XiaoMi-AI文件搜索系统
World File Search SystemBiases

朝着搜索和推荐的双面公平框架
随着人工智能(AI)的辅助搜索和推荐的系统在工作场所和日常生活中变得无处不在,对公平性的理解和核算在此类系统的设计和评估中引起了人们的关注。虽然越来越多的计算研究对测量系统的公平性和与数据和算法相关的偏见,但人类偏见超出了传统机器学习(ML)管道的影响仍在研究中。在此观点论文中,我们试图开发一个双面公平框架,不仅表征了数据和算法偏见,而且还突出了可能加剧系统偏见并导致不公平决定的认知和感知偏见。在框架内,我们还分析了搜索和接收性发作中人类和系统偏见之间的相互作用。基于双面框架,我们的研究综合了在认知和算法中采用的干预策略,并提出了新的目标和措施,以评估Sys-Tems在解决以及与数据相关的风险相关的偏见,Algoryty和Algority and Boundered and Boundered Rationals and boundered Rationals and Indered Rationals and Indered Rationals and Indered Rationals and Indered Rationals and Indered Rationals and Indered rentations。这是唯一地将有关人类偏见和系统偏见的见解纳入一个凝聚力的框架,并从以人为中心的角度扩展了公平的概念。扩展的公平框架更好地反映了用户与搜索和推荐系统的相互作用的挑战和机遇。采用双面信息系统设计中的方法有可能提高在线偏见的有效性,以及对参与信息密集型决策的有限理性用户的有用性。

Xiong博士,清研究助理教授 主题代码MM5433主题标题决策分析作者... comp6712.pdf 连续体中的多重弹性绑定状态 b'' apss1a04 AMA4370 主题说明表格 应用数学中的次要程序(... 提供交换/短期非本地研究学生的主题清单2(春季)2024/25康复科学系(RS)BS 应用数学系(AMA) AP40014 EEE525绿色城市的智能运输 LSGI4502 EEE522自动驾驶汽车 医学实验室科学 配对年度报告 sft205fy-intoduction-to-Fashion Exenteration。 ... ama566 选修课
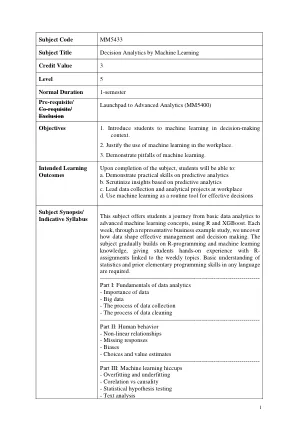
此主题为学生提供了从基本数据分析到使用R和XGBoost的高级机器学习概念的旅程。每周通过代表性的业务示例研究,我们发现数据如何形成有效的管理和决策。该主题逐渐建立在R编程和机器学习知识的基础上,从而为学生提供了与每周主题相关的R分配的实践经验。需要对任何语言的统计和先前的基本编程技能的基本理解。-------------------------------------------------------------------------------- Part I: Fundamentals of data analytics - Importance of data - Big data - The process of data collection - The process of data cleaning -------------------------------------------------------------------------------- Part II: Human behavior - Non-linear relationships - Missing responses - Biases - Choices and value estimates -------------------------------------------------------------------------------- Part III: Machine learning hiccups - Overfitting and underfitting - Corelation vs causality - Statistical hypothesis testing - Text analysis

劳伦斯·伯克利国家实验室
摘要:山上在水资源可用性中起着极大的作用,并且它们提供的水的数量和时机在很大程度上取决于温度。为此,我们提出了一个问题:大气模型捕捉山温度的程度如何?我们合成结果表明,高分辨率,与区域相关的气候模型产生的空气温度(T2M)测量比观察到的(一种“冷偏置”)更冷,尤其是在冬季雪覆盖的中纬度山脉中。我们在全球山脉的44项研究中发现了常见的冷偏见,包括单模型和多模型合奏。我们探讨了推动这些偏见的因素,并检查了T2M背后的物理机制,数据限制和观察性不确定性。我们的分析表明,偏见是真实的,不是由于观察到的稀疏性或分辨率不匹配。冷偏置主要发生在山峰和山脊上,而山谷通常是温暖的偏见。我们的文献综述表明,增加模型分辨率并不能清楚地减轻偏见。通过分析科罗拉多洛矶山脉中的地表大气中的数据集成现场实验室(SAIL)现场活动,我们测试了与冷偏见有关的各种假设,发现当地的风回流,长波(LW)辐射和地表层参数有助于在此特定位置的T2M偏见。我们通过强调在仪器高的山区位置的协调模型评估和开发工作的价值来解决,以解决T2M偏见的根本原因,并提高对山气候的预测性理解。

大气模型在山上太冷了吗?帆场运动的科学和见解
摘要:山上在水资源可用性中起着极大的作用,并且它们提供的水的数量和时机在很大程度上取决于温度。为此,我们提出了一个问题:大气模型捕捉山温度的程度如何?我们合成结果表明,高分辨率,与区域相关的气候模型产生的空气温度(T2M)测量比观察到的(一种“冷偏置”)更冷,尤其是在冬季雪覆盖的中纬度山脉中。我们在全球山脉的44项研究中发现了常见的冷偏见,包括单模型和多模型合奏。我们探讨了推动这些偏见的因素,并检查了T2M背后的物理机制,数据限制和观察性不确定性。我们的分析表明,偏见是真实的,不是由于观察到的稀疏性或分辨率不匹配。冷偏置主要发生在山峰和山脊上,而山谷通常是温暖的偏见。我们的文献综述表明,增加模型分辨率并不能清楚地减轻偏见。通过分析科罗拉多洛矶山脉中的地表大气中的数据集成现场实验室(SAIL)现场活动,我们测试了与冷偏见有关的各种假设,发现当地的风回流,长波(LW)辐射和地表层参数有助于在此特定位置的T2M偏见。我们通过强调在仪器高的山区位置的协调模型评估和开发工作的价值来解决,以解决T2M偏见的根本原因,并提高对山气候的预测性理解。

大气模型在山上太冷了吗?帆场运动的科学和见解
摘要:山上在水资源可用性中起着极大的作用,并且它们提供的水的数量和时机在很大程度上取决于温度。为此,我们提出了一个问题:大气模型捕捉山温度的程度如何?我们合成结果表明,高分辨率,与区域相关的气候模型产生的空气温度(T2M)测量比观察到的(一种“冷偏置”)更冷,尤其是在冬季雪覆盖的中纬度山脉中。我们在全球山脉的44项研究中发现了常见的冷偏见,包括单模型和多模型合奏。我们探讨了推动这些偏见的因素,并检查了T2M背后的物理机制,数据限制和观察性不确定性。我们的分析表明,偏见是真实的,不是由于观察到的稀疏性或分辨率不匹配。冷偏置主要发生在山峰和山脊上,而山谷通常是温暖的偏见。我们的文献综述表明,增加模型分辨率并不能清楚地减轻偏见。通过分析科罗拉多洛矶山脉中的地表大气中的数据集成现场实验室(SAIL)现场活动,我们测试了与冷偏见有关的各种假设,发现当地的风回流,长波(LW)辐射和地表层参数有助于在此特定位置的T2M偏见。我们通过强调在仪器高的山区位置的协调模型评估和开发工作的价值来解决,以解决T2M偏见的根本原因,并提高对山气候的预测性理解。

人工智能中的偏见与公平性回顾
决策系统的自动化导致了人工智能 (AI) 使用中的隐藏偏见。因此,解释这些决策和确定责任已成为一项挑战。因此,出现了一个新的算法公平性研究领域。在这个领域,检测偏见并减轻偏见对于确保公平和无歧视的决策至关重要。本文的贡献包括:(1) 对偏见进行分类,以及偏见与人工智能模型开发的不同阶段(包括数据生成阶段)的关系;(2) 修订公平性指标以审核数据和用它们训练的人工智能模型(在关注公平性时考虑不可知模型);(3) 对减轻人工智能模型开发不同阶段(预处理、训练和后处理)偏见的程序进行新的分类,并增加有助于生成更公平模型的横向行动。


算法招聘的兴起:关于人工智能你需要了解些什么……
人们还希望算法能够帮助消除当今招聘中的一些偏见。人类容易产生各种偏见,甚至我们的无意识偏见也会影响我们的决策。尽管公众一直在推动改善多样性、公平性和包容性 (DEI),但许多组织未能解决限制招聘多元化候选人的根本原因。一些人希望使用算法招聘可以帮助消除招聘决策中的无意识偏见,并有望增加招聘的多样性。另一方面,算法很有可能不会消除人类的偏见,而只是重现它们。算法只是“学习”并试图重现过去(人类)的决策,这意味着该数据集中的偏见很可能会在算法的决策中重新出现,从招聘广告开始,一直持续到整个过程。3

设想医疗保健中的Chatgpt的未来
抽象背景和目的:CHATGPT代表了在医疗保健研究中受到极大关注的最流行和广泛使用的生成人工智能(AI)模型。当前研究的目的是根据最有影响力的发表记录的建议来评估该领域所需研究的未来轨迹。材料和方法:在Scopus,Web of Science和Google Scholar(2023年11月27日至30日)上进行了系统的搜索,以确定在三个数据库中在医疗保健中与ChantGPT相关的前十名发表记录。将记录分类为“顶级”,表示该领域的高影响力是基于引文数。 结果:来自17个不同期刊的共有22个独特的记录,代表14个不同的出版商是医疗保健主题中与ChatGPT相关的顶级出版物。 Based on the identified records' recommendations, the following themes appeared as important areas to consider in future ChatGPT research in healthcare: improving healthcare education, improved efficiency of clinical processes (e.g., documentation), addressing ethical concerns (e.g., patient privacy and consent), supporting research tasks (e.g., data analysis, manuscript preparation), mitigating ChatGPT output biases, improving patient education and参与,并制定标准化评估方案,用于医疗保健中的CHATGPT公用事业。 结论:当前的评论强调了在评估医疗保健中的Chatgpt公用事业时要优先考虑的关键领域。 需要跨学科的合作和标准化方法来综合这些研究中的强大证据。将记录分类为“顶级”,表示该领域的高影响力是基于引文数。结果:来自17个不同期刊的共有22个独特的记录,代表14个不同的出版商是医疗保健主题中与ChatGPT相关的顶级出版物。Based on the identified records' recommendations, the following themes appeared as important areas to consider in future ChatGPT research in healthcare: improving healthcare education, improved efficiency of clinical processes (e.g., documentation), addressing ethical concerns (e.g., patient privacy and consent), supporting research tasks (e.g., data analysis, manuscript preparation), mitigating ChatGPT output biases, improving patient education and参与,并制定标准化评估方案,用于医疗保健中的CHATGPT公用事业。结论:当前的评论强调了在评估医疗保健中的Chatgpt公用事业时要优先考虑的关键领域。需要跨学科的合作和标准化方法来综合这些研究中的强大证据。基于这些建议以及Chatgpt在医疗保健方面的有希望的潜力,JMJ发起了一篇论文的呼吁,以“评估基于AI的医疗保健中的生成性AI模型”。