XiaoMi-AI文件搜索系统
World File Search SystemCompounding

通用章节<795> 药物配制
本章旨在为配药师提供指导,指导他们如何应用良好的配药规范来配制非无菌复合制剂,以便向人类或动物分发和/或给药。配药是药学实践中不可或缺的一部分,对医疗保健至关重要。本章和适用的配方专论有助于定义良好的配药规范。此外,本章还提供了一般信息,以提高配药师在配药设施中即刻配制具有可接受强度、质量和纯度的制剂的能力。药剂师、其他医疗保健专业人员和其他从事药物制剂配制的人员应遵守适用的州和联邦配药法律、法规和指南。

VSV 2024 和修订后的复合指南 2024
由于收入尚未确定,命令已根据该通知通过 [常见问题 26] ▪ 命令已于指定日期通过,但提起上诉的时限尚未到期 [常见问题 9] ▪ 对拒绝注册慈善信托(授予免税)提出上诉 [常见问题 23] ▪ 等待处理的利息豁免申请 [常见问题 15] ▪ 与其他直接税有关的争议 – 财富税、STT、CTT 和 EL [常见问题 13]

药房复合咨询委员会(PCAC)名册
Anita Gupta, DO, MPP, GMP, PharmD, FASA Expertise: Anesthesiology, Pain, Health Policy, Pharmacology, General Management Term: 1 2/18/2020 – 9/30/2 0 25 Full Clinical Professor, Medicine University of California Riverside School of Medicine 900 University Avenue Riverside, California 92521 Adjunct Assistant Professor Johns Hopkins School of Medicine Department of Anesthesiology and Critical马里兰州巴尔的摩护理21205

2025药物复合认证组织RPG
•确认在认证申请中报告的信息,验证旅行计划信息和通往办公室和设施的指示,•确认您访问联合委员会连接extranet网站以及可用的与认证相关的信息(现场访问议程,认证审核过程指南等。),然后•回答任何组织的问题并解决任何问题。物流•在现场,审阅者将在访问期间需要工作空间。桌子或桌子,电话,互联网连接以及对电源插座的访问是可取的。审阅者还需要一个安全且可访问的位置,以在审核期间保留其财产。•一些审核活动将需要一个可以容纳一群参与者的房间或区域。小组活动参与者应在可能的情况下受到限制,以提供有关讨论主题的洞察力的关键个人。参与者的选择留给了组织的酌处权;但是,本指南确实提供了建议。•审稿人将希望搬到药房,如果适用的话,在医院,在复合药物示踪剂期间,患者护理部门,与员工交谈并观察药物工作人员进行的日常药物复合活动。审稿人将依靠组织工作人员找到讨论可以

终端分销商对从事药物复合的处方者的要求
2。非危害*的制备或重建,常规制造的无菌危险药物用于直接管理,而没有根据制造商的标签进行准备,管理和超越使用的标签。(例如,准备肉毒杆菌毒素注射)。3。非危害*,非无菌危险药物制剂的复合,制备,稀释或重建。(例如,阿莫西林的口服悬浮液,需要重建)。4。拥有俄亥俄州许可外包设施提供的复合药物制剂。(注意:如果处方者化合物从外包设施中收到的任何无菌药物,则处方者办公室将获得许可作为TDDD)。5。非危害*的稀释,常规生产的无菌危险药物(例如,稀释或混合到注射器中直接给患者施用)。

2024年12月4日,药房复合咨询委员会会议
Brian P. Lee,医学博士,MAS(通过视频会议平台;仅与胸腺素Alpha相关的BDSS主题)胃肠道和肝脏疾病副教授凯克医学院南加州洛杉矶大学凯克学校,加利福尼亚州洛杉矶大学,加利福尼亚珍妮特·S·李(Janet S. Lee)医学医学医学教授病理学和免疫学教授约翰·T·米利肯医学系华盛顿大学,圣路易斯圣路易斯,密苏里州
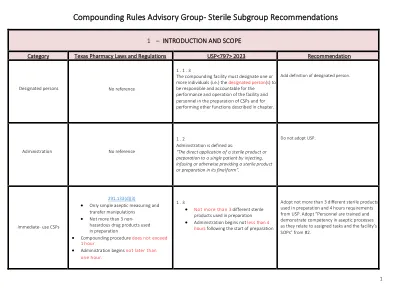
复合规则咨询小组 - 无菌子组建议
1。4“复合不包括根据产品制造商提供的批准的标签或补充材料的指示进行的混合,重建或其他行为。根据制造商批准的标签准备常规制造的无菌产品,如果以下方式,USP <797>

复合的力量:时间如何成为您最好的...
本报告旨在独家使用受托顾问的客户或潜在客户(“接收者”),并且本文包含的信息是机密的,并且在未经信心顾问事先批准的情况下向任何其他人进行了传播或分发。已从认为是可靠的来源获得了信息,尽管未经独立验证。任何预测都是假设的,代表未来的期望,而不是实际的回报波动和相关性将与预测有所不同。本报告不代表特定的投资建议。本文所表达的意见和分析基于受托顾问的研究和专业经验,并在本报告的日期表达。请就特定建议咨询您的顾问,律师和会计师。过去的表现并不表示未来的表现,并且存在损失的风险。

有效的逆增强学习而不复合错误
逆增强学习(IRL)是一种模仿学习的政策方法(IL),使学习者可以在火车时间观察其行动的后果。因此,对于IRL算法,有两个看似矛盾的逃亡者:(a)防止阻塞离线方法的复合误差,例如诸如避免克隆之类的方法,并且(b)避免了强化学习的最坏情况探索复杂性(RL)。先前的工作已经能够实现(a)或(b),但不能同时实现。在我们的工作中,我们首先证明了一个负面结果表明,没有进一步的假设,没有有效的IRL算法可以避免在最坏情况下避免复杂错误。然后我们提供了一个积极的结果:在新的结构条件下,我们将奖励态度不足的政策完整性称为“奖励”,我们证明有效的IRL算法确实避免了犯错的错误,从而为我们提供了两个世界中最好的。我们还提出了一种使用亚最佳数据来进一步提高有效IRL算法的样本效率的原则方法。