XiaoMi-AI文件搜索系统
World File Search SystemBERT

Codonbert:使用跨注意机制量子量身定制的基于BERT的架构
1 changchun兽医研究所,中国农业科学院,州病原体与生物能力的国家主要实验室,吉林省预防与控制的主要实验室中国武汉340000武汉技术与商学院人工智能,卫生服务和输血医学研究所,北京100850,中国卫生服务和输血医学研究所。信息科学与技术学院,东北师范大学,编号2555 Jingyue Street,Changchun,Jilin Province 130117,中国。 电子邮件:sunpp567@nenu.edu.cn(P.S. ) );中国农业科学院的长春兽医研究所, 中国约林街573号Yujinxiang街130122。 电子邮件:hottank3210@126.com(B.Z. );卫生服务和输血研究所,编号 27 Taiping Road,北京100850,中国。 电子邮件:niming@bmi.ac.cn(M.N。) †这些作者对这项工作也同样贡献了第一作者。 副编辑:Inanc Birol2555 Jingyue Street,Changchun,Jilin Province 130117,中国。电子邮件:sunpp567@nenu.edu.cn(P.S. ) );中国农业科学院的长春兽医研究所, 中国约林街573号Yujinxiang街130122。 电子邮件:hottank3210@126.com(B.Z. );卫生服务和输血研究所,编号 27 Taiping Road,北京100850,中国。 电子邮件:niming@bmi.ac.cn(M.N。) †这些作者对这项工作也同样贡献了第一作者。 副编辑:Inanc Birol电子邮件:sunpp567@nenu.edu.cn(P.S.);中国农业科学院的长春兽医研究所,中国约林街573号Yujinxiang街130122。 电子邮件:hottank3210@126.com(B.Z. );卫生服务和输血研究所,编号 27 Taiping Road,北京100850,中国。 电子邮件:niming@bmi.ac.cn(M.N。) †这些作者对这项工作也同样贡献了第一作者。 副编辑:Inanc Birol中国约林街573号Yujinxiang街130122。电子邮件:hottank3210@126.com(B.Z. );卫生服务和输血研究所,编号 27 Taiping Road,北京100850,中国。 电子邮件:niming@bmi.ac.cn(M.N。) †这些作者对这项工作也同样贡献了第一作者。 副编辑:Inanc Birol电子邮件:hottank3210@126.com(B.Z.);卫生服务和输血研究所,编号27 Taiping Road,北京100850,中国。 电子邮件:niming@bmi.ac.cn(M.N。) †这些作者对这项工作也同样贡献了第一作者。 副编辑:Inanc Birol27 Taiping Road,北京100850,中国。电子邮件:niming@bmi.ac.cn(M.N。) †这些作者对这项工作也同样贡献了第一作者。 副编辑:Inanc Birol电子邮件:niming@bmi.ac.cn(M.N。)†这些作者对这项工作也同样贡献了第一作者。副编辑:Inanc Birol

dti-bert:基于BERT和深度学习方法识别细胞网络中的药物目标相互作用
大脑对脑同步的研究在脑部计算机界面(BCI)研究中具有新兴的应用,为使用众多神经记录技术提供了对相互作用人类大脑的神经基础的宝贵见解。该区域允许通过评估执行指定任务的一组人之间的神经同步来探索大脑动力学的共同点。越来越多的关于大脑对脑同步的出版物启发了作者使用PRISMA协议进行系统的审查,以便未来的研究人员可以全面了解范式,方法论,翻译算法以及在脑对脑部同步研究领域的挑战。本评论已通过指定的搜索字符串进行了系统的搜索,并根据预先规定的资格标准选择了一些文章。审查的发现表明,大多数文章都遵循社会心理学范式,而36%的选定研究中有36%的研究在认知神经科学中应用。确定神经连通性的最应用方法是在EEG研究中使用相锁定值(PLV)的连贯度量,然后在所有FNIRS研究中进行小波变换相干性(WTC)。尽管大多数实验作为其设置的一部分具有控制实验,但少量实施了算法控制,并且只有一项研究进行了介入或刺激诱导的控制实验,以限制虚假同步。因此,据作者所知,这项系统的审查仅有助于评估脑对脑之间同步的范围和技术进步,以使该学科在遥远的未来中产生更有效的研究成果。

NVIDIA AI 企业试用
图 1-1。NVIDIA AI Enterprise 软件套件......................................................................6 图 1-2。数据科学工作流程示例 ......................................................................................6 图 3-1。NVIDIA AI Enterprise 试用 - Ubuntu 桌面版 ........................................... 10 图 4-1。BERT 问题/答案 ............................................................................................. 11 图 4-2。BERT 模型示例段落 ...................................................................................... 12 图 4-3。BERT 演示提供的问题 ...................................................................................... 12 图 4-4。BERT 演示自定义输入 ...................................................................................... 13 图 4-5。出租车费演示概述 ............................................................................................. 13 图 4-6。出租车费用数据示例 ................................................................................................ 14 图 4-7。训练和实际时间 ................................................................................................ 14 图 4-8。出租车费用预测与实际数据的比较 ........................................................................ 15

blgav:基于BERT和BILSTM笔记本PAN的生成AI作者验证模型,clef 2024
命名实体识别是一项信息提取任务,旨在识别文本中的命名实体并将其分类为预定义的类别。嵌套的命名实体识别涉及检测外部实体和内部实体。Bionne竞争[1]是CLEF 2024 Bioasq Lab [2]的一部分,重点是从生物医学文本中提取嵌套的实体。嵌套命名实体类型包括解剖(解剖学),化学物质(化学),疾病(DISO),生理学(物理),科学发现(发现),受伤或中毒损害(伤害_poisoning),实验室程序(LABPROC)和医疗设备(设备)[3]。挑战提供俄罗斯,英语和双语曲目。对于英语曲目,组织者提供了一个带有50个记录和一个带有50个记录的验证的培训集。每个记录都包含一个文本,即PubMed摘要,以及以Brat格式注释的实体列表,其本文中实体的起始和结束位置。在测试阶段,组织者发布了一个带有154个摘要和346个额外文件的测试集,总共有500个记录。我们的团队专注于Bionne English Track。我们的系统使用大型语言模型(特别是Mixtral 8x7b指示模型[4])和一个生物医学模型来查找文章中的实体。然后,系统使用统一的医学语言系统(UMLS)语义类型来过滤和汇总实体。实现可以在GitHub 1上找到。

利用人工智能实现 IT 支出透明度
BERT:一种多功能的 AI 工具,可自动执行 TBM 分类法分类 从历史上看,计算机很难“理解”文本形式的语言。虽然这些机器可以非常有效地收集、存储和读取文本输入,但它们缺乏基本的语言背景或意图。幸运的是,自然语言处理 (NLP) 和自然语言理解 (NLU) 可以帮助完成这项任务。这种语言学、统计学、机器学习和人工智能的结合过程不仅可以帮助计算机“理解”人类语言,还可以破译和解释特定文本的意图。 BERT 体现了 NLP 和 NLU 的最新进展,它由 Google 开发并向公众开源。 BERT 依赖于 Transformer 模型架构 [3] 的编码器部分,该架构也是由 Google 开发的。它使用自注意力机制来捕捉单词的语义。该机制使用优雅而简单的线性代数运算来建立单词(或在 BERT 上下文中为标记)之间具有不同权重的关系。权重决定了标记之间的接近度并捕获序列的上下文。

Clef 2024 Joker任务2:根据类型和技术使用BERT和随机森林分类器进行幽默分类
抽象的自主机器人用于以人为中心的环境(例如办公室,餐馆,医院和私人住宅)进行协作和合作的任务。这些活动要求机器人以社会可接受的方式吸引人们,即使他们犯了错误。由于技术或环境局限性(例如多模态观测值不匹配),机器人会导致通知失败。虽然无法完全避免这些错误,但仍然有必要最大程度地减少它们。在本文中,我们希望通过使用对比言语和非语言的多个提示来使用讽刺,以允许机器人隐藏其相互作用信号的不确定性。结果表明两种态度之间的某些差异,例如机器人的独立性和自信。

张量感知能量核算
随着由深度学习 (DL) 支持的人工智能 (AI) 应用的快速增长,这些应用的能源效率对可持续性的影响越来越大。我们推出了 Smaragdine,一种使用 TensorFlow 实现的基于张量的 DL 程序的新型能源核算系统。Smaragdine 的核心是一种新颖的白盒能源核算方法:Smaragdine 能够感知 DL 程序的内部结构,我们称之为张量感知能源核算。借助 Smaragdine,DL 程序的能耗可以分解为与其逻辑层次分解结构一致的单元。我们应用 Smaragdine 来了解 BERT(最广泛使用的语言模型之一)的能源行为。Smaragdine 能够逐层、逐张地识别 BERT 中能耗/功耗最高的组件。此外,我们还对 Smaragdine 如何支持下游工具链构建进行了两个案例研究,一个是关于 BERT 超参数调整的比较能量影响,另一个是关于 BERT 进化到下一代 ALBERT 时的能量行为演变。

测量云实例中人工智能的碳强度
模型 BERT BERT 6B Dense Dense Dense ViT ViT ViT ViT ViT 微调预训练 Transf。 121 169 201 微型 小型基础 大型 巨型 GPU 4 · V100 8 · V100 256 · A100 1 · P40 1 · P40 1 · P40 1 · V100 1 · V100 1 · V100 4 · V100 4 · V100 小时 6 36 192 0.3 0.3 0.4 19 19 21 90 216 千瓦时 3.1 37.3 13,812.4 0.02 0.03 0.04 1.7 2.2 4.7 93.3 237.6 表 2. 对于我们分析的 11 个模型:GPU 的类型、该类型的 GPU 数量、小时数以及所用的能量(千瓦时)。例如,我们的 BERT 语言建模 (BERT LM) 实验使用了 8 个 V100 GPU,持续了 36 个小时,总共使用了 37.3 千瓦时。我们注意到,60 亿参数转换器的训练运行时间仅为训练完成时间的约 13%,我们估计完整的训练运行将消耗约 103,593 千瓦时。
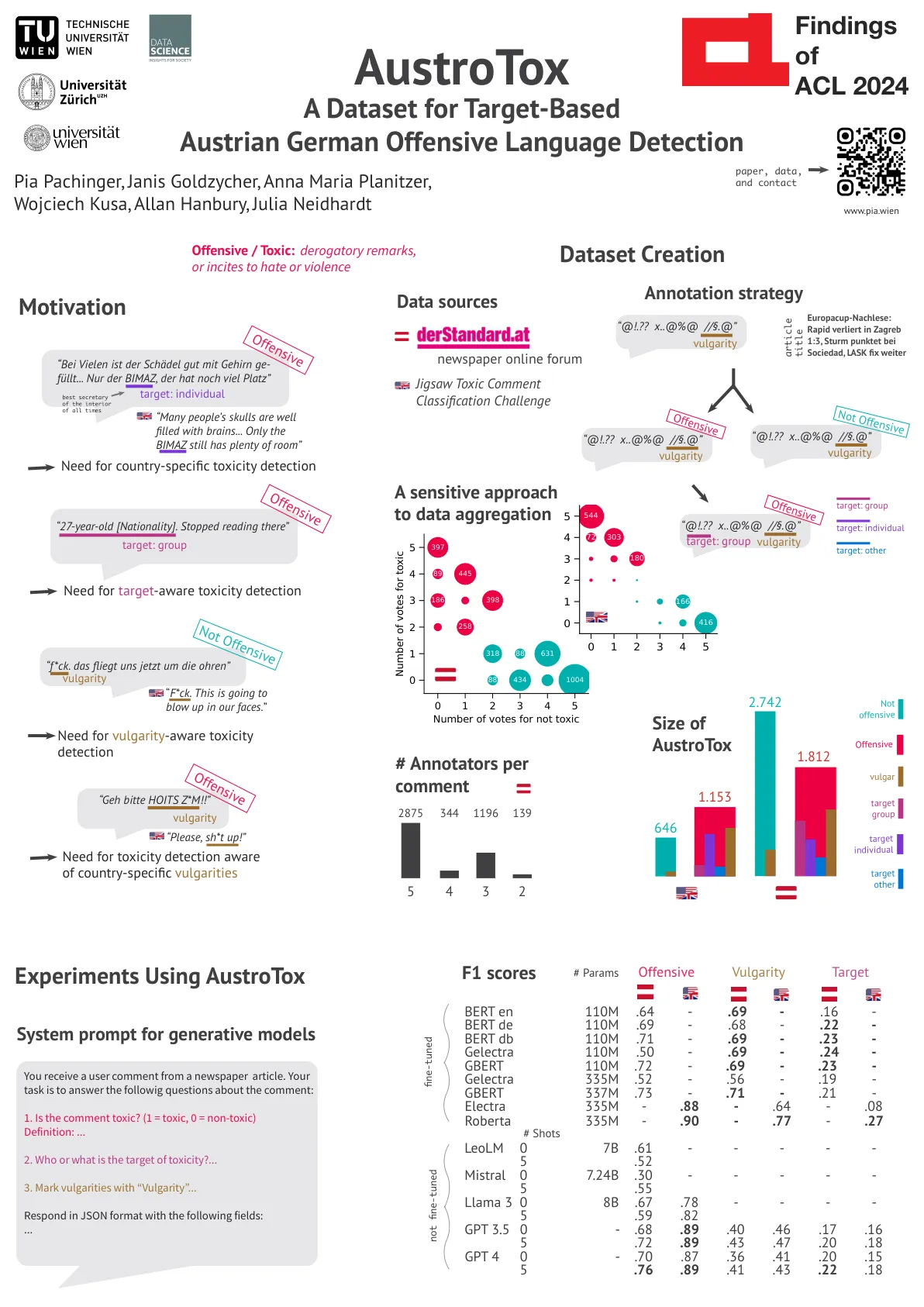
ACL 2024的发现-Pia Pachinger
BERT en 110M .64 - .69 - .16 - BERT de 110M .69 - .68 - .22 - BERT db 110M .71 - .69 - .23 - Gelectra 110M .50 - .69 - .24 - GBERT 110M .72 - .69 - .23 - Gelectra 335M .52 - .56 - .19 - GBERT 337M .73 - .71 - .21 - Electra 335M - .88 - .64 - .08 Roberta 335M - .90 - .77 - .27 # Shots LeoLM 0 7B .61 - - - - - 5 .52 Mistral 0 7.24B .30 - - - - - 5 .55 Llama 3 0 8B .67 .78 - - - - 5 .59 .82 gpt 3.5 0 - .68 .89 .40 .46 .17 .16 5 .72 .89 .43 .47 .20 .20 .18 gpt 4 0 - .70 .87 .87 .36 .41 .20 .20 .15 5 .76 .89 .89 .89 .41 .43 .43 .43 .22 .18

Stanford CS课程 +基于CARTA评论的四分之一分类
首先,鉴于BERT与Flan-T5相比在课程和季度分类方面表现更好,我们可以推测为什么可能是这样。鉴于Bert和Flan-T5都使用双向上下文建模(考虑到前面的单词和成功的单词),因此这两个模型似乎不太可能对评论的语义进行不同的处理。However, there is a significant difference between the two in that while the BERT model directly outputs a prediction based on the tokenized review as input, the FLAN-T5 model does have to go through an additional preprocessing step of attaching a prefix to each review, instructing the model to output a certain type of output (e.g.请'输出一个在0到208之间的数字,对于209个标签课程分类),这意味着,对于Flan-T5输入的每个评论实际上在前缀上延长了较长的时间,并且可能在隔离和评估评论本身时会给模型带来更多的混淆空间。