XiaoMi-AI文件搜索系统
World File Search SystemContext




背景和上下文
背景和背景,鉴于气候变化和发展的多方面挑战,对于发展中国家采用创新和综合的政策策略来追求韧性,绿色和变革性的发展,这比以往任何时候都更为重要。从发展中国家的角度解决如何应对这些多方面的挑战的辩论,联合国贸易和发展(UNCTAD)开发了一个项目,旨在帮助亚洲四个主要的发展中国家 - 哈萨克斯坦,马来西亚,巴基斯坦,巴基斯坦和Türkiye-以实现可持续发展目标的努力,以实现可持续发展的发展(SDGSDGS Green Trunptigative)。,该项目旨在帮助参与国家实现2030年的议程至1)有效的综合政策战略和提高国家一级的能力,包括南南同行学习; 2)区域一级的经济合作与政策协调。türkiye是一个上层收入国家,具有牢固的基础设施连通性和与其他亚洲经济体的贸易联系。像大多数地中海国家一样,Türkiye非常容易受到气候变化的影响。近几十年来,洪水,热浪,干旱,野火,滑坡和极端的暴风雨以增加的频率和强度影响了该国。türkiye在2021年批准了《巴黎气候协议》,旨在到2053年实现净零碳排放。努力启动工业转型的绿色议程可以追溯到1990年代中期和第七五年的发展计划,并包括
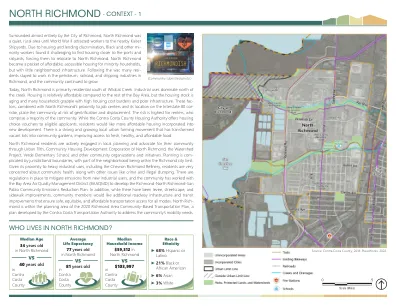
北里士满- 背景 - 1
如今,北里士满主要为 Wildcat Creek 以南的住宅区。溪流以北则以工业为主。与湾区其他地区相比,这里的住房价格相对便宜,但住房存量正在老化,许多家庭面临着高昂的住房成本负担和糟糕的基础设施。这些因素,再加上北里士满靠近就业中心,位于 80 号州际公路走廊,使该社区面临着中产阶级化和流离失所的风险。租户的风险最高,因为他们占社区的大多数。虽然康特拉科斯塔县住房管理局向符合条件的申请人提供住房选择券,但居民希望在新开发项目中纳入更多经济适用房。当地城市农业运动发展势头强劲,将空地改造成社区花园,改善了人们获取新鲜、健康和实惠食品的渠道。



Enfortumab Vedotin 简介
摘要:Enfortumab vedotin (EV) 是一种新型抗体-药物偶联物,是同类中首个获得 FDA 批准用于治疗难治性尿路上皮癌患者的药物。Enfortumab 由一种靶向广泛表达于尿路上皮癌的 nectin-4 的抗体和单甲基澳瑞他汀 E (MMAE) 化疗有效载荷组成。迄今为止,在对铂类化疗和/或检查点抑制剂有耐药性的尿路上皮癌中进行的试验表明,该药物非常有效,总体反应率为 40% 至 52%。这包括内脏转移患者,这是预后不良的已知预测因素。EV 的耐受性相当好,包括不适合使用顺铂的患者,顺铂是常见的尿路上皮癌人群,存在大量未满足的需求。皮肤毒性、疲劳和血糖升高等副作用通常可以通过支持治疗和剂量调整来控制。周围神经病变很常见,对有反应的患者来说可能是剂量限制,并且有罕见的严重皮肤毒性报告。针对各种疾病状态以及与检查点抑制剂和其他药物联合使用的试验正在进行中,未来 EV 在尿路上皮癌中可能还有其他适应症。关键词:抗体-药物偶联物、尿路上皮癌、转移性、治疗难治性

COVID-19 背景下的 Biovac
“在进行技术转让之前,重要的是要展望 5-10 年以后的前景,看看产品的长期价值。对于疫苗来说尤其如此,即使转让了成熟的技术,本地生产的产品也可能需要长达 5-7 年的时间才能经过测试和获得许可,而到那时市场可能已经发生了变化。”

印度背景下的农业恐怖主义
1. 引言 自古以来,军事力量就被用来保护或重新划定边界、发动或镇压革命、实现宗教壮举。随着科技的发展,军事策略和目标发生了很大变化。随着前苏联和两极世界的解体、市场的开放,国际安全形势的重点从政治军事冲突转向政治经济冲突。在两次毁灭性的世界大战(第一次世界大战和第二次世界大战)之后,众多国际和平条约已经使全面军事冲突的可能性变得微乎其微。虽然常规军事仍然是进攻和防御战略的核心,但许多国家已将重点放在大规模杀伤性武器 (WMD) 上,这种武器可能基于核武器、化学武器或生物材料。与核武器和化学武器相比,生物武器或生物战 (BW) 剂便宜得多,可以在合法且装备精良的生物实验室中使用简单的工艺制备,因此易于隐藏 1。 BW 药剂具有自我传播的特性,因此只需要很少的起始量就可以在很短的时间内影响大片地理区域内的目标人群。