XiaoMi-AI文件搜索系统
World File Search SystemAvatar

2023 年年度报告
让用户沉浸在虚拟现实环境中,让他们扮演列奥纳多·达·芬奇的化身,然后要求他们进行创造力练习,与对照组相比,你会看到结果有显著改善。这是雷恩大学 Inria 中心和拉瓦尔研究所(位于法国拉瓦尔的一所工程学院)进行的一项实验得出的令人惊讶的结论。Hybrid 项目团队及其合作伙伴设计了这个有趣的实验,其中包括列奥纳多·达·芬奇的化身、他的工作室、一套练习所需的物品(一个地球仪、一块黑板和一把阳伞)和一个原始的“虚拟化身”协议。研究人员将这种现象称为“普罗透斯效应”,扮演一个人物——在这里是列奥纳多·达·芬奇——会对人们的行为和表现水平产生影响,这在培训、健康(康复、残疾等)和设计等领域代表着巨大的机遇。

带有分层头发和衣服的仿真准备头像
1。引言创建照片现实和动态的人类化身具有广泛的应用,包括虚拟试验,电影和游戏制作,虚拟助手,AR/VR以及远程介绍。传统上,此过程需要培训,这使得普通用户无法访问。最近,基础扩散模型的进步加速了旨在使3D Human Avatar创建民主化的研究工作,从而可以通过文本[16、46、51、88]或图像[39]易于用户控制。早期的3D人头像创作的方法将头发,身体和衣服作为单层表示,因此由于其纠缠的几何形状,很难独立模拟或编辑每个区域。为了解决这一限制,重新制作的工作使用了分层结构来分别反映身体,服装或头发[27,36,82,96]。,这些方法中的许多方法都依赖于nerf [58]等隐性代表来定义服装或毛发地理。尽管隐式表示有助于从基础扩散模型中利用先验知识,但它们在现有模拟器中进行动画挑战,这是由于身体运动而引起的头发和服装的现实运动。结果,这些方法难以生产动画时看起来很现实的化身。因此,出现了一个自然的问题:我们可以设计3D化身生成管道,该管道可以利用图像扩散模型中的丰富的先验知识,同时与现有的模拟管道兼容?解决此问题的关键挑战在于连接当前模拟器和文本驱动的头像生成管道中使用的不同表示。前者通常会重新使用平滑清洁的非紧密网格或特定设计的头发链,其拓扑是可以优化的,并且很难约束。十大的后者采用隐式表示(例如NERF [58]或SDF [83]),尽管它们可通过嘈杂的监督信号来优化来自扩散模型的嘈杂监督信号,但不能轻易地转换为适合模拟的开放网格或发束。为了解决这些问题,我们提出了一个新颖的框架Simavatar,该框架从文本提示中生成了3D人体化身,可以很容易地通过现有的头发和服装模拟器来动画。关键思想是为不同的人类部位(例如头发,身体和服装)采用合适的代表,并利用图像扩散模型和模拟器的先验知识。为此,我们提出了使用头发束代表人头发,身体和饰物的几何形状,参数身体模型SMPL [55],
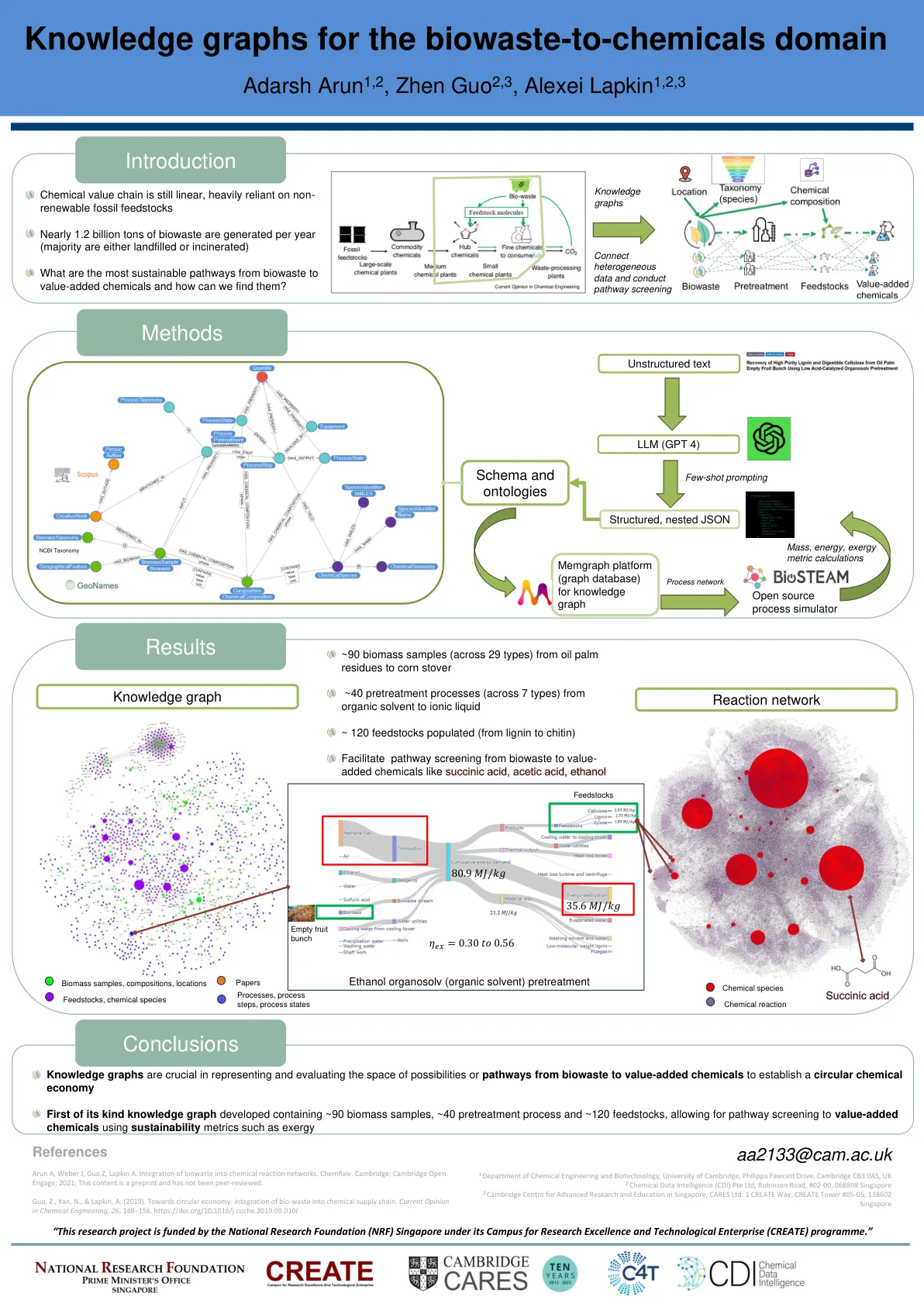
Adarsh Arun、Zhen Guo、Alexei Lapkin - 剑桥 CARES
IRP4 第 1 阶段,也称为综合化学和电力系统运行 (ICESO),研究了如何最大限度地减少裕廊岛化工厂电力供应产生的二氧化碳排放量。这项研究进行了 5 年,于 2018 年 10 月结束。该项目极大地推动了工业园区电力系统近乎实时地控制,以提高效率和减少二氧化碳排放,同时保持供电安全。这项工作为 J-Park 模拟器奠定了基础,后来成为 World Avatar。

使用计算机视觉和AR
许多产品(例如照片编辑软件和AI图像生成器)可以实现虚拟的尝试。然而,他们有一个静态的共同问题。也就是说,必须重新录制和重新加工一张新照片才能查看不同的姿势或角度。也有类似AvatorCloud的产品可以创建用户的头像,并允许用户更改服装(Nexr,n.d。)。但是,化身可能不够现实,无法完全证明衣服,并且姿势也可能仅限于预定义的模板。一些像Farfetch这样的品牌还使用Snapchat(n.d. Farfetch)上的增强现实(AR)发布了实时虚拟试用功能,但是这些选择仅限于他们自己的产品或预定义的敷料。一个人可能需要为不同的品牌和类别的多个应用程序或服务。因此,需要一个更通用的应用程序,它既不是静态的,也不是品牌独家的应用程序来解决上述问题。

Tenance的火车 div>
神经辐射场(NERF)。•通过文本提示引入了一种针对阿凡达自定义的新文本驱动的模型训练方法。•开发了一种基于Web的应用程序,用于生成个性化的3D化身和风格化的肖像。•在工程技术机构香港

数字身份,隐私安全及其在Metaverse中的法律保障措施
摘要元元是现实世界的数字化,并由大数据,AI,5G,云计算,区块链,加密算法,感知技术,数字双引擎,虚拟引擎和其他技术与人类行为和数字标识中的人类行为和思想相互作用。破解阿凡达带来的信任问题取决于使用数字身份进入元评估的个人的隐私安全和身份验证技术。要完成对化身的个人统治,元用户需要隐私数据喂食和情感投影。他们必须配备专有算法,以处理和分析自适应交互中生成的复杂数据,这挑战了元视频中用户数据的隐私安全性。区分个人身份生成中不同的识别剂的重要性,同时对数据处理水平强加不同的行为调节要求可以更好地平衡个人隐私安全性与数字身份保护与元经文中数据利用之间的关系。响应数字身份问题,需要建立一个统一的数字身份身份验证系统来获得社会的一般信任。此外,可以将人格权的回复应用于非法侵犯数字身份和隐私安全的情况。

利用无线感知引导人工智能生成的数字内容
摘要 人工智能(AI)的进步和各种训练数据的激增促进了人工智能生成内容(AIGC)的发展。尽管效率很高,但人工智能模型固有的不稳定性对创建用户特定内容提出了挑战,尤其是在为用户创建虚拟形象时。为了解决这个问题,本文将无线感知(WP)与AIGC相结合,并引入了一个统一框架WP-AIGC,该框架利用WP获得的用户骨架来指导AIGC,从而生成与用户实际姿势相符的虚拟形象。具体而言,WP-AIGC首先采用一种新颖的多尺度感知技术来感知物理世界中的姿势并构建用户骨架。然后,将骨架和用户的要求传达给AIGC,从而指导虚拟形象的创建。此外,WP-AIGC可以根据用户反馈调整分配给感知和AIGC的计算资源,从而优化服务。实验结果验证了该服务的有效性。在有限的计算资源下,当四条链路参与感知时,WP-AIGC 可实现最佳 QoS 3.75。

“我做得更好”:通过脑机接口检查虚拟现实中的具身化对二元运动想象任务中的主体感的影响
基于运动想象的脑机接口 (MI-BCI) 已被提议作为一种中风康复手段,它与虚拟现实相结合,可以将基于游戏的互动引入康复中。然而,MI-BCI 的控制可能难以获得,用户可能会面临糟糕的表现,这会让他们感到沮丧,并可能影响他们使用该技术的积极性。通过增加用户对系统的代理感,可以减少积极性的下降。本研究的目的是了解虚拟现实中描绘的手的化身(所有权)是否可以增强代理感,从而减少 MI-BCI 任务中的挫败感。22 名健康参与者参加了一项受试者内研究,在两种不同的化身体验中比较了他们的代理感:1) 化身手(与身体),或 2) 抽象块。两种表征都以相似的运动闭合以实现空间一致性,并因此弹出气球。手/块通过在线 MI-BCI 控制。每种情况都包括 30 次 MI 激活化身手/块的试验。在每种情况之后,一份问卷调查了参与者的自主感、所有权和挫败感。之后,进行了一次半结构化访谈,参与者详细说明了他们的评分。这两种情况都支持相似水平的 MI-BCI 性能。观察到所有权和自主性之间的显著相关性(r = 0.47,p = 0.001)。正如预期的那样,虚拟手比积木产生更高的所有权。在控制性能时,所有权增加了自主感。总之,基于 BCI 的康复应用程序的设计者可以利用拟人化虚拟形象来对训练过的肢体进行视觉映射,以提高所有权。虽然不能减少挫败感,但只要 BCI 性能足够好,所有权就可以提高感知到的自主性。在未来的研究中,应该在中风患者中验证这些结果,因为他们对自主性和所有权的感知可能与健全用户不同。

磁铁妖精击中公共服务器
hxxp [: //] 91.92.240 [。] 113/auth.js,hxxp [: //] 91.92.240 [。] 113/login.cgi,hxxp [: //] 91.92.240 [。] 113/aparche2,hxxp [: //] 91.92.240 [。] 113/agent,hxxp [: //] 45.9.149 [。] 215/aparche2,hxxp [: //] 45.9.149 [。] 215/agent,hxxp [: //] 94.156.71 [。] 115/lxrt,hxxp [: //] 94.156.71 [。] 115/agent,hxxp [: //] 94.156.71 [。] 115/instali.ps1,hxxp [: //] 94.156.71 [。] 115/ligocert.dat,hxxp [: //] 94.156.71 [。] 115/angel.dat,hxxp [://] 94.156.71 [。] 115/windows.xml,hxxp [: //] 94.156.71 [。] 115/instal1.ps1,hxxp [: //] 94.156.71 [。] 115/taborenance.ps1,hxxp [: //] 94.156.71 [。] 115/baba.dat,hxxp [: //] oncloud-analytics [。] com/files/mg/elf/rt1.50.png,hxxp [://] cloudflareaddons [。] com/andsets/img/image_slider15.1.png,www.fernandestechnical [。] com/pub/health_check.php,biondocenere [。] com/pub/health_check.php,www.miltonhouse [。] NL/PUB/OPT/PROCESSOR.PHP,HXXPS [://] TERHATS [。]在/pub/Media/avatar/223sam.jpg

在儿童玛尼亚展览中的实施和互动
13 Steur,“摄影游戏或肉体中的游戏:通过将摄影主题调整为视频播放的现象来抓住Celeste,”89。14黑色,“为什么我可以看到我的头像?在第三人称视频游戏中体现了视觉参与,”190。15克里克,“游戏主体:迈向当代视频游戏的现象学”,259。16 Sobchack,“屏幕的场景”,108。同上,93。18克里克,261。