道将与 Ada County Parks and Waterways 管理的区域步道系统相连。为了最大限度地提高用户体验并保护土地上的自然资源,Dry Creek Ranch 根据用户类型和交通方式指定了一些区域。步道用户可能包括徒步旅行者和野生动物观察者、山地自行车手、骑马者、牵绳和不牵绳的狗。



ADA 指南第 7 章 - 标志
触觉字符的中心位置必须留出至少 18 英寸 x 18 英寸的净地板空间。净地板空间的这种放置方式为标志处提供了无障碍站立空间,以便通过触摸读取。该空间的高度不得超过 80 英寸。为了安全起见,该空间必须位于任何门摆弧线之外,以达到 45° 的开启位置。这实际上设定了触觉标志与外摆门之间的最小距离,但不是绝对距离。虽然净地板空间必须位于触觉字符的中心位置,但标志可以位于门摆之外的不同距离处。

2025 ADA过渡计划
概述《美国残疾人法案过渡计划》(“计划”)是芒斯特镇的承诺,致力于为残疾公民提供平等的公共计划,服务,设施,设施和活动。为了制定该计划,芒斯特镇已经对其设施和计划进行了全面评估,以确定残疾人患者存在哪种类型的访问障碍。该计划取代了该镇及其部门制定的以前的自我评估和过渡计划,并将用于指导未来的计划和实施必要的可访问性改进。1990年的《美国残疾人法》(ADA)是一项联邦民权立法,该立法对残疾人施加了非歧视。美国国会于1990年签署了ADA,并于1992年生效。ADA是一项禁止歧视残疾人的民权法。ADA的标题I禁止地方政府在职位申请程序,招聘,解雇,晋升,薪酬,职业培训以及其他术语,条件,条件,条件和就业特权中歧视合格的残疾人。ADA的第二名禁止根据1973年《康复法》第504条所包含的残疾。。ADA的第二名禁止根据1973年《康复法》第504条所包含的残疾。它禁止该镇否认残疾人通过合同协议直接或间接参与其服务,计划或活动的平等机会。在2012年11月,该镇制定了其最初的ADA过渡计划。作为联邦资助的接收者,重要的是,芒斯特镇必须遵守所有适用的联邦和州法律,包括根据1973年《康复法》第504条保护残疾人的那些法律。该计划于2024年更新。此2025版本是最新的修订版。当设施和道路允许时,芒斯特镇将继续努力消除可及性的物理障碍。如果访问不可行或可用,将为残疾人提供相同机会的替代手段。负责任的官员临时城镇经理被指定为芒斯特镇的ADA合规协调员。此人负责制定和实施ADA过渡计划和ADA的整体遵守情况,包括公共通行权(街道,人行道,十字路口)以及公共结构和设施(建筑物,公园)。公告该镇对原始ADA过渡计划提供了两次公开会议,以供公众发表评论。会议于2012年12月10日下午7点和2012年12月28日上午11点举行。该计划的当前版本将发布在该镇的网站上,还将在城镇经理和店员的办公室中提供。该镇将每年更新计划及其相关的改进项目列表,以反映完整的改进项目,或公众适当建议的补充或更改。

MDOT ADA过渡计划
MDOT认识到主动参与公众在运输计划中的重要性,以及消除残疾人的访问障碍。MDOT创建了一个跨学科团队,以协助其ADA自我评估和过渡计划的开发,评估和实施以及地区公众宣传。此外,MDOT的ADA/504合规性工作的重要组成部分是培训。MDOT的ADA/504部分拥有一个建立的多学科团队,以确定各种MDOT部门的ADA和标题II培训需求。它将与跨学科团队合作,根据需要向MDOT员工和相关利益相关者开发和提供针对性的培训。培训将解决与ADA和Title II有关的设计和政策问题。

ADA 唾液诊断指南
牙科诊所使用经过认证的实验室处理唾液样本,以检测与牙周病相关的生物标志物。患者提供样本,这些样本经过仔细收集并送至实验室,实验室使用先进的技术识别相关生物标志物。在这种情况下,应使用适当的 CDT 代码(例如用于样本收集的 D0417 和用于样本分析的 D0418)来记录患者记录中的程序。这些代码准确反映了诊断意图。

NVIDIA ADA GPU 架构
NVIDIA® Turing™ GPU 架构于 2018 年推出,开创了 3D 图形和 GPU 加速计算的未来。Turing 为 PC 游戏、专业图形应用程序和深度学习推理提供了效率和性能方面的重大进步。使用新的基于硬件的加速器,Turing 融合了光栅化、实时光线追踪、AI 和模拟,使 PC 游戏具有令人难以置信的真实感,并带来了影院级的互动体验。两年后的 2020 年,NVIDIA® Ampere 架构整合了更强大的 RT Cores 和 Tensor Cores,以及新颖的 SM 结构,与 Turing GPU 相比,可提供 2 倍的 FP32 性能(时钟对时钟)。这些创新使 Ampere 架构在传统光栅图形中的运行速度比 Turing 快 1.7 倍,在光线追踪中的运行速度比 Turing 快 2 倍。