XiaoMi-AI文件搜索系统
World File Search SystemExplain

反梯度变异和昂贵的组织假设解释了在Cricetid和Murid啮齿动物高海拔时的平行脑大小减少
为了更好地了解北美和非洲山相关啮齿动物的高海拔高度(海拔3000 m)的功能形态适应,我们使用Microct扫描来获取3D图像和3D形态计量方法来计算内骨体积和颅内长度。这是对北美克里西特小鼠物种的113个低海拔和高海拔种群(两种peromyscus物种,n = 53),以及两个部落的非洲沼泽啮齿动物(五种,五个物种,n = 49)和protaomyini(四种,n = 11)。我们检验了两个不同的假设,即高海拔种群如何在高海拔种群中有所不同:昂贵的组织假设,该假设预测大脑和内部的体积将减少以降低大脑增长和维持大脑的成本;以及脑海中的假设,该假设预测,将作为直接表型效应或适应可容纳大脑肿胀并从而最大程度地减少高度疾病的病理症状的适应性。在校正了颅尺寸的一般异态变化后,我们发现在北美的peromyscus小鼠和非洲层压板(Otomys)大鼠中,高地啮齿动物的核心体积比低较低的啮齿动物较小,与昂贵的组织假设一致。在前组中,peromyscus小鼠,不仅是从高海拔和低海拔的野生捕获的小鼠中获得的,而且还从那些在普通园生实验室条件下从高度或低海拔捕获的父母中获得了颅骨。我们在这些小鼠中的结果表明,脑大小对升高的反应可能具有强大的遗传基础,这反应了相反但对脑量的较弱的影响。这些结果可能表明,选择可以在高海拔高度下减少小型哺乳动物的大脑体积,但是需要进一步的实验来评估该结论的一般性和潜在机制的性质。

引文:Deli, E. (2022)。人工智能会有意识吗?热力学能解释智力的进化吗?J Math Techniques C
信息科学将熵解释为变量中包含的“信息量”。感官系统将空间刺激压缩为全息表示。数据压缩会增加信息密度 [22, 23, 24]。正交变换将时间上相距遥远的身份整合到主观观察者状态中 [1, 2, 11, 15, 19]。因此,虽然时间变异性提供了高度的自由度,但通过正交变形对感官数据进行变换可以为经验和记忆产生稳定性,而不受感官干扰 [15]。感知(反应)源于自我调节,恢复高熵(静息)状态。因此,静息稳态是熵的要求。由于诱发状态建立在静息电位之上,因此可以使用热力学进行分析 [3, 4, 5, 18]。

引文 Fadhel FH、Sufyan NS、Alqahtani MMJ 和 Almaamari AA (2024) 对 COVID-19 的焦虑和恐惧是解释疫苗犹豫的潜在机制
冠状病毒继续对全球公共卫生构成重大挑战,新变种的出现需要进一步努力来控制和管理病毒。在这种情况下,接种疫苗是限制 COVID-19 大流行蔓延的重要方法。然而,疫苗犹豫是阻碍遏制冠状病毒努力的最重要和最具影响力的问题之一;它与其他对疫苗接种有直接或间接影响的因素有关,包括心理因素 ( 1 , 2 )。然而,在中东和阿拉伯国家,COVID-19 疫苗犹豫与心理健康之间的关联尚未得到充分研究。因此,确定这些心理因素以制定干预措施和促进疫苗接受度非常重要 ( 3 )。多项研究发现,在 COVID-19 大流行期间,普通公众或医护人员中精神健康障碍的患病率增加,尤其是焦虑、恐惧和抑郁 ( 1 , 4 )。这些研究结果虽然有用,但并未超越疫情爆发到疫苗接种阶段,它们探讨了精神健康障碍,但并未将其与 COVID-19 疫苗犹豫直接联系起来,而且它们解释某些人为何不愿接种疫苗的能力仍然有限 (5)。研究人员一致表示,在 COVID-19 大流行期间报告的焦虑和抑郁症状的增加可能对疫苗犹豫产生影响 (6)。然而,先前针对这一问题的研究结果存在显著差异。例如,由于社交限制而每天感到焦虑、悲伤和烦躁的参与者对疫苗犹豫不决,而仅在某些日子报告同样感受的参与者犹豫不决较少 (7)。其他研究表明,报告有焦虑或抑郁症状的人对疫苗犹豫较少 (5)。虽然焦虑、恐惧和其他心理障碍似乎是疫苗犹豫的原因之一,但心理障碍和犹豫之间的关系可能是相互的。对疫苗安全性和有效性的担忧以及可能的副作用会引发疫苗犹豫和抵制。因此,犹豫不决的个人与社会直接对抗,因此会面临更多

编码多音节:长 a 拼写为 ay、a_e、ai 状态...
提供独立练习。轮到你了。仔细考虑单词 explain 的拼写。这个单词是什么?仅限学生:explain 第一步是什么?学生:点击音节。开始吧。学生:ex(tap)plain(tap)第二步是什么?学生:扩展并拼写每个音节。扩展并拼写 ex 。你是怎么拼写 /ĕĕĕ/ 的?学生:e 写下来。你是怎么拼写 /ks/ 的?学生:x 写下来。再次点击 explain 中的音节。学生:ex(tap)plain(tap)第二个音节是什么?学生:plain 扩展并拼写 plain 。你是怎么拼写 /p/ 的?学生:p 写下来。你是怎么拼写 /lll/ 的?学生:l 写下来。你必须从多个拼写模式中选择一种来拼写 /āāā/ 吗?学生:是的在 /āāā/ 的拼写位置画一个空白。plain 的最后一个音是什么?学生:/nnn/ 你如何拼写 /nnn/?学生:n 写下来。第三步是什么?学生:排除不能使用的模式。思考:哪些模式不能用来拼写普通话中的 /āāā/?给学生时间思考和回答。可能的答案:_ay 不能使用;它通常位于单词末尾,后面没有辅音第四步是什么?学生:选择剩下的一个模式来拼写声音。你能做些什么来帮助你决定选择哪种模式?学生:用两种方式写出来做吧。看看两个单词(explane 和 explain)。哪一个看起来正确?让学生讨论两个选项并选择他们认为正确的那个。正确答案的支架:解释。通过指向每个模式并说出声音来检查你的工作。这个词是什么?学生:解释

5/6年度2A任期的MARS任务
Universe Earth and Space/Forces Describe the movement of the Earth and other planets relative to the sun in the solar system Describe the movement of the moon relative to the Earth Describe the sun, Earth and moon as spherical bodies Use the idea of the Earth's rotation to explain day and night and the apparent movement of the sun across the sky Explain that unsupported objects fall towards the Earth because of the force of gravity act- ing between the Earth and the falling object I dentify the effects of air resistance,耐水性和摩擦,在移动表面之间作用的某些机制包括杠杆,皮带轮和齿轮,允许较小的

cnd考试蓝图v4.0
▪解释与网络安全攻击有关的基本术语▪描述了网络级攻击技术的各种示例■描述主机级攻击技术的各种示例▪描述了应用级攻击技术的各种示例▪描述了各种社交工程攻击技术的各种示例▪描述了各种示例示例的示例,描述了各种信息攻击技术的移动设备攻击技术的各种示例,移动设备的各种示例概述了移动设备的各种示例。 cloud-specific attack techniques ▪ Describe the various examples of wireless network-specific attack techniques ▪ Describe the various examples of Supply Chain Attack techniques ▪ Describe Attacker's Hacking Methodologies and Frameworks ▪ Understand fundamental goal, benefits, and challenges in network defense ▪ Explain Continual/Adaptive security strategy Explain defense-in-depth security strategy
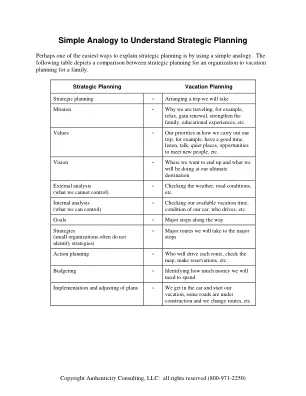
Simple Analogy to Understand Strategic Planning
Simple Analogy to Understand Strategic Planning Perhaps one of the easiest ways to explain strategic planning is by using a simple analogy. The following table depicts a comparison between strategic planning for an organization to vacation planning for a family.

生物学入学考试教学大纲
15。继承(a)将基因定义为遗传单位,并清楚地区分术语基因和等位基因(b)解释了术语的主导性,隐性,隐性,纯合,纯合,纯合,合成性,表型,表型和基因型和基因型(c)与3:1和1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1:1: (d) explain why observed ratios often differ from expected ratios, especially when there are small numbers of progeny (e) use genetic diagrams to solve problems involving monohybrid inheritance (genetic diagrams involving autosomal linkage or epistasis are not required) (f) explain co-dominance and multiple alleles with reference to the inheritance of the ABO blood group phenotypes (A, B, AB and O) and the gene等位基因(i a,i b和o)(g)描述人类性别的确定 - XX和XY染色体(H)将突变描述为基因结构的变化,例如在镰状细胞贫血中或染色体数字中,例如在诸如47个染色体的染色体数字中,该状态为47个染色体。

MCH213G_SCHOOL_ENTRANCE_FIL ...
调查结果摘要(检查一):□孩子好; no conditions identified of concern to school program activities □Conditions identified that are important to schooling or physical activity (complete sections below and/or explain here): _____________________________________________________________________________________________ ____ Allergy: □ food:_________□ insect:_______________ □ medicine:_________ □ other:____________ Type of allergic reaction: □ anaphylaxis □所需的局部反应反应:□无□肾上腺素自动注射器□其他:: _____________________________________________________________________________________活动的活动指定:: __________________________________________ ____药物。儿童服用特定健康状况的药物。□必须在学校服药和/或提供药物。____特殊饮食指定:____________________________________________________________________________________________________________

糖尿病的目标课程计划
Q:哪些器官可能会受到糖尿病的影响? 短期还是长期? In pairs come up with a list of what can be affected Short: skin (spots and infections), brain (concentration), blurred vision, headaches, UTIs Long: eyes, feet, nerves, circulation, kidneys, heart, blood vessels, reproductive health - fertility and ED Use body board or pre-drawn body on flip chart to identify the above – invite pairs to feedback Educator to explain the potential effects of long term diabetes,并将AR检查与不同的器官联系(作为任何长期效果的筛选方式,以便提早标记任何问题)Q:哪些器官可能会受到糖尿病的影响?短期还是长期?In pairs come up with a list of what can be affected Short: skin (spots and infections), brain (concentration), blurred vision, headaches, UTIs Long: eyes, feet, nerves, circulation, kidneys, heart, blood vessels, reproductive health - fertility and ED Use body board or pre-drawn body on flip chart to identify the above – invite pairs to feedback Educator to explain the potential effects of long term diabetes,并将AR检查与不同的器官联系(作为任何长期效果的筛选方式,以便提早标记任何问题)