XiaoMi-AI文件搜索系统
World File Search SystemBERT

一种强化学习方法,用于减轻语言模型中的刻板印象偏见
广泛采用由BERT和GPT等大型语言模型提供支持的应用程序,突出了社区内部对这种模型可以从培训数据中继承的意外偏见的影响的担忧。为了表现出来,过去的工作报告了LLM的证据,这些LLM扩大了性别刻板印象以及地理和种族偏见。以前的方法集中在数据预处理技术或技术上,这些技术或技术试图直接嵌入以增加资源需求,符号工作以及对足够偏见类型的适用性方面的限制方面,直接嵌入具有很大的缺点。在本文中,我们提出了精炼-LM,这是一种使用模型架构以及偏置型的强化学习对偏差的事后过滤。在包括Distillbert,Bert和Roberta在内的一系列模型中进行的实验表明,所提出的方法(i)在保留语言模型性能的同时,大大减少了刻板印象的偏见; (ii)实现适用于广泛的偏见类型,跨越诸如基于种族,宗教和基于国籍的偏见等环境的概括; (iii)减少所需的培训措施。

洞察力向下但远离:无症状感染后SARS-COV-2免疫的耐用性
自SARS-COV-2泛滥以来,围绕对病毒的生成和维持免疫及其对感染严重程度的疾病的生成和维持。来自原始严重急性呼吸综合征(SARS)和中东呼吸综合征(MERS; Sariol和Perlman,2020)的较旧数据,以及Covid-19之后的免疫力(Long等,2020年)的早期分析,引起了人们对保护性免疫免受SARS-SARS-SARS-COV-2感染的持久性的关注。与此关注有关的是在总病例负载中的无症状感染表示,估计范围高达80%(Ing等,2020)。再次,早期数据表明,个体中免疫反应的幅度与疾病的严重程度相关,这升高了高度无症状感染率可能会进一步损害保护性免疫力的耐用性(Cervia等,2021; Long等,2020)。杜克大学与新加坡国立大学(杜克 - 纽斯大学)之间的新兴传染病合作计划与新加坡的其他研究机构合作,遵循SARS-COV-2爆发的最初几个月中移民工人宿舍的居民对居民的反应。Le Bert等。 (2021)能够识别和跟踪Le Bert等。(2021)能够识别和跟踪

微调的“小” llm(仍然)明显优于零射击...
生成AI提供了一种简单的,基于及时的替代方案,用于微调较小的BERT风格的LLM,以进行文本分类任务。这有望消除对手动标记的培训数据和特定于任务模型培训的需求。但是,仍然是一个悬而未决的问题。在本文中,我们表明,较小的,微调的LLM(仍然)始终如一,明显优于较大的零射击,这促使文本分类中的模型。我们将三种主要的生成AI模型(与GPT-3.5/GPT-4和Claude Opus)与多种分类任务(情感,批准/不赞成,情绪,情感,党派职位)和文本类别(新闻,推文,演讲,演讲)中进行了比较。我们发现,在所有情况下,使用特定于应用程序的培训数据进行微调均可取得卓越的性能。为了使更广泛的受众更容易访问这种方法,我们将提供一个易于使用的工具包。我们的工具包,伴随着非技术分步指导,使用户能够以最小的技术和计算工作来选择和调整类似BERT的LLM,以完成任何分类任务。

正面 8 月 21 日 - 县日报
作者:丹·佐贝尔 8 月 16 日凌晨,切斯特消防局收到一则关于斯旺威克街上一辆货车起火的消息。这听起来很简单,但事实并非如此。事实证明,这起事件让全市和周边社区团结起来,帮助控制可能升级为更糟糕局面的事件。据消防局局长马蒂·伯特说,接到 5 点 25 分的电话后,第一个到达现场的消防员注意到货车旁边的交通标志顶上有一条电线。消防局叫来电力公司切断电源,并使用干化学药品扑灭最初的火焰。火被扑灭后,人们发现天然气在漏出。这导致火势重新燃起。伯特说这一切都很偶然。电线掉在了标志牌上。标志牌的立柱接触或几乎接触到它下面的一条四英寸长的天然气管道。因此,电流是通过标志牌立柱进入天然气管道的。电线上出现了一个铅笔大小的洞,天然气从地面冒了出来。没人知道电线倒塌的原因。目前正在调查。伯特说,消防员立即疏散了两个街区的居民。他说,由于该地区的电线带电,他们不得不让火自行熄灭。据伯特说,最终疏散了五六个街区的居民。镇东侧多达 500 个煤气表也被关闭。消防部门和煤气主管杰里米·霍曼以及员工乔希·斯特雷特、詹姆斯·布罗克迈耶


脂质在早期生命中的重要性
Berthold Koletzko是LMU的埃尔纳·苏尼奥尔专业人士 - 路德维希·马克西米利安斯大学慕尼黑,部门儿科,德国慕尼黑LMU大学医院冯·霍纳尔儿童医院博士。他在南非约翰内斯堡 - 索托的Baragwanath医院的儿科培训;坦桑尼亚莫西的乞力马扎罗基督教医疗中心;以及杜塞尔多夫大学和加拿大多伦多大学的儿童医院。他的工作着重于儿童健康和预防疾病的代谢和营养调节剂。Bert是1181篇科学期刊文章,252章章节和46本书/专着的作者。他的研究资金在过去十年中达到20英里。 Rosenquist基金会和其他资金机构。research.com在2023年将他评为儿科中排名最高的德国研究人员,引用了60,230个,D索引为129。Expertscape 2023将BERT评为“母乳喂养”,“人牛奶”,“牛奶”,“牛奶”和“婴儿营养生理现象”的“世界专家”(全球最高的0.01%研究人员之一,在过去十年中的出版物中,在全球范围内的出版物中),以及世界上最重要的“儿童营养生理学生理学”和“儿童生理学现象”。
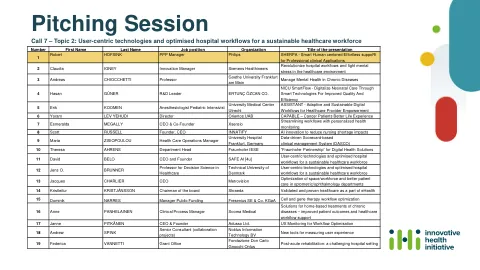
推销会议 - 创新的健康计划
“医疗保健中的员工短缺只会增加放射科医生,心脏病学家,护士和其他医疗保健提供者的工作量。成本正在上升,人们正在增长,需要更多的慢性护理。“以人为本的创新是一种可以部署以减轻护理负担的力量。技术必须在这方面变得屈从。” https://innovationorigins.com/en/with-human-中心innovation-and-innovation-and-ai-philips-aims-to-to- unlenden-Healthcare/

非编码结构变体确定了早期神经发育中常见的调节区域转向FOXG1转录
早期神经发育中的FOXG1转录lisa hamerlinck 1,2,*,eva d'Haene 1,2,*,Nore van Loon 1,2,3,Michael bevaughan 1,2,3,Maria delRocioPérezBaca 1,2 Esperanza Daal 1,2,Annelies Dheedene 1,2,Himanshu Goel 4,5,BjörnMenten1,2,Bert Callewaert 1,2 1,2,Sarah Vergult 1,2 *这些作者同样贡献了1.贡献1.同等1.维修,根特大学,根特,比利时,4猎人遗传学,纽卡斯尔,澳大利亚瓦拉塔尔5号纽卡斯尔大学,纽卡斯尔大学 - 澳大利亚卡拉汉的医学与公共卫生学院,卫生学院早期神经发育中的FOXG1转录lisa hamerlinck 1,2,*,eva d'Haene 1,2,*,Nore van Loon 1,2,3,Michael bevaughan 1,2,3,Maria delRocioPérezBaca 1,2 Esperanza Daal 1,2,Annelies Dheedene 1,2,Himanshu Goel 4,5,BjörnMenten1,2,Bert Callewaert 1,2 1,2,Sarah Vergult 1,2 *这些作者同样贡献了1.贡献1.同等1.维修,根特大学,根特,比利时,4猎人遗传学,纽卡斯尔,澳大利亚瓦拉塔尔5号纽卡斯尔大学,纽卡斯尔大学 - 澳大利亚卡拉汉的医学与公共卫生学院,卫生学院早期神经发育中的FOXG1转录lisa hamerlinck 1,2,*,eva d'Haene 1,2,*,Nore van Loon 1,2,3,Michael bevaughan 1,2,3,Maria delRocioPérezBaca 1,2 Esperanza Daal 1,2,Annelies Dheedene 1,2,Himanshu Goel 4,5,BjörnMenten1,2,Bert Callewaert 1,2 1,2,Sarah Vergult 1,2 *这些作者同样贡献了1.贡献1.同等1.维修,根特大学,根特,比利时,4猎人遗传学,纽卡斯尔,澳大利亚瓦拉塔尔5号纽卡斯尔大学,纽卡斯尔大学 - 澳大利亚卡拉汉的医学与公共卫生学院,卫生学院


疏忽经济
* 早期版本于 2018 年 12 月发布,标题为“注意力不集中经济的福利定理”。我们感谢 Jakub Steiner 和 John Leahy 分别在 2019 年和 2021 年 ASSA 会议上讨论我们的论文;感谢 Daron Acemoglu、Benjamin Hébert、Jennifer La'O、Stephen Morris、Alessandro Pavan 和 Harald Uhlig 的评论和精彩讨论。Angeletos 感谢美国国家科学基金会(资助编号 SES-1757198)的支持。† MIT 和 NBER;angelet@mit.edu ‡ MIT;ksastry@mit.edu