XiaoMi-AI文件搜索系统
World File Search SystemAlphabet

2 1. 关于计算机 练习 1. 勾选(✓)正确的...
(iii) 箭头键 2. 在正确语句中写“ T ”,在错误语句中写“ F ”: 答:a. Enter 键用于将光标移动到下一行。 :[ T ] b. Page Up 键将页面上移。 :[ T ] c. Delete 键用于删除光标左侧的字母。 :[ F ] d. Back Space 键删除光标右侧的字符。 :[ F ] e. Caps Lock 键用于输入大写或小写字母。 :[ T ] 3. 填空: 答:a. 键盘上有许多键,它们的作用不同。 b. Delete 键用于删除光标右侧的字母。 c. 空格键是键盘上最长的键。 d. 键盘通常称为 QUERTY 键盘。 e. Enter 键也称为 Return 键。 4. 写出以下键的功能: 答:a. Caps Lock 键:Caps Lock 键用于输入大写字母。按此键一次,可打开该键以输入大写字母。再次按此键可关闭该键以输入小写字母。b. 空格键:空格键是键盘上最长的键。此键用于在各种类型的数据和信息之间留出空格。数据和信息可以是字符、单词、句子和其他结构。c. Enter 键:Enter 键用于将光标移动到显示器的下一行。它也被称为回车键。d. 字母键:字母键显示从 A 到 Z 的字母。这些键帮助我们输入单词和句子。字母键共有 26 个。

第 10 章 递归网络
请注意,这些可变大小的结构可以出现在输入级别、输出级别或两者。例如,翻译问题可以看作是序列到序列的问题。输入和输出序列不必具有相同的长度。蛋白质二级结构的预测可以看作是从具有 20 个字母的字母表(每个字母代表一种天然存在的氨基酸)到具有三个字母的字母表(对应于三个主要的二级结构类别(α-螺旋、β-链和卷曲))的翻译问题。在这种特殊情况下,输入序列和输出序列具有相同的长度。在解析问题中,输入是序列,输出是树。在蛋白质接触图预测中,输入是序列,输出是矩阵,依此类推。在所有这些问题中,标签可以存在于节点上、边缘上或两者上。有机化学中的小分子可以在节点上具有与原子类型(例如 C,N,O,H)相对应的标签,也可以在边缘上具有与键类型(例如单键,双键,三键和芳香键)相对应的标签。

基于拼写的语言神经解码 BCI 系统
摘要 — 脑机接口 (BCI) 通过将神经活动直接转换成文本,消除了身体动作的需要,从而提供了一种有前途的途径。然而,现有的非侵入式 BCI 系统尚未成功覆盖整个字母表,限制了它们的实用性。在本文中,我们提出了一种新型的非侵入式基于 EEG 的 BCI 系统,该系统具有基于课程的神经拼写框架,它首先通过解码与手写相关的神经信号来识别所有 26 个字母,然后应用生成式 AI (GenAI) 来增强基于拼写的神经语言解码任务。我们的方法结合了手写的便利性和 EEG 技术的可访问性,利用先进的神经解码算法和预训练的大型语言模型 (LLM) 将 EEG 模式高精度地转换为文本。该系统展示了 GenAI 如何提高典型的基于拼写的神经语言解码任务的性能,并解决了以前方法的局限性,为有沟通障碍的个人提供了可扩展且用户友好的解决方案,从而增强了包容性的沟通选择。

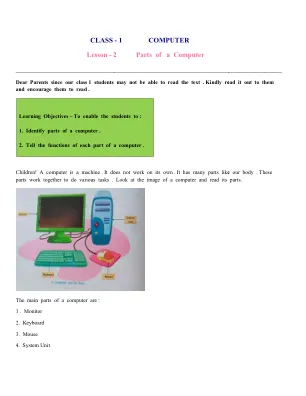
课程 - 1 计算机 - 课程 - 2
计算机也有很多部件。因此,每个部件都有自己的部件。键盘、鼠标、CPU。计算机上的显示器。键盘是显示器屏幕上的每个键都有一个字母、数字。它有两个CPU和计算机上的一些其他部件。CPU代表一台计算机。https://youtu.be/cKjlfW7iV7s

AOTG 提供与众不同的增长战略
乍一看,AOTG 的最大持股与成长型投资组合中常见的大盘股公司相同,包括 Alphabet、微软和亚马逊。但该基金的最大持股还包括高通 (QCOM) 和超微半导体 (AMD)——这些公司的年增长率为 35% 至 80%。他们每年的收入已经达到数十亿到数百亿美元,考虑到他们的盈利能力和增长率,他们的估值相对较低。按照名单往下看,还有一些独特的中型和小型股,使 AOTG 有别于其他成长型基金。其中包括 Sterling Check (STER)、Toast (TOST)、LendingClub (LC) 和 DLocal (DLO)。

讲稿
开始之前,我们先回顾一下在整个讲义中使用的古典概率论的标准符号。有很多关于概率论的优秀教科书和在线资源,比如 [Kel94; Ros10],我们推荐您参考其中任何一本以获取更多背景信息。考虑一个离散随机变量 X,其值取自某个大小为 n 的字母表 X。我们用 PX ( · ) 表示 X 的分布,用 | X | 表示 X 的字母表大小。符号 PX ( x ) 表示随机变量取特定符号 x ∈ X 的概率。当从上下文中可以清楚了解分布时,我们使用简写 px = p ( x ) = P ( X = x ) = PX ( x )。记住概率分布 PX ( · ) 由非负概率值指定很有用,即 ∀ x ∈ X , PX ( x ) ≥ 0。此外,X 应该是标准化的,这意味着 ∑ x ∈ XPX ( x ) = 1。

组合复合DNA的错误校正代码
摘要 - DNA中的DATA存储是作为档案数字数据的可能解决方案而开发的。最近,为了进一步提高基于DNA的数据存储系统的潜在能力,建议了组合复合DNA合成方法。这种方法通过利用短DNA片段试剂(称为短生物)来扩展DNA字母。短期是字母符号的构建块,每个符号由固定数量的短裤组成。因此,当读取信息时,可能缺少构成符号组成的一部分的短毛,因此无法确定符号。在本文中,我们将此类型的错误建模为一种不对称错误,并提出了可以在此设置中纠正此类错误的代码构造。我们还提供了此类错误校正代码的冗余的下限,并为我们的构造提供了明确的编码器和解码器。我们建议的误差模型也得到了对根据组合方案产生DNA的数据的分析的分析。最后,我们还提供了观察此类错误事件的概率的统计评估,这是读取深度的函数。


用于淋巴水肿和脂肪水肿鉴别诊断的生成人工智能
2023 年 5 月同一天,一位经验丰富的淋巴水肿从业者 (AM) 评估了两个品牌的生成式 AI 的反应有效性:Bard(Alphabet Inc [Google 的母公司],加利福尼亚州,版本 2.0.1)和 ChatGPT(Open AI,加利福尼亚州,版本 3.01,2023 年)。根据常见的临床知识和当前的证据基础,以主观尺度评估了反应有效性,包括无效、可能有效和有效。Bard 和 ChatGPT 都接受过大量医疗信息数据集的训练,因此能够快速访问和处理文本查询。为了进行鉴别诊断,这两个系统都可以为从业者提供基于文本输入的可能诊断列表。