XiaoMi-AI文件搜索系统
World File Search SystemAttribution

归因科学基于过程的建模方法
2025年3月11日|美国东部时间上午11点至2:15 PM(ET)目的此信息收集会议的目的是探索实现归因科学的基于物理,基于过程的建模方法的挑战和机会。本届会议将重点介绍大规模和小规模的建模挑战,需求和当前功能,以及这些量表与气候模型对归因科学的未来用途和需求之间的相互作用。

总回报影响和归因报告
重要的绩效和费用信息所有绩效信息都反映了过去的绩效,以总回报为基础,反映了分配的再投资,并且不反映股东会支付基金分配或基金股份赎回的税款的扣除。过去的表现不能保证未来的结果。投资的投资回报和本金价值将波动,因此股票的价值可能比赎回后的原始成本高或低。当前月末性能可能高于或低于引用的性能,可以在www上获得。royceinvest.com。所有绩效信息都反映了投资类结果。共享基金的服务,顾问和R类承担的年度分销费用高于投资阶级的支出。运营费用反映了该基金目前的最新招股说明书的投资类别的年度运营费用,其中包括管理费,其他费用以及收购的基金费用和费用。收购的基金费用和支出反映了基金通过对共同基金和其他投资公司的投资间接产生的费用和费用的估计金额。该基金主要投资于小型股票,这可能涉及比投资大型股票更多的风险。(请参阅招股说明书中的“基金投资者的主要风险”。)该基金的广泛多元化投资组合不能确保损益的利润或保证。(请参阅招股说明书中的“投资外国证券”。)该基金可以在外国证券(在投资时衡量)中最多投资其25%的净资产,这可能涉及美国投资中未遇到的政治,经济,货币和其他风险。关于近期市场变动和对小公司股票的未来前景的想法仅是罗伊斯投资伙伴的想法,当然,对于未来的市场变动,没有任何保证。除非先于或伴随当前招股说明书,否则该材料未授权分发。请在投资或汇款之前仔细阅读招股说明书。分销商:Royce Fund Services,LLC

人机交互中的外部和内部归因
代理是按照人类的形象设计的,无论是内部还是外部。代理的内部系统模仿人类的大脑,无论是在硬件(即神经形态计算)还是软件(即神经网络)层面。此外,代理的外观和行为是由人设计的,并基于人类数据。有时,代理的这些类似人类的品质是故意选择的,以增加其对人类用户的社会影响力,有时影响代理感知的人为因素是隐藏的。受 Blascovich 的“社会影响阈值”(Blascovich 等人,2002 年)启发,该模型旨在解释虚拟环境中拟人化实体代理的不同方法的影响,我们提出了一个新颖的框架来理解人类对代理的人类品质归因如何影响其在人机交互中的社会影响。社会影响(EIA)的外部和内部归因模型建立在沉浸式虚拟现实中代理化身的先前研究的基础上,并提供了一个将先前的社会科学理论与神经科学联系起来的框架。EIA 将代理的外部和内部归因与两个与社会影响相关的大脑网络联系起来:外部感知系统和心理化系统。关注人机交互研究的每个归因

了解社交机器人:故意归因......
作者:T Ziemke · 2023 · 被引用 12 次 — Erlbaum。Buckwalter, W., & Phelan, M. (2013)。功能和感觉机器:对主观经验的哲学概念的辩护...

联合治疗的价值归因框架
注释 (1) 包括强制性折扣 (2) 每月治疗费用(1 个月 = 4 周)基于治疗总费用除以 DoT。适应症:BRAF V600 突变阳性且无法切除的局部晚期或转移性黑色素瘤患者 资料来源:GBA;Clinicaltrials.gov;监测德勤分析 数据最初来自赛诺菲 Onco Combo 路线图 ISPOR-EU 2023,哥本哈根,小组,2023 年 11 月 13 日

调节情绪归因和操纵的理由
首先,我们不应该假设情感计算技术将按计划工作。在最基本的层面上,他们可能会误解人们,并将一个人的行为归因于另一个人。即使他们能够始终如一地识别人和面孔,机器也可能失败。心理学研究人员已经证明,面部和表情不一定巧妙地绘制到特定的特征和情感上,更不用说涉及到参与或侵略检测中更广泛的精神状态了。正如丽莎·巴雷特(Lisa Barrett)和她的同事所报告的那样:“同一情感类别的实例既不是通过一组普通的面部运动来可靠地表达的,也不是从一组普通的面部运动中表达出来的(Barrett等人。2019:3),因此面部的交流能力受到限制。误解的危险是明确的,并且在通过面部分析量化参与的努力中存在明显的危险。

北极熔体异常的特征归因
我们工作的重点是改善气候模型中异常的解释性,并促进我们对北极熔体动态的理解。北极和南极冰盖正在迅速融化并增加了淡水径流,这显着导致了全球海平面上升。了解在这些地区驱动融雪的机制至关重要。ERA5是极地气候研究中广泛使用的重新分析数据集,可提供广泛的气候变量和全球数据同化。但是,其融雪模型采用了一种能量不平衡的方法,可能会过度简化表面熔体的复杂性。相反,冰川能量和质量平衡(GEMB)模型结合了其他物理过程,例如积雪,FIRN致密化和融化液化/重新冻结,提供了表面熔体动力学的更详细的表示。在这项研究中,我们专注于分析格陵兰冰盖的表面融雪材料,并使用ERA5和GEMB模型中异常熔体事件的特征归因。我们提出了一种新型的无监督归因方法,利用反对解释方法来分析ERA5和GEMB中检测到的异常。我们的异常检测结果通过模仿地面真实数据进行验证,并针对既定的特征排名方法进行了评估,包括XGBoost,Shapley值和随机森林。我们的归因框架标识了每种模型背后的物理和气候特征驱动熔体异常的特征。这些发现证明了我们的归因方法在增强气候模型中异常的解释性并促进我们对北极熔体动力学的理解方面的实用性。
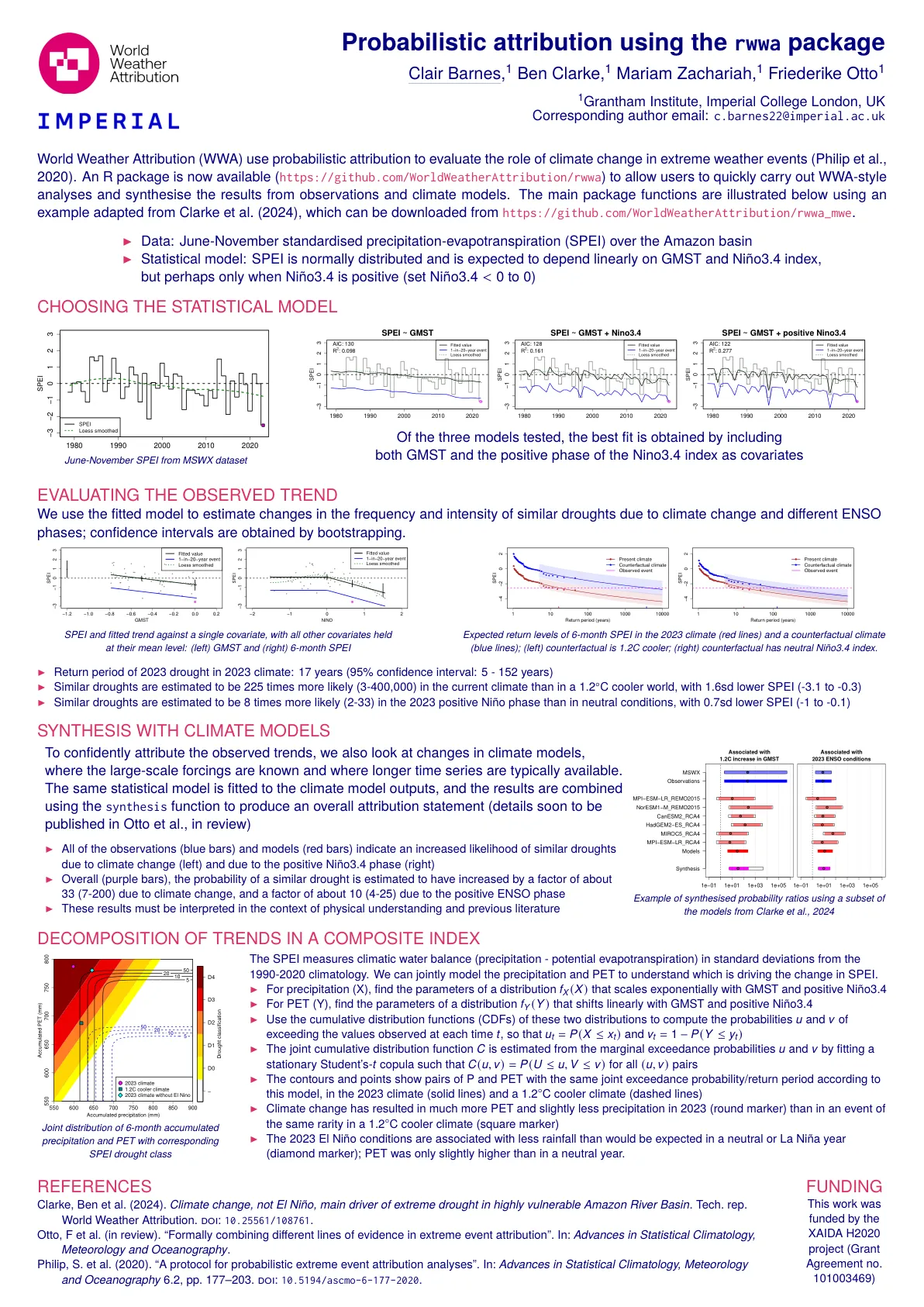
使用RWWA软件包
▶ For precipitation (X), find the parameters of a distribution f X ( X ) that scales exponentially with GMST and positive Niño3.4 ▶ For PET (Y), find the parameters of a distribution f Y ( Y ) that shifts linearly with GMST and positive Niño3.4 ▶ Use the cumulative distribution functions (CDFs) of these two distributions to compute the probabilities u and v of exceeding the values在每个时间t观察到,因此u t = p(x≤xt)和v t = 1 - p(y≤yy t)▶估计关节累积分布函数C是从边际超过u和v估计的,c(u,v)= p(u,v)p c(u≤u,v)p c(u,v)p pocula u和v cove u and v fute u和v copula u and v futue(uf)p fute(uf)p futifus的u和v fut的u和v。在2023年气候(实线)和1.2℃的气候变化(虚线)中,具有相同关节超出概率/回报期的PET▶气候变化的PET较少于2023年的PET和降水量稍微降低了(圆形标记)(圆形标记)比在1.2°C Cooler气候下的少量(较少的情况下)在2023年的情况下(圆形标记)比20°C cooler cool ate ni ni ni ni sarecrimate Marker(square Marker)在square Marker中相同预计在中立或拉尼娜年(钻石标记);宠物仅比中立的一年略高。

基于 AI 的人工制品语音功能对代理的作用 基于 AI 的人工制品语音功能对代理归因的作用
私人、组织和社会领域中基于人工智能 (AI) 的人工制品的普及和日益复杂化正在改变人类与机器的交互方式。例如,关于人类感知基于 AI 的人工制品的方式的理论对于理解为什么以及在多大程度上人类认为这些人工制品能够胜任决策至关重要,但传统上却采取了与模态无关的观点。在本文中,我们理论化了一种特殊的交互情况,即基于语音的与基于 AI 的人工制品的交互。我们认为,在自然语言处理的不断进步的推动下,此类人工制品的能力和感知自然性促使用户认为人工制品能够以目标为导向的方式自主行动。我们表明,人工制品的语音能力与用户的代理归因之间存在正向直接关系,最终掩盖了人工制品的真实性质和能力。这种关系进一步受到工件的实际代理、不确定性和用户特征的影响。

人工智能归因知识在艺术品评估中的作用
摘要 越来越多的艺术品由机器通过算法创作,几乎不需要人类的输入。然而,人们对机器生成的艺术品的态度和评价知之甚少。当前的研究调查了(a)个人是否能够准确区分人造艺术品和人工智能生成的艺术品,以及(b)归因知识(即有关谁创作了内容的信息)在他们评价和接受艺术品中的作用。数据是使用 Amazon Turk 样本从在 Qualtrics 上设计的两个调查实验中收集的。研究结果表明,个人无法准确识别人工智能生成的艺术品,他们很可能将具象艺术与人类联系起来,将抽象艺术与机器联系起来。归因知识和艺术品类型(具象与抽象)之间也存在对购买意向和艺术品评价的相互作用。