XiaoMi-AI文件搜索系统
World File Search SystemCaption

Tropicana可再生能源公告
Caption From left (standing): Stephen Perkins (General Manager, Tropicana Gold Mine, AGAA), Nelius Janse van Rensburg (Project Manager, AGAA), Vicky Scobie (Manager, Energy and Decarbonisation, AGAA), Andries Swart (Vice President, Projects – Australia, AGAA), Matt Duxbury (General Manager Commercial, Pacific Energy), Neil Thompson (Manager,资产管理,AGAA),西蒙·罗尔(Simon Roll)(Pacific Energy,Pacific Energy分部经理),Grant Farquhar(Pacific Energy的远程能源董事总经理),Jamie Cullen(Pacific Energy,Pacific Energy,Pacific Energy)左(座位):Michael Erickson(澳大利亚高级副总裁,Agaa,Agaa),Cliff Lawrenson(Cliff Lawrenson(Cliff Lawrenson))

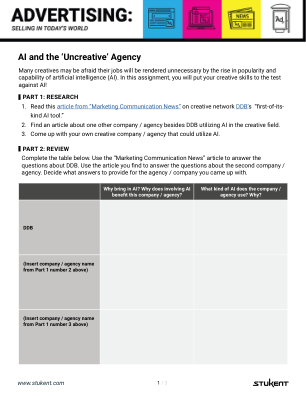
人工智能与“缺乏创意”的机构
1. 对于上面列出的每个机构/公司,创建一个利用第 2 部分表格中确定的 AI 的社交媒体帖子模型。 2. 对于每个社交媒体帖子模型,创建一个标题,写出您认为的主要受众是谁,并简要说明您选择该媒体的原因。

心脏健康-NY.GOV
标题高血压,高血液胆固醇和吸烟是心脏病的关键危险因素。生活方式选择,例如身体上的无活动和饮酒,也会增加风险。学习如何保护您的心脏:heart.org/-/media/healthy-living-files/le8-fact-sheets/lifes_essential_8_fact_sheet.pdf


2023 年 12 月 两名董事被任命担任航空航天董事会的重要领导职务
要提交照片供 Aerospace Snapshot 考虑,请发送电子邮件至 orbiter@aero.org,主题为:“Aerospace Snapshot”,并附上照片附件、标题和致谢。如果您在 Orbiter 门户上没有看到 Aerospace Snapshot 模块,请检查“管理小部件”下的个性化设置。

2024 年第一季度投资者简报
本演示文稿中的某些陈述具有前瞻性,定义见《1995 年私人证券诉讼改革法》。这些陈述涉及风险、不确定性和其他因素,可能导致实际结果与这些前瞻性陈述所表达或暗示的信息存在重大差异,并且可能不代表未来结果。这些前瞻性陈述受多种风险和不确定性的影响,包括但不限于超出管理层控制范围的各种因素,包括我们最新的 10-K 表年度报告第一部分标题“第 1A 项。风险因素”下讨论的“风险因素”标题下列出的风险或我们 10-Q 表季度报告第二部分标题“第 1A 项。风险因素”下讨论的任何更新以及我们向 SEC 提交的其他文件。在做出投资决策时,不应过分依赖本演示文稿中的前瞻性陈述,这些陈述基于我们在此日期可获得的信息。除非法律要求,否则我们不承担更新此信息的义务。

2024 年第二季度投资者简报
本演示文稿中的某些陈述具有前瞻性,定义见《1995 年私人证券诉讼改革法》。这些陈述涉及风险、不确定性和其他因素,可能导致实际结果与这些前瞻性陈述所表达或暗示的信息存在重大差异,并且可能不代表未来结果。这些前瞻性陈述受多种风险和不确定性的影响,包括但不限于超出管理层控制范围的各种因素,包括我们最新的 10-K 表年度报告第一部分标题“第 1A 项。风险因素”下讨论的“风险因素”标题下列出的风险或我们 10-Q 表季度报告第二部分标题“第 1A 项。风险因素”下讨论的任何更新以及我们向 SEC 提交的其他文件。在做出投资决策时,不应过分依赖本演示文稿中的前瞻性陈述,这些陈述基于我们在此日期可获得的信息。除非法律要求,否则我们不承担更新此信息的义务。


超声 +人工智能的力量
标题Health的AI应用程序可实现可靠,一致的超声检查,以帮助临床医生提供更精确的诊断,并改善治疗决策 - 最终改善了患者的结果。此次收购旨在帮助新手用户扩大对超声成像的可负担访问,并与全球范围更广泛地转移到Precision Care。