XiaoMi-AI文件搜索系统
World File Search SystemAlphaFold

Casgen:CRISPR CAS蛋白设计的正规生成模型,具有分类和基于保证金的优化
群集定期间隔短的短质体重复序列(CRISPR)相关蛋白(CAS)系统通过提供高精度和多功能性来彻底改变了基因组编辑。然而,大多数基因组编辑应用都依赖数量有限的良好特征的CAS9和CAS12变体,从而限制了更广泛的基因组工程应用的潜力。在这项研究中,我们广泛探索了CAS9和Cas12蛋白,并开发了Casgen,这是一种基于边缘的基于边缘的潜在空间正则化的新型深层生成模型,以增强新生成的Cas9和Cas12蛋白的质量。具体来说,卡斯根采用一种结合分类来过滤非CAS序列的策略,对潜在空间的贝叶斯优化来指导功能相关的设计,并使用基于Alphafold的分析进行彻底的结构验证,以确保稳健的蛋白质产生。我们从知名的生物数据库(例如InterPro和PDB)中收集了一个具有3,021 cas9、597 Cas12和597个非CAS蛋白序列的综合数据集。为了验证生成的蛋白质,我们使用BLAST工具进行了序列对齐,以确保新颖性并过滤到与现有CAS蛋白的高度相似序列。使用AlphaFold2和AlphaFold3的结构预测证实,生成的蛋白质与已知CAS9和CAS12变体具有很高的结构相似性,TM分数在0.70至0.85之间,并且root-Mean-square偏差(RMSD)值低于2.00。序列身份分析进一步表明,生成的CAS9直系同源物在已知变体中表现出28%至55%的身份,而CAS12A变体的身份高达48%。我们的结果表明,提出的CAS生成模型具有通过设计保留功能完整性的各种CAS蛋白来扩展基因组编辑工具包的重要潜力。开发的深层生成方法为合成生物学和治疗应用提供了有希望的途径,从而为开发了更精确,更通用的CAS基因组编辑工具的开发。

Casgen:CRISPR CAS蛋白设计的正规生成模型,具有分类和基于保证金的优化
群集定期间隔短的短质体重复序列(CRISPR)相关蛋白(CAS)系统通过提供高精度和多功能性来彻底改变了基因组编辑。然而,大多数基因组编辑应用都依赖数量有限的良好特征的CAS9和CAS12变体,从而限制了更广泛的基因组工程应用的潜力。在这项研究中,我们广泛探索了CAS9和Cas12蛋白,并开发了Casgen,这是一种基于边缘的基于边缘的潜在空间正则化的新型深层生成模型,以增强新生成的Cas9和Cas12蛋白的质量。具体来说,卡斯根采用一种结合分类来过滤非CAS序列的策略,对潜在空间的贝叶斯优化来指导功能相关的设计,并使用基于Alphafold的分析进行彻底的结构验证,以确保稳健的蛋白质产生。我们从知名的生物数据库(例如InterPro和PDB)中收集了一个具有3,021 cas9、597 Cas12和597个非CAS蛋白序列的综合数据集。为了验证生成的蛋白质,我们使用BLAST工具进行了序列对齐,以确保新颖性并过滤到与现有CAS蛋白的高度相似序列。使用AlphaFold2和AlphaFold3的结构预测证实,生成的蛋白质与已知CAS9和CAS12变体具有很高的结构相似性,TM分数在0.70至0.85之间,并且root-Mean-square偏差(RMSD)值低于2.00。序列身份分析进一步表明,生成的CAS9直系同源物在已知变体中表现出28%至55%的身份,而CAS12A变体的身份高达48%。我们的结果表明,提出的CAS生成模型具有通过设计保留功能完整性的各种CAS蛋白来扩展基因组编辑工具包的重要潜力。开发的深层生成方法为合成生物学和治疗应用提供了有希望的途径,从而为开发了更精确,更通用的CAS基因组编辑工具的开发。

第三次人工智能浪潮
为什么这项关键技术现在为德国和欧洲提供了历史性机遇 作者:Holger Hoos 和 Kristian Kersting 一方面,人类正面临着巨大的挑战——气候变化、流行病、地缘政治变化和人口结构变化。另一方面,也取得了巨大的进步:分子手术刀 CRISPR-Cas9 正在彻底改变精准医疗,引力波已经被探测到,更便宜、可重复使用的太空飞行器正在提供以前难以想象的太空通道。这既令人欣慰又必要,因为我们这个时代的主要问题需要远远超出目前科学和技术可行性的解决方案。人工智能 (AI) 在此背景下发挥着特殊作用,原因有二:首先,这些问题至少在一定程度上是由人类智力的自然局限性造成和加剧的。其次,作为数字化转型的下一阶段,人工智能是一种应用范围广泛的通用技术。令人担忧的是,人们对人工智能到底是什么仍然存在困惑。有时,它被用来指代展现人类智能全谱的机器,从而至少在原则上可以取代或超越人类,其后果令人担忧,这是可以理解的。另一方面,一段时间以来,人们倾向于将人工智能等同于机器学习,或者更狭义地说,等同于使用人工神经网络的所谓深度学习。这两种人工智能概念都是误导性的。所谓的转换器可以根据最少的输入添加或几乎完全编写文本。1956 年,美国计算机科学家约翰·麦卡锡 (John McCarthy) 创造了“人工智能”一词,此后,该词被定义为对能够重现智能(不一定是人类)行为的计算机程序的追求。然而,人工智能的核心问题早在 1950 年就由英国计算机先驱艾伦·图灵提出:机器能思考吗?事实上,人工智能最近取得了令人印象深刻的重要进展,特别是在机器学习领域,无论是在基础研究还是在应用方面。Deep Mind 最近开发的“AlphaFold 2.0”程序已被证明能够以实验室实验的精度预测蛋白质的三维结构,从而有助于更好地诊断和治疗疾病,或设计专门用于产生能量或分解污染物的酶。我们(幸运的是)距离实现涵盖人类智能全部范围的通用人工智能还很远。与此同时,当前的人工智能技术不仅仅涵盖机器学习。除了学习之外,逻辑和数学推理、知识建模等方法和

传染病流行病学与人工智能的结合
传染病仍然是对公共健康的重大威胁[1-3]。本期传染病流行病学特刊将涵盖与传染病的出现、传播和控制相关的研究,包括展示潜在治疗干预措施的新研究。本期将涵盖病毒、细菌和寄生虫病,重点关注新兴研究领域,如建模、临床研究、纵向队列和病例对照研究、系统生物学方法、人工智能 (AI)、机器学习以及其他分子和免疫学研究[4-6]。人工智能和机器学习可用于研究不同生物系统(如信号通路和代谢网络)之间的复杂相互作用,以增进我们对各种生物现象的理解并改善疾病的诊断和治疗[5、7、8]。这些技术有可能对传染病和流行病学等多个领域的生物学研究产生重大影响,正如MDPI 期刊《病原体》的特刊“传染病流行病学论文”中所强调的那样。人工智能和机器学习可用于分析大型数据集(如基因组数据),以确定与理解和治疗传染病相关的模式和趋势[9-12]。例如,机器学习算法已被用于识别导致COVID-19的SARS-CoV-2的潜在药物靶点[13,14]。此外,人工智能和机器学习可用于根据历史数据和分析流行病学研究生成的数据集来预测某些结果(如疾病传播)的可能性。这可以帮助流行病学家预防或减轻流感和艾滋病毒等传染病的爆发。人工智能还可用于构建预测模型,帮助研究人员了解不同变量之间的关系,例如基因表达和疾病风险、分子水平上病原体和宿主生物之间的相互作用以及生物分子内复杂的分子相互作用。人工智能在生物研究中的应用包括 AlphaFold [ 15 , 16 ],它可以高度可信地预测蛋白质的二级和三级结构 [ 17 , 18 ],以及 DeepMind,它可以分析细胞或组织图像以识别与研究相关的特定特征或模式。最近引起媒体关注的一个应用是人工智能处理自然语言的能力。在这方面,Open AI 的聊天机器人 ChatGPT 可以处理自然语言文本,可用于执行复杂分析并帮助非英语流行病学家起草文章。ChatGPT 可以提供科学术语的定义,生成任何疾病的流行率和风险因素图等。这些努力可以彻底改变生物科学研究,但此类人工智能平台的输出需要验证,特别是在许多社会、经济、行为和流行病学研究中

提高国产基因组编辑工具“锌指-ND1”的功能性......
修改目标 DNA 的基因组编辑工具是基因和细胞治疗的有力工具。目前主要的基因组编辑工具是CRISPR-Cas,应用最为广泛;其次是TALEN;最后是ZFN,应用最少。其中CRISPR-Cas和TALEN的基本专利将持续到2030年甚至更晚,因此在医疗领域使用需要高额的授权费用。另一方面,ZFN的基本专利已于2020年到期,它是一种可免许可使用的基因组编辑工具。通过将识别DNA的Zinc Finger与切割DNA的FirmCutND1 Nuclease(由广岛大学自主开发)相结合,可以制作出名为“Zinc Finger-ND1”的纯国产基因组编辑工具。然而,构建功能性ZFN并提高其基因组编辑效率极具挑战性。 [研究成果总结] 传统上,创建ZFN的主流方法是从随机重排的ZF中筛选与目标DNA结合的ZF。然而,创建功能性 ZFN 大约需要两个月的时间,这需要大量的时间和精力。另外,人们设计了一种称为“模块化组装”的方法,用于将 ZF 在基因上连接起来,但在制作三指 ZFN(三个 ZF 连接在一起)时,获得功能性 ZFN 的概率约为 5%,由于生产效率低,该方法无法使用。我们假设,手指数量少导致可识别的碱基数量减少,从而导致产生功能性 ZFN 的效率降低。因此,在本研究中,我们采用模块化组装的方式构建了一个6指ZF-ND1(图1),以增加其识别的碱基数量。结果,我们构建的10个ZF-ND1中,有两个被证实具有基因组DNA切割活性,这意味着我们以20%的概率成功获得了功能性ZFN。为了进一步完善ZF-ND1的功能,我们使用结构建模技术(AlphaFold、Rossetta和Coot的分子建模)来模拟ZF和DNA之间的相互作用(图2)。通过与 Zif268(一种与 DNA 结合的天然 3 指 ZF)的 DNA 相互作用模型进行比较,确定了五种候选突变。此外,通过比较与 Zif268 的 DNA 糖磷酸骨架结合的氨基酸,确定了四个突变候选者。当将这九个候选突变逐一引入功能性 ZF-ND1 时,发现其中三个突变(图 3)可提高基因组 DNA 切割活性。 V109K突变使裂解活性提高了5%,并且我们成功在结构建模的基础上增强了ZF-ND1的功能。

推动分子动力学模拟的前沿
说明此研讨会是MDDB项目的一部分。在短短的几十年中,分子动力学(MD)世界已经从一些高度专业的团体主导的领域,对技术和软件开发人员通常是方法和软件开发人员的深刻了解,转变为在包括生物学在内的许多科学领域都存在MD的情况。分子力学用于放松模型,例如在Alphafold中,现在许多实验技术等实验技术定期将其数据与仿真相结合,我们看到了数据驱动的建模的出现,其中大量的实验数据,例如。来自突变研究或基因组测序与模拟结合(尤其是在Covid-19大流行期间)。一方面,该领域在更准确的力场,更有效的MD发动机的开发,对增强采样算法的更好理解中取得了巨大进展 - 更不用说计算机的进步以及在具有预测能力的技术中转化了MD的定制设计硬件,该技术可用于削弱生命和生命的能力。但是,尽管该领域蓬勃发展,但我们也面临着许多挑战:Exascale计算机将提供比以往任何时候都更多的功率,但是在模拟中不可能使用所有这些功能,而无需取得采样算法的进步。同时,社区的努力正在协调数千台私人计算机的使用,这些计算机的合并功率允许在许多情况下获得比使用大型超级计算机获得的富裕的合奏。冷冻整体和超分辨率显微镜。经典的力场可以说是达到其极限,并且随着商品硬件越来越优化了对AI工作负载的优化,可以说是时候从根本上重新审视我们的方法来迫使我们的磁场,但是当前,这些方法降低了经典模拟的降低阶级,而在模拟长度上,我们会带来仿真的长度,这使我们回到了采样效率的质疑。MD模拟和粗粒子和介观模型的组合开放了研究的新领域,以研究甚至真核染色质的小细胞器,事实证明,这是一种非常有价值的补体,例如但是,这些模型显然没有达到整个系统中进行彻底采样的时间表;应该如何处理?我们可以将更多的实验数据集成为限制因素,还是需要新一代的超透明粒度模型?我们是否可以找到方法来对模型量表进行逐步缩放,而不会固有地卡在最内在/最慢的模型的时间范围内?我们认为,现在是时候审查最近的发展,批判性地评估有潜力进行重大科学进步的领域,确定可以解决的瓶颈和挑战,并共同制定了社区路线图,以解决关键问题。我们想审问和向现场世界领导者学习:
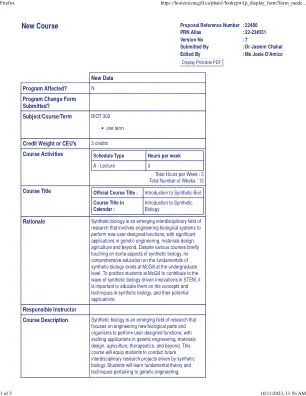
新课程
测验(占期末成绩的 15%):测验占课程期末成绩的 15%,课程中涉及的每个主要主题有一次测验。期末测验成绩将计算为所有测验成绩的平均值。测验将包括 8-10 个多项选择题答案,用于测试相应主题所涵盖的事实概念。将根据需要分配阅读材料。期中报告(占期末成绩的 35%):期中报告将重点关注课程第 2 部分中涵盖的主题,该部分涵盖了基本的合成生物学方法。将根据学生将所学技术应用于实际合成生物学研究场景的能力进行评估——包括分析的适当性和深度。期中报告将分为三个部分,每个学生被分配一个不同的人类酶进行报告。报告的第 1 部分涉及设计实验工作流程,将编码酶的基因克隆到大肠杆菌蛋白质表达骨架中。在第 2 部分中,学生选择从最合适的模型生物中纯化蛋白质的最佳策略,并提出实验工作流程。最后,在第 3 部分中,学生将设计用于 CRISPR/Cas9 的向导 RNA(gRNA),以促进人类细胞中指定基因的内源性敲除和表达调节。由于期中报告涵盖了课程的第 2 部分的全部内容,学生可以随着课堂上涉及相关主题而逐步完成期中报告的各个部分。期中报告的截止日期为 3 月 13 日,即完成期中报告所需的所有课堂材料后的一个月。期末报告(占期末成绩的 40%):期末报告将要求学生应用课堂上涵盖的其余概念 - 即基于合成生物学基础的第 3、4 和 5 部分。该报告测试学生将合成生物学概念应用于实际研究场景的能力。评估将基于学生在报告中提供的分析的准确性,以及学生对期末报告各个方面理由的论证能力。期末报告将分为两部分:第 1 部分将包括使用生物信息学工具合理设计具有潜在更高酶活性的蛋白质突变体。学生将对期中报告中指定的相同酶进行这项工作。这将涉及访问 Uniprot 以获取已知蛋白质同源物的序列,使用多序列比对 (MSA) 和 BLAST 比较同源物的氨基酸序列,以及使用 AlphaFold 比较两个蛋白质同源物的三级结构。第 2 部分包括将指定的蛋白质与其他酶一起掺入代谢途径以产生小分子代谢物的提案。第 2 部分要求学生整合代谢途径工程的基本概念,以最大限度地提高代谢物的产量和产量。学生还必须讨论如何结合遗传电路设计方面,使这种工程代谢途径可由小分子药物控制,从而调节代谢物的产生。与期中报告类似,学生可以在课程的后半段逐步涵盖主题,从而完成期末报告。期末报告将于 4 月 22 日截止,即所有必要的课堂主题讲完三周后。课堂参与(占期末成绩的 10%):学生将根据课堂出勤情况进行评分。此外,还将根据他们在讨论期间回答问题、提问和发表评论的参与程度进行评分。

SURF 和 VURP 摘要将最小浸入与...联系起来
将曲面上扁平线束的最小浸入与临界特征值度量联系起来 Santiago Adams 导师:Antoine Song 在现有文献中,第一个特征值在曲面上临界的度量与该曲面在任意维球面中的最小浸入之间存在着密切的联系。我们知道,对于具有临界度量的曲面,存在一组拉普拉斯算子的特征函数,它们定义了进入球面的最小浸入。我们旨在使用局部参数将该理论扩展到扁平线束特征截面的情况。也就是说,给定一个第一个特征值在线束上临界的度量,我们旨在使用其特征截面的升力来定义其通用覆盖在球面中的最小浸入,并更好地理解是否存在原始曲面进入球面的最小浸入。伊辛铁磁体在经典和量子极限下的热力学性质 Sophia Adams 导师:Thomas Rosenbaum 和 Daniel Silevitch 该项目旨在探测模型伊辛铁磁体 LiHoF 4 在经典和量子相变中的热力学性质。经典跃迁发生在临界温度 1.53 K 和零磁场下,而量子跃迁发生在零温度极限下 50 kOe 量级的临界横向磁场下。我们将使用比热数据来比较两个跃迁的临界指数及其之间的交叉。 一种使用基于分类器的生成器生成和预筛选蛋白质以确定结合亲和力的新方法 Victoria Adams 导师:Matt Thomson 和 Alec Lourenco 由于当前方法筛选蛋白质结合功效的速度和规模,测试新的工程结合蛋白设计非常无效。定量而不是定性筛选新蛋白质将进一步提高效率。 Thomson 实验室开发了一种高通量筛选方法,用于收集有关结合蛋白的信息并实现蛋白质设计。在我的项目中,我致力于开发一种使用蛋白质语言模型预筛选生成蛋白质的新方法。应用现有的蛋白质大型语言模型 (pLLM),例如进化尺度模型 (ESM) 和 AlphaFold 2 & 3,我正在研究一种生成蛋白质然后预筛选其结合亲和力的方法。我还有机会学习如何使用实验室的高通量筛选分析来实验性地测试蛋白质设计。到目前为止,我还没有完全开发的方法/模型,但我有一个需要微调的基本分类器,并且需要一个仍需要指定最佳参数的生成器。我希望能够完成这些编程改进,并可能能够在夏季结束前通过应用高通量筛选来测试它们。来自路径积分的时间类纠缠 Zofia Adamska 导师:John Preskill 和 Alexey Milekhin 大多数量子力学形式主义都从不同的角度来看待空间和时间,这从相对论物理学的角度来看似乎是不自然的。为了解决这种不对称性,我们提出了一种时空密度矩阵的新定义,该定义源自路径积分方法,以更好地分析时空中的量子信息。我们的动机基于相对论量子场论中的观察,其中该密度矩阵的 Renyi 熵与通过从空间类分离到时间类分离的解析延续得出的结果完全一致。我们演示了如何使用这个密度矩阵来限制时空相关函数,并表明我们的界限比其他方法更紧并且遵循 Lieb-Robinson 界限。此外,我们在量子计算机上测试了这个时空密度矩阵对单量子比特系统的预测。使用我们的方法计算的时空纠缠构成了热化的新探针,并且可以为选择用于量子多体系统时间演化的有效张量网络假设提供启示。使用合成细胞建立病毒宿主相互作用的最小模型 Layla Adeli 导师:Richard Murray 和 Zach Martinez 利用最小模型研究合成细胞病毒感染的潜力使其成为研究尚未得到充分研究的病原体的首选。为了设计 PhiX174 噬菌体的合成宿主,我们尝试将 PhiX174 识别的脂多糖 (LPS) 整合到脂质体膜中,以潜在地封装无细胞转录、翻译和复制系统 (PURE Rep)。此外,设计为在脂质体内由 PhiX174 基因触发时发出荧光的立足点开关可以检测 PhiX174 基因组的 DNA 转录——我们目前的工作包括设计一种具有高效性的开关。我们已经成功生产出脂质体,并正在努力整合检测机制我们在量子计算机上测试该时空密度矩阵对单量子比特系统的预测。使用我们的方法计算的时空纠缠构成了一种新的热化探测,可以为选择一种有效的张量网络假设来研究量子多体系统的时间演化。使用合成细胞建立病毒宿主相互作用的最小模型 Layla Adeli 导师:Richard Murray 和 Zach Martinez 利用最小模型研究合成细胞病毒感染的潜力使合成细胞成为研究尚未得到充分研究的病原体的首选。为了设计 PhiX174 噬菌体的合成宿主,我们尝试将 PhiX174 识别的脂多糖 (LPS) 整合到脂质体膜中,以潜在地封装无细胞的转录、翻译和复制系统 (PURE Rep)。此外,当脂质体中的 PhiX174 基因触发时,设计为发出荧光的立足点开关可以检测 PhiX174 基因组的 DNA 转录——我们的工作目前包括设计一种具有高效性的立足点开关。我们已经成功生产出脂质体,并正在努力整合检测机制我们在量子计算机上测试该时空密度矩阵对单量子比特系统的预测。使用我们的方法计算的时空纠缠构成了一种新的热化探测,可以为选择一种有效的张量网络假设来研究量子多体系统的时间演化。使用合成细胞建立病毒宿主相互作用的最小模型 Layla Adeli 导师:Richard Murray 和 Zach Martinez 利用最小模型研究合成细胞病毒感染的潜力使合成细胞成为研究尚未得到充分研究的病原体的首选。为了设计 PhiX174 噬菌体的合成宿主,我们尝试将 PhiX174 识别的脂多糖 (LPS) 整合到脂质体膜中,以潜在地封装无细胞的转录、翻译和复制系统 (PURE Rep)。此外,当脂质体中的 PhiX174 基因触发时,设计为发出荧光的立足点开关可以检测 PhiX174 基因组的 DNA 转录——我们的工作目前包括设计一种具有高效性的立足点开关。我们已经成功生产出脂质体,并正在努力整合检测机制

加速药物开发的新“燃料”
人工智能 (AI) 已经改变了医疗保健,从诊断和治疗到医疗服务管理,当然还有制药制造。人工智能在生物制药行业的应用已经在 2020 年产生了近 7 亿美元的全球市场价值,预计到 2025 年将大幅增长至近 30 亿美元,到不远的 2030 年将达到 90 亿美元 [1]。但是,这个被大肆宣传的人工智能概念是什么,以及它如何应用于药物开发领域,需要讨论。虽然没有明确的定义,但从广义上讲,人工智能渴望使机器获得类似人类的能力,例如通过示例学习、适应环境和决策 [2]。它主要涉及“摄取”任何类型的输入数据的算法(生物信号、医学图像和基因序列都在发挥作用),学习识别其中的常见模式,最后主要利用这些知识根据它们的相似性对它们进行聚类(这一领域称为“无监督学习”)或接受识别其类别的训练(所谓的“标签”或“类别”),以便能够对新的数据样本进行分类(这一领域称为“监督学习”)。深入研究人工智能的“内部工作原理”,存在多种方法可以执行这些任务,从更传统的机器学习(ML)到更先进和新颖的深度学习(DL)子领域,包括复杂且计算量大的算法,通常应用于大量数据,以便得出结论并以极高的准确性做出决策。AI 模型从数据中“自行”学习的基本特性,加上其针对特定任务的架构适应性,赋予了它们复杂的功能(推理、知识提取、最优解搜索),使其适用于药物制造的各种程序,从药物发现和开发到临床测试、扩大生产和质量控制 [3]。高效、安全的化合物输送一直是传统药物制造的“致命弱点” [4]。开发新药物的经济和时间成本,其中大多数在测试期间被认定为不合格,给行业带来了严重的“痛苦”,而 AI 可以缓解这种痛苦。然而,药物发现和设计并不是 AI 升级的唯一领域。一种新药的测试从开始到获批可能要花 10 多年的时间 [9],因此人工智能在加速此类程序方面的关键作用显而易见。通过利用与病理生理机制目标和候选化合物特性相关的大量数字化数据(“组学”和来自相关数据库的数据),以及来自类似化合物临床试验的效率和安全性信息,AI可以巧妙地“混合”这些“大数据”来预测手头药物的特性和相互作用,这一过程通常称为计算机实验[5]。这种先进的计算技术可以升级药物发现和新颖设计的许多关键过程,包括预测3D蛋白质结构,以谷歌的“AlphaFold” [6]为突出例子,识别针对疾病特异性靶标的生物活性配体[7],以及寻找新物质的有效合成途径[8]。临床试验如此耗时并损害该领域的投资有两个基本原因:患者纳入不理想以及对预期和不良反应的监测不完整。人们已经努力解决这两个问题。IBM 开发了一个系统,该系统利用大量患者的过往病历和临床数据,为详细的患者匹配提出最佳策略,从而避免招募失败、退出风险和设计动力不足 [10]。还有其他方法可以在早期测试阶段准确预测不良反应,从而最大限度地降低进行可能失败的试验的风险 [11]。此外,先进的人工智能计算机视觉在质量控制中发挥着重要作用,为此类技术的应用增加了价值。通过提供大量相关的视觉示例来训练人工智能模型检测有缺陷的产品或批次,人工智能可以在生产线进入市场之前有效地发现生产线中存在的故障 [12]。最后,药品制造的“物流”也是一个可以提高生产效率和可扩展性的领域。人工智能可用于分析生产流程的步骤(材料的生产、储存和运输,以及相关的成本和时间要求),将这些信息与市场需求数据相结合,并为生产计划提出最佳解决方案 [13]。所有这些子域集成都揭示了人工智能在生物制药行业当前的适用性和未来潜力。然而,这并不意味着这些方法可以摆脱与大规模人工智能解决方案相关的典型瓶颈:数据稀疏、硬件不足和缺乏专业知识。除了数据需求之外,先进的技术基础设施也是实现大型企业产生了大量无价的数据,这些数据可能会推动“数据饥渴型”人工智能方法的发展,但它们在很大程度上保持着专有性,并拒绝共享。尽管有鼓励数据开放的积极举措,但相关社区的心态在这方面还远未成熟 [14]。