XiaoMi-AI文件搜索系统
World File Search SystemCVF

基于事件的结构 - 轨道 - CVF Open Access
事件传感器提供高时间分辨率的视觉感应,这使其非常适合感知快速视觉效果,而不会遭受运动模糊的困扰。机器人技术和基于视觉的导航中的某些应用需要3D感知在静态相机前进行圆形或旋转的物体,例如恢复对象的速度和形状。设置等于用轨道摄像头观察静态对象。在本文中,我们提出了基于事件的结构 - 轨道(ESFO),其目的是同时重建从静态事件摄像头观察到的快速旋转对象的3D结构,并恢复相机的等效轨道运动。我们的贡献是三重的:由于最新的事件特征跟踪器无法处理由于旋转运动而导致的定期自我遮挡,因此我们根据时空聚类和数据关联开发了一种新颖的事件特征跟踪器,可以更好地跟踪事件数据中有效特征的螺旋螺旋传播。然后将特征轨道馈送到我们的新颖因素基于图形的结构后端端,该结构从后端进行计算轨道运动插曲(例如自旋速率,相对旋转轴),从而最大程度地减少了重新投影误差。进行评估,我们在旋转运动下生成了一个新事件数据集。比较与地面真理表示ESFO的功效。

量子多模型拟合 - CVF 开放获取
几何模型拟合是一个具有挑战性但又十分基础的计算机视觉问题。最近,量子优化已被证明可以增强单模型情况的稳健拟合,同时多模型拟合的问题仍未得到解决。为了应对这一挑战,本文表明后一种情况可以从量子硬件中显著受益,并提出了第一种多模型拟合 (MMF) 的量子方法。我们将 MMF 表述为一个问题,现代绝热量子计算机可以对其进行有效采样,而无需放宽目标函数。我们还提出了一种迭代和分解版本的方法,该方法支持真实世界大小的问题。实验评估在各种数据集上都显示出有希望的结果。源代码可在以下位置获得:https://github.com/FarinaMatteo/qmmf 。

触觉增强的辐射场 - CVF Open Access
我们提出了一个场景表示形式,我们称之为触觉的辐射场(TARF),它将视觉和触摸带入共享的3D空间。此表示形式可用于估计场景中给定3D位置的视觉和触觉信号。我们从一系列照片和稀疏采样触摸探针中捕获了场景的tarf。我们的方法利用了两个见解:(i)基于常见的触摸传感器建立在普通摄像机上,因此可以使用多视图几何形状中的方法对图像进行注册,并且(ii)在视觉和结构上相似的场景区域具有相同的触觉效果。我们使用这些见解将触摸信号注册到捕获的视觉场景中,并训练有条件的扩散模型,该模型带有从神经辐射场呈现的RGB-D图像,生成其相应的触觉信号。为了评估我们的方法,我们收集了一个TARF的数据集。此数据集比预先持有的现实世界数据集包含更多的触摸样本,并且为每个捕获的触摸信号提供了空间对齐的视觉信号。我们揭示了跨模式生成模型的准确性以及在下游任务上捕获的视觉效果数据的实用性。项目页面:https:// dou- yiming.github.io/tarf。

灵巧的抓紧变压器-CVF Open Access
在这项工作中,我们提出了一种新颖的歧视性框架,用于灵巧的掌握生成,称为d外部g rasp tr ansformer(dgtr),能够通过仅使用一个向前的通行方式处理对象点云来预测一组可行的抓握姿势。我们将敏捷的掌握生成作为设定的预测任务,并为其设计一个基于变压器的握把模型。但是,我们确定此设置的预测范式在灵活的掌握领域遇到了几种优化的挑战,并导致限制性能。为了解决这些问题,我们提出了培训和测试阶段的渐进策略。首先,提出了动态静态匹配训练(DSMT)策略,以增强训练阶段的光学稳定性。第二,我们使用一对对抗性损失来实现对抗平衡的测试时间适应(ABTTA),以提高测试阶段的掌握质量。dexgraspnet数据集的实验结果证明了DGTR可以预测具有高质量和多样性的灵活掌握姿势的能力。值得注意的是,在保持质量高的同时,DGTR Sigsigs所预测的Grasp的多样性明显优于先前的多个指标,而没有任何数据预处理。代码可在https://github.com/isee-laboratory/dgtr上找到。

反馈引导的自主驾驶-CVF Open Access
虽然行为克隆最近已成为自主驾驶的非常成功的范式,但Humans很少学会通过单独的模仿或行为克隆来执行复杂的任务,例如驱动或行为。相比之下,人类的学习通常涉及在整个交互式学习过程中的其他详细指导,即通常通过语言的反馈提供详细的信息,以详细信息,以进行审判的哪一部分进行,不正确或次要地进行。以这种观察的启发,我们引入了一个有效的基于反馈的框架,用于改善基于行为克隆的传感驱动剂培训。我们的关键见解是利用大语模型(LLM)的重新进步,以提供有关驾驶预测失败背后的理由的纠正良好的反馈。更重要的是,我们引入的网络体系结构是有效的,是第一个基于LLM的驾驶模型的第一个感觉运动端到端培训和评估。最终的代理在Nuscenes上的开环评估中实现了最新的性能,在准确性和碰撞率上的表现优于先前的最新时间超过8.1%和57.1%。在卡拉(Carla)中,我们的基于相机的代理在以前的基于激光雷达的AP摄入率上提高了16.6%的驾驶得分。

北欧车辆数据集 (NVD) - CVF 开放获取
摘要 无人机图像中的车辆检测和识别是一个复杂的问题,已用于不同的安全目的。这些图像的主要挑战是从斜角捕获的,并带来了一些挑战,例如非均匀照明效果、退化、模糊、遮挡、能见度丧失等。此外,天气条件在引起安全问题方面起着至关重要的作用,并为收集的数据增加了另一个高水平的挑战。在过去的几十年里,人们采用了各种技术来检测和跟踪不同天气条件下的车辆。然而,由于缺乏可用数据,在大雪中检测车辆仍处于早期阶段。此外,还没有使用无人机 (UAV) 拍摄的真实图像在雪天检测车辆的研究。本研究旨在通过向科学界提供北欧地区不同环境和各种积雪条件下无人机拍摄的车辆数据来解决这一空白。数据涵盖不同的恶劣天气条件,如阴天降雪、低光照和低对比度条件、积雪不均、高亮度、阳光、新雪,以及温度远低于-0摄氏度。该研究还评估了常用物体检测方法(如 YOLOv8s、YOLOv5s 和 Faster RCNN)的性能。此外,还探索了数据增强技术,以及那些增强检测器性能的技术

任何身份的生成学位 - CVF Open Access
在大规模数据集训练的生成模型的最新进展使得可以合成各个领域的高质量样本。此外,强烈反转网络的出现不仅可以重建现实世界图像,还可以通过各种编辑方法对属性进行修改。,在与隐私问题有关的某些领域中,例如Human Faces,先进的生成模型以及强大的反转方法可能会导致潜在的滥用。在此过程中,我们提出了一个必不可少但探索的任务不足的任务,称为生成身份,该任务引导该模型不要生成特定身份的图像。在未经学习的生成身份中,我们针对以下内容:(i)防止具有固有身份的图像的产生,以及(ii)保留生成模型的整体质量。为了满足这些目标,我们提出了一个新颖的框架,对任何IDE NTITY(指南)进行了努力,该框架通过仅使用单个图像来删除发电机来阻止特定身份的重建。指南由两个部分组成:(i)找到一个优化的目标点,该目标点未识别源潜在代码和(ii)促进学习过程的新型损失函数,同时影响较小的学习分布。我们的广泛实验表明,我们提出的方法在通用机器学习任务中实现了最先进的性能。该代码可在https://github.com/khu-agi/guide上找到。

生成量子颜色成像-CVF开放访问
单光摄像机的惊人发展为科学和工业成像创造了前所未有的机会。但是,这些1位传感器通过这些1位传感器进行的高数据吞吐量为低功率应用创造了重要的瓶颈。在本文中,我们探讨了从单光摄像机的单个二进制框架生成颜色图像的可能性。显然,由于暴露程度的差异,我们发现这个问题对于标准色素化方法特别困难。我们论文的核心创新是在神经普通微分方程(神经ode)下构建的暴露合成模型,它使我们能够从单个观察中产生持续的暴露量。这种创新可确保在Col-Orizers进行的二进制图像中保持一致的曝光,从而显着增强了着色。我们演示了该方法在单图像和爆发着色中的应用,并显示出优于基准的生成性能。项目网站可以在https://vishal-s-p.github.io/projects/ 2023/generative_quanta_color.html

带有扩散模型的视频插值-CVF Open Access
我们提出了Vidim,这是一个视频间隔的生成模型,该模型在启动和最终框架下创建了简短的视频。为了实现高保真度并在输入数据中产生了看不见的信息,Vidim使用级联的分化模型首先以低分辨率生成目标视频,然后在低分辨率生成的视频上生成高分辨率视频。我们将视频插补的先前最新方法归纳为先前的最新方法,并在大多数设置中演示了这种作品如何在基础运动是复杂,非线性或模棱两可的情况下失败,而Vidim可以轻松处理此类情况。我们还展示了如何在开始和最终框架上进行无分类器指导,并在原始高分辨率框架上调节超级分辨率模型,而没有其他参数可以解锁高保真性结果。vidim可以从共同降低所有要生成的框架,每个扩散模型都需要少于十亿个pa-rameters来产生引人注目的结果,并且仍然可以在较大的参数计数下享有可扩展性和提高质量。请在vidim- Interpolation.github.io上查看我们的项目页面。
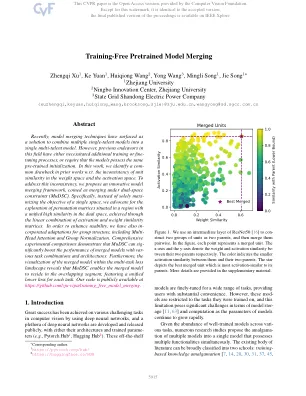
无培训预处理的模型合并-CVF Open Access
最近,模型合并技术已浮出水面,作为将多个单元模型组合为单个多泰模型组合的解决方案。但是,该领域的先前努力需要进行其他培训或细调过程,或者要求模型具有相同的预先训练的初始化。在这项工作中,我们在W.R.T.先前的工作中确定了一个缺点。单位相似性在重量空间和激活空间中的不一致性。为了解决这种不一致,我们提出了一个创新的模型合并框架,该模型是在双空间约束(MUDSC)下合并的。具体而言,我们主张探索位于双重空间中统一高相似性的区域中的置换矩阵,而不是仅仅使单个空间的目标最大化,这是通过激活和重量相似性矩阵的线性组合实现的。为了提高可用性,我们还对群体结构进行了对企业的适应,包括多头关注和群体标准化。全面的实验比较表明,MUDSC可以很明显地提高具有各种任务组合和体系结构的合并模型的性能。此外,多任务损失景观中合并模型的可视化表明,MUDSC使合并的模型能够驻留在重叠段中,其中每个任务都有统一的较低损失。我们的代码可在https://github.com/zju-vipa/training_free_model_merging上公开获取。