XiaoMi-AI文件搜索系统
World File Search SystemDevlin

ny forskning i musikterapi:marts 2024
克里·德夫林(Kerry Devlin)自2021年9月1日以来一直与CE-DOMUS相关联,捍卫了他的论文2024年6月25日。尤其是在她担任音乐治疗师的美国,有必要与社会,政治和社会潮流的影响有关音乐治疗师的工作,并特别与自由和公民权利的运动有关。Kerry Devlin研究了 在评估方法课程中,她甚至教音乐治疗师的学生。 此外,她与一个患有唐氏综合症的年轻女子和该女性母亲的母亲一起检查了音乐疗法,因此还讨论了包括客户作为CO -研究者的道德含义。Kerry Devlin研究了在评估方法课程中,她甚至教音乐治疗师的学生。此外,她与一个患有唐氏综合症的年轻女子和该女性母亲的母亲一起检查了音乐疗法,因此还讨论了包括客户作为CO -研究者的道德含义。

重新审视神经网络近似理论...
Devlin, Jacob 等人。“Bert:用于语言理解的深度双向转换器的预训练。”arXiv 预印本 arXiv:1810.04805 (2018)。Radford, Alec 等人。“语言模型是无监督的多任务学习者。”OpenAI 博客 1.8 (2019):9。Brown, Tom 等人。“语言模型是少数学习者。”神经信息处理系统进展 33 (2020):1877-1901。Chowdhery, Aakanksha 等人。“Palm:使用路径扩展语言建模。”arXiv 预印本 arXiv:2204.02311 (2022)。

青年工作的未来报告 - 爱尔兰议会大厦
爱尔兰国家青年委员会 • 首席执行官 Mary Cunningham 女士 • 政策和宣传主任 Paul Gordon 先生 都柏林市青年服务委员会 • 主任 Celene Dunne 女士 • 学校主任 Mark McDonald 先生 都柏林市教育和培训委员会 里亚托青年项目 • 经理 Dannielle McKenna 女士 • 青年工作者 Jim Lawlor 先生 爱尔兰国立大学梅努斯分校 • 应用社会研究教授 Maurice Devlin 教授 • 社区工作和青年工作团队的 Sinead McMahon 博士

AI心理计量学:通过心理计量学库存评估大语言模型的心理概况
近年来,大型语言模型(LLM)一直在处理不断增加的人类生成的数据。语言的神经模型,例如手套(Pennington等,2014),Bert(Devlin等,2019),GPT-2(Radford等,2018),Xlnet(Yang等,2019),Roberta(Roberta(Y. Liu等,2019),2019年),Bart(Lewis et al。在社会相关性的几种应用中的变革作用。各种作者将这些模型称为“基础模型”(Bommasani等,2021; Ribeiro等,2020),强调了它们为将来可以对许多不同的应用程序域和任务进行精心调整和适应的通用计算系统提供了通用的基础。此类应用程序的示例包括

年度报告
对我们的治理实践作为战略制定的一部分的审查带来了进一步的变化。由农民当选的董事杰奎琳·罗瓦斯(Jacqueline Rowarth)于2024年4月被任命为我们的第一位副主席,以帮助代表戴伊尔兹(Dairynz)在治理层面上就对奶农至关重要的问题。我们还一直在董事会内的领导能力建立深度。其他董事会更改与审查一起进行的更改包括玛格丽特·德夫林(Margaret Devlin)搬回英国,因此今年早些时候辞去了独立董事的辞职。在她的两年中,她为董事会带来了独特的见解,我们感谢她的承诺。农民为董事会成员提供了很好的服务,他们带来了自己的见解,并为戴伊兹(Dairynz)做出了宝贵的贡献。

Quadrupletbert:一种基于嵌入的大规模检索的有效模型
大规模检索系统(例如搜索连接)一直是帮助人们访问大量在线信息的重要工具。各种技术来提高检索质量。由于从查询文本中进行计算搜索的困难以及准确代表文档要求的语义含义,大多数以前的研究都是基于经典的术语加权方法,例如BM-25(Robertson和Zaragoza,2009年)或TF-IDF(SpärckJones,1972年,1972年,或单词)或单词(MIK)或单词(MIK)或单词。,2013年)在关键字匹配可以解决的情况下表现良好。但是,这些模型仅接受稀疏的手工特征,并且无法捕获复杂的语义效果。考虑到像Bert这样的预训练的语言模型(Devlin等人,2019年)和罗伯塔(Liu等人,2019年)在广泛的

cv
3。an,J.-Y.,Lin,K.Z.,Zhu,L.,Werling,D.M.,Dong,S.,Brand,H.,Wang,H.Z.,Zhao,X.,Schwartz,G.B.,Collins,R.L.B.,Dastmalchi,C.,Dea,J.,Duhn,C.,Gilson,M.C.,Klei,L.,Liang,L.,Markenscoff-Papadimitriou,E.E.,Pochareddy,S.昆兰(A. R.(2018)。全基因组的从头风险评分暗示自闭症谱系障碍中的启动子变异。Science,362(6420)doi:10.1126/science.aat6576

指南提供理由,如...
1 https://eur-lex.europa.eu/legal-content/en/txt/txt/pdf/?uri=celex:02009r1107-20221121 2讨论以进一步定义规定中设定的保护目标(EC)NO 1107/2009和法规546/2011的保护目标(ec)。3 eur-lex -32013R0283-en-eur-lex(europa.eu)和eur-lex-32013R0284-en-eur-lex(uropa.eu)4 https://ec.europa.eu/info/info/info/info/strategy/strategy/priorities-priorities-priorities-priorities-2019-2019-20224/eearecorecorecon 5 https://ec.europa.eu/food/horizontal-topics/farm-farm-fork-strategy_en 6 Devos Y,Craig W,Devlin RH,Ippolito A,Ippolito A,Leggatt RA,Romeis J,Romeis J,Shaw R,Shaw R,Svendsen C和Svendsen C和Svendsen C和Topping CJ,2019年。使用问题制定来进行拟合预期的拟合预应激源的环境风险评估。EFSA期刊2019; 17(S1):E170708,31 pp。 https://doi.org/10.2903/j..efsa.2019.e170708 7指令2010/63/eu欧洲议会和2010年9月22日理事会关于用于科学目的的动物保护的理事会: https://eur-lex.europa.eu/legal-content/en/txt/pdf/?uri=celex:020101010l0063-20190626EFSA期刊2019; 17(S1):E170708,31 pp。https://doi.org/10.2903/j..efsa.2019.e170708 7指令2010/63/eu欧洲议会和2010年9月22日理事会关于用于科学目的的动物保护的理事会: https://eur-lex.europa.eu/legal-content/en/txt/pdf/?uri=celex:020101010l0063-20190626

ProGen:蛋白质生成的语言建模
蛋白质表征学习。自然语言处理中用于语境化表征的最新方法(McCann 等人,2017 年;Peters 等人,2018 年;Devlin 等人,2018 年)已被证明可以很好地用于语境蛋白质表征学习。可以使用线性方法从此类表征中提取有关蛋白质的结构信息,并且可以调整表征本身以提高其他任务的性能(Rives 等人,2019 年)。同样,UniRep(Alley 等人,2019 年)证明此类表征可用于预测天然和从头设计蛋白质的稳定性以及分子多样性突变体的定量功能。TAPE(Rao 等人,2019 年)是一个新的基准,由五个任务组成,用于评估此类蛋白质嵌入。虽然先前的研究主要集中于使用双向模型的可转移表示学习,但我们的工作展示了使用生成式单向模型的可控蛋白质工程。
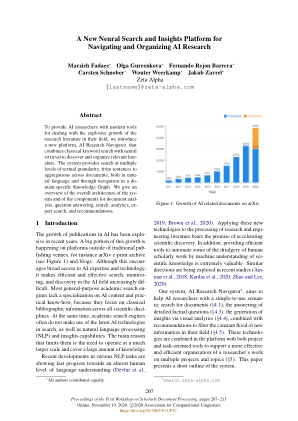
用于导航和组织 AI 研究的新型神经搜索和洞察平台
近年来,人工智能出版物数量呈爆炸式增长。这种增长很大一部分发生在传统出版场所之外的平台上,例如 arXiv 电子印刷档案(见图 1)和博客。虽然这鼓励广泛获取人工智能专业知识和技术,但它使人工智能领域的高效搜索、监控和发现变得越来越困难。大多数通用学术搜索引擎缺乏对人工智能内容和实践知识的专业化,因为它们专注于所有科学学科的经典书目信息。同时,学术搜索引擎通常不会在搜索中使用最新的人工智能技术,以及自然语言处理 (NLP) 和洞察功能。限制它们的主要原因是需要在更大规模上进行操作并涵盖大量知识。各种 NLP 任务的最新发展显示出快速进步,朝着几乎人类水平的语言理解迈进(Devlin 等人。,