XiaoMi-AI文件搜索系统
World File Search SystemEnsemble

通过量子神经网络集成技术节省资源
新兴的量子机器学习领域 [ 1 ] 有望利用量子计算技术提高机器学习算法的准确性和速度。尽管量子机器学习有望在化学、物理学、材料科学和药理学中某些类型的问题上发挥作用 [ 2 ],但它是否适用于更传统的用例仍不确定 [ 3 ]。值得注意的是,可用的量子机器学习算法通常需要经过调整才能在“NISQ”设备 [ 4 ] 上运行,这些设备是当前的噪声量子计算机,没有纠错,并且具有适中的量子比特数和电路深度能力。在量子机器学习场景中,经典神经网络的量子对应物——量子神经网络 [ 5 ] 已经成为解决量子领域有监督和无监督学习任务的事实标准模型。虽然量子神经网络引起了广泛的兴趣,但它们目前也存在一些问题。第一个是贫瘠高原 [ 6 ],其特点是随着系统规模的增加,损失梯度的方差呈指数快速衰减。这个问题可能会因各种因素而加剧,比如量子电路表达能力过强 [ 7 ]。为了解决这个问题,需要精心设计量子神经网络 [ 8 ],并结合可表达性控制技术,如投影 [ 9 ] 和带宽控制 [ 10 ]。第二个问题,也是本文要解决的问题,涉及运行量子神经网络所需的资源量(总量子比特数有限——目前最多一百多个——以及当前量子设备上操作的低保真度严重限制了量子神经网络在输入维度和层数方面的大小)。为了解决后一个问题,我们建议采用 NISQ 适当的集成学习实现 [11],这是经典机器学习中广泛使用的技术,用于通过使用多个弱组件构建更强的分类器来调整特定机器学习机制的偏差和方差,从而使整个集成系统的表现优于最好的单个分类器。集成系统的有效性已在经验和理论上得到广泛证明 [12],尽管

团结一致,一切皆有可能 - 团结一致,我们就能做到 - Rackcdn.com
• 为巴库提供最佳气候条件,温度适中、湿度低、降水量少,促进运动员发挥最佳表现,为观众提供愉快的环境 • 与学校/大学假期和传统的国定假日高峰期相吻合,确保: – 减少基础道路和公共交通水平 – 酒店入住率低 – 增加机会吸引更多观众,包括年轻人和学生志愿者 – 增加大学住宿/体育设施的可用性。• 与国际体育日程表完美契合,不会与重大国际体育赛事发生冲突,确保世界最佳运动员的出席。我们的高尔夫比赛将安排在不会与英国公开赛冲突的地方。我们的日期确保与媒体和广播公司的时间表保持一致,最大限度地提高全球收入和报道率。• 包括三个周末,以最大限度地提高广播报道和出席率 • 不与斋月等宗教时期冲突。在上述拟议期间,巴库不会举办其他重大活动。

增强 BCI 性能的功能连接集成方法(FUCONE)
表 1:研究中考虑的功能连接指标 FC 指标缩写类别参考瞬时相干性瞬时频谱相干性[31]虚相干性 ImCoh 频谱相干性[32]锁相值 PLV 相位估计[33]相位滞后指数 PLI 相位估计[34]平方 wPLI 的去偏估计量 wPLI2-d 相位估计[35]幅度包络耦合 AEC 幅度耦合[36、37]

使用集合机学习技术的糖尿病预测
D. Madhu Sudhana Rao,D。Sai。Sridhathri信息技术部,Vignan科学技术与研究基金会,印度Guntur,Madhudontha@gmail.com,sridhathri.1021@gmail.com摘要。 糖尿病最称为糖尿病是一种急性内分泌慢性疾病,这是许多人通过遗传性或从人类生活方式的趋势中的主要问题。 由于内分泌问题,它会提高体内的血糖。 血糖的这种增加不仅会影响其水平,甚至会导致许多与肾脏,肝功能,血压和眼睛损害相关的健康问题。 这在较小的年龄组中最常见,对于45岁以上的年龄组。 我国将近68%的人患有这些糖尿病患者。 当预测靠近水平时,可以避免或消除它。 在情况下,它被认为存在严重的问题,并且需要以任何代价控制它。 结合了计算机科学的技术,我们使用机器学习技术在早期阶段预测糖尿病,以更高的准确性。 在这里,我们使用不同的分类器,即k-nearest,幼稚的贝叶斯(NB),XG提升,决策树(DT)和随机森林(RF),并从提供的数据集中检测其准确性。 与其他不同技术相比,我们发现随机森林更适合于更高的精度计算。Sridhathri信息技术部,Vignan科学技术与研究基金会,印度Guntur,Madhudontha@gmail.com,sridhathri.1021@gmail.com摘要。糖尿病最称为糖尿病是一种急性内分泌慢性疾病,这是许多人通过遗传性或从人类生活方式的趋势中的主要问题。由于内分泌问题,它会提高体内的血糖。血糖的这种增加不仅会影响其水平,甚至会导致许多与肾脏,肝功能,血压和眼睛损害相关的健康问题。这在较小的年龄组中最常见,对于45岁以上的年龄组。我国将近68%的人患有这些糖尿病患者。当预测靠近水平时,可以避免或消除它。在情况下,它被认为存在严重的问题,并且需要以任何代价控制它。结合了计算机科学的技术,我们使用机器学习技术在早期阶段预测糖尿病,以更高的准确性。在这里,我们使用不同的分类器,即k-nearest,幼稚的贝叶斯(NB),XG提升,决策树(DT)和随机森林(RF),并从提供的数据集中检测其准确性。与其他不同技术相比,我们发现随机森林更适合于更高的精度计算。

基于超图的机器学习合奏网络入侵检测系统
摘要 - 检测恶意攻击的网络入侵检测系统(NID)继续面临挑战。NID通常是离线开发的,而它们面临自动生成的端口扫描尝试,从而导致了从对抗性适应到NIDS响应的显着延迟。为了应对这些挑战,我们使用专注于Internet协议地址和目标端口的超图来捕获端口扫描攻击的不断发展的模式。然后使用派生的基于超图的指标集来训练集合机学习(ML)基于NID的NID,以高精度,精确和召回表演以高精度,精确性和召回表演以监视和检测端口扫描活动,其他类型的攻击以及对抗性入侵。通过(1)入侵示例,(2)NIDS更新规则,(3)攻击阈值选择以触发NIDS RETRAINGE RECESTS的组合,以及(4)未经事先了解网络流量本质的生产环境。40个场景是自动生成的,以评估包括三个基于树的模型的ML集成NID。使用CIC-IDS2017数据集进行了扩展和评估所得的ML集合NIDS。结果表明,在更新的nids规则的模型设置下(特别是在相同的NIDS重新培训请求上重新训练并更新所有三个模型),在整个仿真过程中,提出的ML集合NIDS明智地进化了,并获得了近100%的检测性能,并获得了近100%的检测性能。

通过量子神经网络的合奏技术节省资源
抽象的量子神经网络对许多应用程序具有重要的承诺,尤其是因为它们可以在当前一代的量子硬件上执行。但是,由于量子位或硬件噪声有限,进行大规模实验通常需要显着的资源。此外,模型的输出容易受到量子硬件噪声损坏的影响。为了解决这个问题,我们建议使用集合技术,该技术涉及基于量子神经网络多个实例构建单个机器学习模型。尤其是,我们实施了具有不同数据加载配置的包装和ADABOOST技术,并评估其在合成和现实世界分类和回归任务上的性能。为了评估不同环境下的潜在性能改善,我们对基于模拟的无噪声软件和IBM超导QPU进行了实验,这表明这些技术可以减轻量子硬件噪声。此外,我们量化了使用这些集成技术节省的资源量。我们的发现表明,这些方法即使在相对较小的量子设备上也能够构建大型,强大的模型。
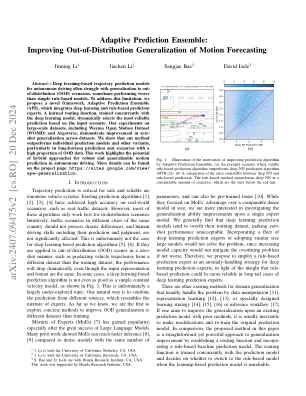
自适应预测合奏:改善运动预测的分布概括
摘要 - 自主驾驶的基于深度学习的轨迹预测模型通常会在概括到分布(OOD)方案的概括中遇到困难,有时表现比简单的基于规则的模型差。为了解决这一限制,我们提出了一个新颖的框架,自适应预测集合(APE),该集合整合了深度学习和基于规则的预测专家。学习的路由功能,与深度学习模型同时训练,根据输入方案动态选择最可靠的预测。我们在大规模数据集上进行的实验,包括Waymo Open Motion Datat(WOMD)和Argoverse,证明了整个数据集的零射击概括的改进。我们表明,我们的方法的表现优于单个预测模型和其他变体,尤其是在具有很高比例的OOD数据的长音预测和场景中。这项工作强调了混合方法在自主驾驶中进行鲁棒和可推广的运动预测的潜力。更多详细信息可以在项目页面上找到:https://sites.google.com/view/ ape-generalization。

电影推荐系统的合奏机器学习模型
摘要本文致力于评估电影推荐系统中集合机器学习模型的有效性。它探讨了各种集合方法,包括随机森林,adaboost,XGBoost,LightGBM,Catboost和梯度提升机,以增强预测用户偏好的准确性。该研究基于Movielens 100K数据集,该数据集包含1,682部电影中943位用户的100,000个评级。功能工程,数据归一化方法和迭代功能选择的应用提高了模型准确预测用户兴趣的能力。分析表明,XGBoost模型的最佳结果为0.902,与所考虑的其他模型相比,预测准确性更高。LightGBM和Catboost还显示了竞争结果,RMSE值分别为0.910和0.919。这项研究强调了综合方法在开发适应用户各种偏好和环境的建议系统中的重要性,并在该领域开辟了广泛的观点,以进一步研究。

使用计算智能和集成学习实现高效肺癌检测
肺癌是当代癌症相关死亡的主要因素,预计其将持续产生长期影响。及早发现症状对于有效治疗至关重要,这凸显了创新疗法的必要性。许多研究人员已经在这一领域开展了大量工作,但高假阳性率和高检测准确率等挑战仍然使准确诊断变得复杂。在这项研究中,我们旨在开发一种生态考虑的肺癌治疗原型模型,通过利用计算智能的最新进展来最大限度地提高资源利用率。我们还提出了一个基于医疗物联网 (IoMT) 的以消费者为中心的集成框架来实施建议的方法,为患者提供适当的护理。我们提出的方法采用逻辑回归、MLP 分类器、高斯 NB 分类器和使用 K 均值和模糊逻辑的智能特征选择来增强肺癌数据集中的检测程序。此外,通过投票分类器结合了集成学习。通过网格搜索的超参数调整提高了所提模型的有效性。通过与现有 NB、J48 和 SVM 方法的比较分析,证明了所提出的模型的性能,准确率达到 98.50%。这种方法带来的效率提升有可能节省大量时间和成本。这项研究强调了计算智能和 IoMT 在开发有效、资源高效的肺癌疗法方面的潜力。

基于整体学习的放射素学模型,用于区分胶质母细胞瘤的脑转移
目的:术前脑转移(BM)和胶质母细胞瘤(GBM)之间的区分由于它们在常规脑MRI上的相似成像特征,因此在术前具有挑战性。这项研究旨在通过基于MRI放射学数据的机器学习模型来增强诊断能力。方法:这项回顾性研究包括235例确认孤立性BM和273例GBM患者。患者被随机分配到培训(n = 356)或验证(n = 152)队列中。获得了传统的大脑MRI序列,包括T1加权成像(T1WI),对比-Enhanced_T1WI和T2加权成像(T2WI)。在所有三个序列上都描绘了脑肿瘤并分段。从人口统计学,临床和放射线数据中选择了特征。一个集成的集成机器学习模型,即弹性回归SVM-SVM模型(ERSS)和组合人口统计学,临床和放射线数据的多变量逻辑回归(LR)模型是用于预测性建模的。使用歧视,校准和决策曲线分析评估模型效率。此外,使用由47例GBM患者和43例孤立BM患者组成的独立队列进行外部验证,以评估ERSS模型的推广性。Results: The ERSS model demonstrated more optimal classification performance (AUC: 0.9548, 95% CI: 0.9337 – 0.9734 in training cohort; AUC: 0.9716, 95% CI: 0.9485 – 0.9895 in validation cohort) as compared to the LR model according to the receiver operating characteristic (ROC) curve and decision curve for the internal cohort.外部验证队列的最佳性能较低但仍然稳健(AUC:0.7174,95%CI:0.6172 - 0.8024)。具有多个分类器的集成的ERSS模型,包括弹性网,随机森林和支持向量机,产生了可靠的预测性能,并且表现优于LR方法。结论:结果表明,集成的机器学习模型,即ERSS模型,具有有效,准确的BM与GBM的术前分化的潜力,这可能会改善临床决策和脑肿瘤患者的结果。