XiaoMi-AI文件搜索系统
World File Search SystemBRFSS

引用:Lupague R.M.J.M.,Mabborang R.C.,Bansil A.G.,Lupague M.M. (2023)全面心脏病风险的集成机器学习模型
摘要:长期以来,心血管疾病(CVD)仍然是全球死亡的主要原因之一。新技术(例如机器学习(ML)算法)的兴起可以帮助早期检测和预防开发CVD。这项研究主要关注不同ML模型来通过使用个人生活方式因素来确定一个人开发CVD的风险。这项研究在2021年从世界卫生组织(WHO)中使用,提取和处理了438,693条记录作为行为风险因素监视系统(BRFSS)的数据。然后将数据分配为训练和测试数据的比率为0.8:0.2,以具有未知数据以评估将要训练的模型。这项研究面临的一个问题是类别之间的不平衡,这是通过使用采样技术来解决的,以平衡ML模型的数据来处理和理解。使用10层化的倍数交叉验证测试评估ML模型的性能,最佳模型是Logistic回归(LR),F1得分为0.32564。然后,对logistic回归模型进行了高参数调整,并获得0.3257的最佳分数,C = 0.1。特征的重要性也是从LR模型中产生的,影响最大的特征是性,糖尿病和个人的一般健康。获得最终的LR模型后,然后在测试数据中对其进行评估,并获得0.33的F1分数。混淆矩阵也用于更好地可视化性能。简介和,LR模型正确分类了79.18%的CVD和73.46%的健康人。AUC-ROC曲线还用作性能度量标准,LR模型的AUC得分为0.837。逻辑回归模型可以在医疗领域中使用,可以通过向数据添加医学属性来更多地利用。总体而言,这项研究为我们提供了一个洞察力和重要的知识,可以通过仅使用个人的个人属性来帮助预测CVD的风险。关键字:机器学习算法,心血管疾病,逻辑回归,不平衡分类,超参数调整。

基于证据的糖尿病预防计划
高管摘要前糖尿病是一种医疗状况,人们的血糖水平高于正常血糖水平,这使他们面临未经干预而患有2型糖尿病的风险。在北卡罗来纳州,大约三分之一的患有糖尿病前期的人属于种族和少数民族群体。2016年,北卡罗来纳州大会为公共卫生部(DPH)提供了资金,用于通过北卡罗来纳州卫生公平办公室(OHE)建立和管理基于证据的糖尿病预防计划,该计划以前被称为少数群体健康与健康差异办公室(NC OMHHD)。该计划旨在针对非洲裔美国人,西班牙裔/拉丁美洲人和美国印第安人,并与慢性病和伤害部分协商。糖尿病预防计划(DPP)旨在帮助糖尿病前的人负责其健康和福祉。这些基于证据的计划运行了12个月,可以帮助患有糖尿病前期的人或患有2型糖尿病的高风险的人可以改变生活方式,这可以降低他们患2型糖尿病的风险,最高可降低58%(CDC,“预防2型糖尿病”)。本报告概述了北卡罗来纳州少数民族糖尿病预防计划(NC MDPP)指标,并确定了提高其有效性的区域。背景前糖尿病是人们的血糖水平高于正常血糖水平(mg/dl),但其Mg/dl尚未足够高以至于被诊断为糖尿病。截至2023年,北卡罗莱纳州的2,765,0000名患有糖尿病。在这些受访者中,有30.3%的人是种族和少数民族。在全国范围内,估计有9600万美国成年人患有糖尿病前期,但其医疗保健提供者已通知19%(CDC,国家糖尿病统计报告,2022年)。非洲裔美国人,美洲印第安人,阿拉斯加原住民,亚洲人,西班牙裔,夏威夷人和其他太平洋岛民的风险高于开发2型糖尿病的非西班牙裔白人(CDC,糖尿病,报告卡2021)。在2022年,有12.1%的行为风险因素监视系统调查表明,医生或其他卫生专业人员告诉他们,他们患有糖尿病前期或边缘性糖尿病。(北卡罗来纳州卫生统计中心,BRFSS 2022)。仅在今年,北卡罗来纳州居民就有68.9万居民患了糖尿病。到2025年,北卡罗来纳州糖尿病的年度医疗保健费用估计超过170亿美元(北卡罗来纳州糖尿病咨询委员会报告2020年)。

AIM-AHEAD RFI 响应
机器学习正在个人和人口层面使用,以支持风险分层、预测模型和诊断与治疗的决策支持。由于这些模型是根据现实世界的数据开发的,因此算法反映了当前和历史偏见,这些偏见可能会加剧种族和民族、性别认同、性取向、残疾、年龄、社会阶层和地理位置的不平等。此回应将重点关注 NIH 需要解决的数据和系统问题,以支持 AI/ML 公平研究。为了解决公平问题,NIH 需要多样化的数据来源,涵盖广泛的人口统计、社会经济和健康相关数据。这些应提供社会和经济背景以及心理社会风险因素,例如种族、年龄、性别、经济状况、既往病史、住房状况、临床接触内外的患者体验,以及充分代表人群多样性的数据。由于临床诊疗之外的数据不是以常规或标准化方式捕获的,因此在获取和管理这些高度复杂和敏感的数据方面存在重大挑战。强大的信息学方法包括:1)了解报告数据的当前状况,包括评估报告数据是否代表公平相关的努力,以及是否足以识别在这些数据上训练的算法中的偏见。2)确定和实施策略以提高现有数据的质量和完整性。这些应包括:a)持续的数据质量识别、解决和验证,以解决差距、不准确性和偏见;b)预先识别数据质量问题,以便快速分类到报告实体;c)统计估算措施以填补空白。3)跟踪这些策略的有效性以改进现有数据。4)识别新的数据来源。这些来源可能包括诊所层面的社会需求筛查、大型公共卫生队列(如国家健康和营养检查调查 (NHANES))和监测系统(如行为风险因素监测系统 (BRFSS))、大型研究队列研究(如美国国立卫生研究院的精准医学计划、我们所有人研究计划和国家 COVID 队列协作 (N3C))——它们整合了参与者从不同群体收集的数据源。其他潜在来源包括移动或遥感设备和在线地理编码数据,这些数据可能提供有关公平性的宝贵见解。5) 模型评估。虽然有不断发展的分析技术来评估和解释可能反映社会偏见的算法偏见,但开发、测试和使用这些模型的研究人员需要对意外结果保持敏感,并识别数据中和训练模型的专家中的偏见。社区参与和包括那些代表性不足的人(偏见最受影响的人)的观点是必不可少的一步。
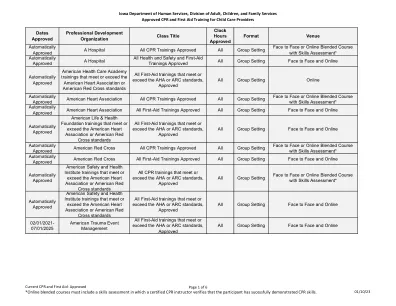
爱荷华州人类服务部,成人,儿童和家庭服务部 与组合疫苗的免疫计划 婴儿幼儿学龄前儿童健康表格 儿童疫苗(VFC)计划脑膜炎球菌偶联疫苗摘要 爱荷华州医疗补助战略计划介绍 C1.2生殖生命计划.docx 精神药物建议部分A 针对预防评估(TAP) 预付费室内健康计划(PAHP)登机 儿童疫苗(VFC)计划可用疫苗和覆盖年龄范围 爱荷华州儿童疫苗计划 质量策略2024 爱荷华州BRFSS简介:2023调查GS 重大事件审查 - 综合卫生之家人 - 流感疫苗预订和接收说明的订单 孤儿药(稀有疾病) 爱荷华州HHS第一五个高管摘要 A.家庭案例计划面板
自动批准了美国心脏协会所有CPR培训批准所有小组设置面对面或在线混合课程与技能评估*自动批准的美国心脏协会所有急救培训都批准了所有小组设置面对面和在线