XiaoMi-AI文件搜索系统
World File Search SystemClu

PICALM 和 CLU 风险变异对阿尔茨海默病患者 β 脑电图活动的影响
PICALM 和 CLU 基因与大脑生化过程的改变有关,这可能会对阿尔茨海默病 (AD) 的发展和神经生理动态产生影响。本研究的目的是分析脑电图 (EEG) 活动与 PICALM 和 CLU 等位基因之间的关系,这些等位基因被描述为给 AD 患者和健康对照者带来风险或保护作用。为此,从以下人群中获取 EEG 活动:18 名 AD 患者和 12 名对照者携带 PICALM 和 CLU 基因的风险等位基因,以及 35 名 AD 患者和 12 名对照者携带两种保护性等位基因。计算常规 EEG 频带 (delta、theta、alpha、beta 和 gamma) 中的相对功率 (RP) 以量化源级别的大脑活动。此外,计算每个频带的空间熵 (SE) 以表征整个大脑中 RP 值的区域分布。在 AD 组中,不同基因型在 β 波段的整体 RP 和 SE 方面存在统计学显著差异(p 值 < 0.05,Mann-Whitney U 检验)。此外,在 AD 中分析的 68 个皮质区域中,有 58 个皮质区域的 RP 显示出统计学显著差异。在任何频带中,对照组均未发现统计学显著差异。我们的结果表明,PICALM 和 CLU AD 诱导基因型参与了与 β 功率中断相关的生理过程,这可能与 β-淀粉样蛋白和神经递质代谢改变等生理紊乱有关。

标枪反坦克导弹系统 - 中等
标枪系统正在进行两个独立但互补的升级,称为G-Model导弹和轻重量命令发射单元(LW CLU)。陆军测试和评估命令(ATEC)于2023年3月在LW CLU上进行了有限的用户测试(LUT),并于2023年8月进行了FOT&E。虽然分析正在进行,并且DOT&E希望在2QFY24中发布报告,但LUT和FOT&E的早期结果表明,LW CLU达到了其性能要求,并且具有LW CLU的士兵表现出色,或者比当前的Block 1 Clu竞争目标时配备了LW CLU,或者更好。LW CLU由于新的故障导致多个系统中止,因此在FOT&E期间不符合其可靠性要求。G模型导弹由于22财年的飞行测试故障而经历了发育延迟,并将重新启动24财年的政府LED飞行和致命测试。

烧伤房地产和建筑管理学院
CA-C Certified Appraiser-Counselor (AACA-American Association of Certified Appraisers) CA-R Certified Appraiser-Residential (AACA-American Association of Certified Appraisers) CA-S Certified Appraiser, Senior (AACA-American Association of Certified Appraisers) CGA Colorado Certified General Appraiser (CBREA-State of Colorado, Board of Real Estate评估者)CHFC宪章财务顾问(金融服务专业人员的SFSP-Society)CIPS认证国际房地产专家(NAR-NAR-NAR-NAR-NARTORS®)CLU CLU租赁租赁承销商(金融服务专业人员的SFSP Socociety)投资
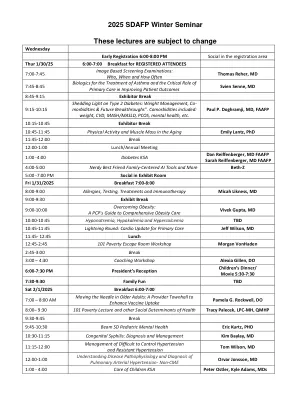
2025 SDAFP冬季研讨会这些讲座都需要...
1:00/00 -4:00糖尿病KSA Rootters,Mdafpp Santah 4:00 nerdilp free free free free ai ded由Clu:



循环经济的碳回收
se slid e s and y y y yin yin y yin g ph e se n tain tain tain forw ard ard gookin g state m e n ts。All state m e n ts, oth e r th an state m e n ts of h istorical fact, in clu d e d in th e se slid e s an d an y accom p an yin g oral p re se n tation are forw ard -lookin g state m e n ts re fle ctin g m an ag e m e n t's cu rre n t b e lie fs an d e xp e cta tion s. In som e case s, you can id e n tify forw ard -lookin g state m e n ts b y te rm in olog y su ch as “w ill,” “a n ticip ate ,” “e xp e ct,” “b e lie ve ,” “in te n d ” a n d “sh ou ld ” or th e n e g ative of th e se te rm s or oth e r com p arab le te rm in olog y.在稳定的状态中,在clu d e n y d a n y y t a y n y t a y n y t s y y n t s n t s n t s n t s n t s n t s n t s n t s n t s clu d a an t s clu d e a an t clu deation中产生exp e tim t tim and t tim t t t t t to t of d e p lom e n ts g to to to to t to t to t to t to t to t to t to t to t to t t tim。 Th e se state m e n ts are b ase d on variou s assu m p tion s, w h e th e r or n ot id e n tifie d in th is p re se n tation , an d on th e cu rre n t e xp e ctation s of ou r m an ag e m e n t a n d are n ot p re d iction s of actu al p e rform an ce .An y forw ard -lookin g state m e n ts con tain e d h e re in are b ase d on assu m p tion s th at we b e lie ve to b e re ason ab le as of th e d ate h e re of.exce p t是法律的,我们可以在e -e the the the the the the the the the the the the the the the the the the the the the e n ts中,如果以形式上的范围内的可用性。迟到的状态,或者要付出了可能的风险,并在范围内征服了风险d fu fu n t fu the se ce of ce of ce of ce of ce of ce of ce e n ts e xp re sse d re sse d或im p lie de b lie d o the se e se forw Ard ard a a forw ard to ard abookin g state m e n ts ts。Th e p ote n tial risks an d u n ce rtain tie s th at cou ld cau se actu al re su lts to d iffe r from th e re su lts p re d icte d in clu d e , am on g oth e rs, th ose risks an d u n ce rtain tie s in clu d e d u n d e r th e cap tion s “Risk Factors” an d “Man ag e m e n t's Discu ssion an d An alysis of Fin an cial Con d ition an d Re su lts of Op e ration s” in ou r Form 10 -K file d w ith th e Se cu ritie s an d Exch an g e Com m ission an d su b se q u e n t an n u al re p orts, q u arte rly re p orts an d oth e r filin g s m ad e w ith th e Se Cu ritie s and d交换了从Tim E到Tim E的g e comm。


来自植物标本室的含水量的数据集(TO)
由于地衣对几种环境参数(例如气候因素和空中化学物质)敏感,因此可以将它们作为气候变化和土地利用以及空气污染和其他人类影响的生物鉴定者(Giordani和Brunialti 2015,2015年,Giordani 2019)。历史记录是确定地衣多样性趋势以及解释潜在驱动因素的强制性参考(Nelsen和Lumbsch 2020)。植物标志收集被认为是关于地衣分布的时空数据的基本档案,以及进行操纵和分析研究的物质来源,支持了从当地到全球环境变化的研究(例如Farkas等。 (2022),Wu等。 (2023))。 因此,越来越多地通过多个门户提倡对标本室数据的可访问性。 就意大利而言,由于几种现代意大利地衣植物植物的数据汇总到意大利的意大利信息系统(Martellos等人)(Martellos等),产生了显着的进步 2023)。 该系统目前从13种草药中汇总了88,000多个记录,其中包括herbarium Universitatis tergestinae的数据集(TSB,Conti等人。 2023)和卡拉布里亚大学植物园的植物园(Clu,Conti等人 2024)已经在GBIF中发布。Farkas等。(2022),Wu等。(2023))。因此,越来越多地通过多个门户提倡对标本室数据的可访问性。就意大利而言,由于几种现代意大利地衣植物植物的数据汇总到意大利的意大利信息系统(Martellos等人)(Martellos等2023)。该系统目前从13种草药中汇总了88,000多个记录,其中包括herbarium Universitatis tergestinae的数据集(TSB,Conti等人。2023)和卡拉布里亚大学植物园的植物园(Clu,Conti等人2024)已经在GBIF中发布。

CD3E(T细胞标记)抗体
使用簇蛋白 / apoj小鼠单克隆抗体(CLU / 4729)的蛋白阵列分析含有19,000多个全长人蛋白。z-和s得分:z-分数表示单克隆抗体(MAB)(与荧光标记的抗IGG二抗二抗)的信号的强度,当与HuprottM阵列上的特定蛋白质结合时会产生。z得分以标准偏差(SD)的单位(SD)的平均值来描述。该数组上生成的所有信号的平均值。如果huprottm上的目标按z得分的降序排列,则s得分是z得分之间的差异(也以SD的单位为单位)。s得分表示mAb与其预期目标的相对目标特异性。如果mAb的S分数至少为2.5,则将mAb视为特定于其预期目标的mAb。例如,如果mAb与Z得分为43的蛋白X与Z-SCORE 14的蛋白质Y结合,则该mAb与蛋白质X结合的s分数等于29。