XiaoMi-AI文件搜索系统
World File Search SystemClustal


猿类:系统发育和进化分析
描述 用于读取、写入、绘制和操作系统发育树的函数,在系统发育框架中分析比较数据,祖先特征分析,多样化和宏观进化分析,计算 DNA 序列的距离,读取和写入核苷酸序列以及从 BioConductor 导入,以及多种工具,例如 Mantel 检验、广义天际线图、系统发育数据的图形探索(alex、trex、kronoviz)、使用平均路径长度和惩罚可能性估计绝对进化率和时钟树,使用非同时期序列确定树的年代,将 DNA 转化为 AA 序列,以及评估序列比对。系统发育估计可以用 NJ、BIONJ、ME、MVR、SDM 和三角法以及几种处理不完整距离矩阵的方法(NJ*、BIONJ*、MVR* 和相应的三角法)来完成。一些函数调用外部应用程序(PhyML、Clustal、T-Coffee、Muscle),其结果返回到 R 中。

B.A.经济学 科学硕士(微生物学)M.Sc。 (...B.A.经济学科学硕士(微生物学)M.Sc。 (...
模块1:序列分析该项目的目的是使用在线工具(例如Blast或Clustal Omega)分析核苷酸或蛋白质序列。学生将从公共数据库(如NCBI)中选择一种感兴趣的基因或蛋白质,检索序列并执行序列比对以识别同源区域。他们将分析物种序列的相似性和差异,并解释进化关系。这个项目可以在家中使用计算机和Internet访问完成,需要5-7天。最终输出将是一份报告,详细介绍了基因或蛋白质的作用及其在物种之间的保护。模块2:该项目中的数据库探索,学生将探索GenBank,Uniprot或PDB等公共数据库以检索核酸和蛋白质序列。目标是提取和分析注释的信息,以了解基因功能和蛋白质结构。学生将比较跨物种的这些序列并解释其

ali-u-net:用于DNA序列多个序列比对的卷积变压器神经网。概念证明
我们报告了能够对齐多个核苷酸序列的卷积变压器神经网络。神经网络基于图像分割中常用的U-NET,我们采用了该神经网络将其用于将未对准序列转换为对齐序列的U-NET。对于对齐场景,我们的ALI-U-NET神经网络已经接受过培训,在大多数情况下,它比MAFFT,T-Coffee,Muscle和Clustal Omega等程序更准确,同时比单个CPU核心上的类似准确的程序快得多。的限制是,神经网络仍针对某些对齐问题进行了专门训练,并且对于以前从未见过的差距分布而表现不佳。此外,该算法当前与48×48或96×96核苷酸的固定尺寸比对窗口一起工作。在此阶段,我们将研究视为概念证明,确信目前的发现可以扩展到更大的一致性,并在不久的将来将其扩展到更复杂的一致性方案。

动物学和遗传学系
事件:使用生物信息学工具日期和时间探索生物序列:28-05-2024场地:房间号215,计算机实验室公司的主人:动物学和遗传学系助理教授Deepa Gopinath博士。资源人员:Nimmi Haridas博士,喀拉拉邦高知的Cirist生态系统应用科学家。研讨会的目的是向学生介绍基本的生物信息学工具和核苷酸分析的应用,以提供对遗传学,进化模型和系统发育分析中基因分析的洞察力以及基因分析的应用。Nimmi博士将参与者介绍了OMICS技术,包括基因组学,蛋白质组学,转录组学和代谢组学,及其在生物医学,遗传和进化研究中的应用。 她概述了一些关键数据库,例如GenBank,Ensembl,Uniprot以及使用Blast,FastA等在线工具进行的序列检索和分析。 参与者在使用生物信息学工具进行序列对齐,搜索和分析方面接受了动手培训。 参与者从Genbank数据库中检索了序列,并使用BLAST将这些序列与已知遗传数据进行比较。 参与者使用Clustal Omega对来自不同物种的一组蛋白质序列(如血红蛋白)进行多个序列比对。 使用PDB文件可视化蛋白质和核酸的3D结构。 学生使用Rasmol练习,以突出蛋白质结构中的α-螺旋和β-谱。 研讨会成功地实现了为参与者提供基本生物信息学技能的目标。Nimmi博士将参与者介绍了OMICS技术,包括基因组学,蛋白质组学,转录组学和代谢组学,及其在生物医学,遗传和进化研究中的应用。她概述了一些关键数据库,例如GenBank,Ensembl,Uniprot以及使用Blast,FastA等在线工具进行的序列检索和分析。参与者在使用生物信息学工具进行序列对齐,搜索和分析方面接受了动手培训。参与者从Genbank数据库中检索了序列,并使用BLAST将这些序列与已知遗传数据进行比较。参与者使用Clustal Omega对来自不同物种的一组蛋白质序列(如血红蛋白)进行多个序列比对。使用PDB文件可视化蛋白质和核酸的3D结构。学生使用Rasmol练习,以突出蛋白质结构中的α-螺旋和β-谱。研讨会成功地实现了为参与者提供基本生物信息学技能的目标。

使用系统发育
Silico生物学中的摘要被认为是一种有效且适用的方法来启动各种研究,例如生物多样性分类学保护。在用于兰花物种的硅分类法中使用的系统发育分析可以提供有关遗传多样性和进化关系的数据。在分类学研究中可用于评估基因基因座特定靶标的一种特殊方法是DNA条形码。进行了这项研究,以使用MAT K,RBC L,RPO C1和NRDNA标记来确定特定的靶基因基因基因,用于使用系统发育分析在硅方法中使用Silico方法的Coelogyne属的DNA条形码。所有标记序列均从NCBI网站收集,并使用多种软件和方法进行分析,即用于样品序列对齐的Clustal X和用于系统发育树的结构和分析的Mega 11。恢复表明,建议使用的基因基因座是nrDNA基因基因座。系统发育分析表明,NRDNA基因基因座的使用能够将17种coelogyne物种与两个外群物种分开,即Cymbidium和Vanilla,然后与1,5-双磷酸羧化酶/氧合酶/氧合酶/氧合酶/氧合酶大型亚基(RBC l)一起,而其他基因群和其他polim subiN locase and n namely malsy matulase k(rbc l)(namely kita k)(namely malsy matuly k)(namy k'' RPO C1)提供了一种视觉植物树,其中两个外群物种与Coelogyne物种相同。因此,这项研究的结果可用作支持Coelogyne育种和保护计划的参考。版权所有:©2023,J。热带生物多样性生物技术(CC BY-SA 4.0)
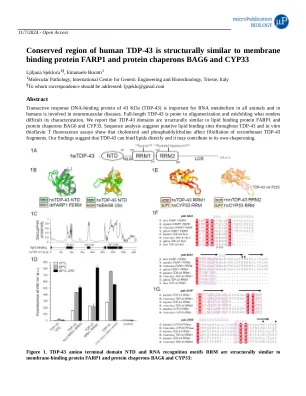
人类TDP-43的保守区域在结构上类似于膜结合蛋白FARP1和蛋白质伴侣Bag6和Cyp33
1a人类TDP-43(HSTDP-43)的示意图:NTD-氨基末端结构域,NLS-核定位信号,RRM-RNA识别基序,LCR-low复杂性区域;在RRM1中类似PIASE的序列和假定的聚集和RRM2中的纤维化启动序列被证明,并以粉红色显示顺式P225。1B HSTDP-43 NTD结构域与斑马鱼Farp1的Ferm结构域以及Dali产生的人类Bag6的泛素样域。1C的HSTDP-43残基的溶解倾向为绘制的TDP-43序列绘制的脂质结合区域无序;预测的脂质结合区域无序表示为黑色矩形,并根据HSTDP-43氨基酸序列编号。重组的1d噻铁黄素T荧光在37°C或65°C下在胆固醇(C)和磷脂酰胆碱(PC)的情况下在生理温度下或在65°C下在生理温度下或65°C下在生理温度下或65°C下在生理温度下孵育的HSTDP-43构建体和对照样品;误差线表示来自一式三份实验的平均值的标准误差。1E HSTDP-43 RRM1和小鼠TDP-43 RRM2主题达利生成的叠加到HSCYP33 RRM域的3D模型; MMTDP43 RRM2顺式Proline P225标有粉红色的星号。1f欧米茄生成的人,小鼠,鸡肉和鱼Farp1和TDP-43的多个序列比对,以及Zebra Fish Ferm域的二级结构元素相对于多个序列对齐信息的二级结构元素的二级结构元素;白色和黑色钻石分别代表了TDP-43和FARP1中的假定或实验确认的脂质结合残基。1G人和小鼠CYP33 RRM和PPIASE结构域的多个序列对齐,以及人和小鼠TDP-43 RRM1和RRM2基序; HSTDP-43 RRM1或HSCYP33 PPIASE域的二级结构元素的ESPRIPT生成的渲染相对于多个序列比对信息; TDP-43 rrm2中的顺式脯氨酸用粉红色的星号表示,并且在所有排列序列中,粉红色矩形突出显示了该位置。 CYP33参与底物结合的残基用白色球表示,其中一些与肽基prolyl prolyl cis-Trans异构化的HSCYP33残基由黑色球体表示,而催化HSCYP33 S239不包括由于空间限制而包括。