XiaoMi-AI文件搜索系统
World File Search SystemForecast

历年径流预测
长期径流预报以日历年径流预报的形式呈现。爱荷华州苏城以上密苏里河流域(上游流域)的日历年径流预报可在此处获得。此预报在每个日历年开始后不久制定,并在每个月初更新,以显示该年历史月份的实际径流和该年剩余月份的更新预报。此预报显示来自五个增量排水区域的每月流入量(以百万英亩英尺 (MAF) 为单位),这些增量排水区域由各个系统项目定义,再加上加文斯角大坝和爱荷华州苏城之间的增量排水区域。由于距离很近,因此将大弯和兰德尔堡排水区域合并在一起。提供了加文斯角大坝以上密苏里河流域总河段和上游流域的汇总。日历年径流预报用于月度研究模拟模型中,以规划未来的系统调节,以满足整个日历年的授权项目目的。

算法鲁棒预测聚合
预测聚合结合了多个预测者的预测以提高准确性。但是,缺乏有关预测者信息结构的知识阻碍了最佳聚集。鉴于一系列信息结构,强大的预测汇总旨在与无所不知的聚合器相比,以最小的最坏情况遗憾找到聚合器。鲁棒预测的先前方法依赖于启发式观察和参数调整。我们提出了一个算法框架,用于鲁棒预测聚合。我们的框架提供了有限的信息结构家族的一般信息聚合的有效近似方案。在Arieli等人考虑的设置中。(2018),如果两个代理在二元状态下接收独立的信号,我们的框架还通过对固定器或代理报告中的分离条件施加Lipschitz条件来提供有效的近似方案。数值实验通过在Arieli等人考虑的设置中提供几乎最佳的聚合器来证明我们方法的有效性。(2018)。

加拿大制造业的市场预测
更严格的货币政策已经开始削弱需求,从而有利地影响了通货膨胀的方向。加拿大银行业务前景调查第3季度2023年表明,接受调查的制造公司的63%的净余额预计其投入价格在明年的速度比过去一年较慢(图。2)。加拿大制造商认为,这将陷入较低的产出价格通货膨胀率,净余额为43%的制造公司期望其产品的价格比过去一年较慢的速度上涨。近年来投入价格通货膨胀率提高的利润率无法维持利润率的制造商将面临挑战。在不久的将来,推动价格上涨可能会变得更加困难。


航空 APU 发动机市场 - Forecast International
Sundstrand 和 Labinal 成立 APIC,Labinal 离职。在 1989 年 7 月的巴黎航空展上,Sundstrand Corp 的 Sundstrand Power Systems 和前 Labinal Inc(现为 Snecma 的一部分)宣布他们打算成立一家合资企业,设计、生产和销售用于全球商业应用的机载 APU。合资公司 Auxiliary Power International Corp (APIC) 位于加利福尼亚州圣地亚哥,利用 Sundstrand 和 Labinal 在小型燃气涡轮发动机和辅助动力装置领域各自且互补的专业知识和经验。Sundstrand 或 Labinal 开发的 APU 由 APIC 营销、销售和支持;APU 机器的订单由 APIC 下达,APIC 又将机器的生产分包给 Sundstrand 或 Labinal。

机载反潜战传感器市场 - Forecast International
巧合的是,飞机和潜艇几乎同时开始用于军事,它们都是一小群热心人士努力的焦点,他们希望新技术带来的优势能得到认可。随着航空技术的发展,飞机很快成为对抗潜艇的有效武器,因为它们被发现特别适合执行一系列反潜任务。虽然这些任务随着时间的流逝和技术的改变而演变,但它们的基本结构保持不变。今天,空中反潜部队的基本组成仍然是远程海上巡逻机,以提供长时间的区域覆盖,舰载直升机提供点覆盖和快速反应。反潜飞机的传感器要求显然取决于任务
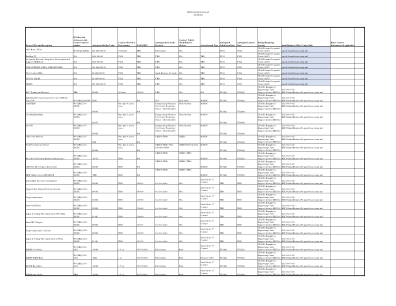
美国陆军工程兵团企业预测 2024 年 1 月 23 日
N/A $16,000,000.00 TBD TBD TBD N/A TBD Q2FY24 FY24 美国陆军工程兵团 - 西雅图区 CENWS-SB@usace.army.mil 格雷港北堤坝修复 N/A $16,000,000.00 TBD TBD TBD N/A TBD Q2FY24 FY24 美国陆军工程兵团 - 西雅图区 CENWS-SB@usace.army.mil 斯科科米什河环境。修复合同 N/A $14,000,000.00 TBD TBD TBD N/A TBD Q2FY24 FY24 美国陆军工程兵团 - 西雅图区 CENWS-SB@usace.army.mil 威科夫碎片清除和墙壁更换 N/A $80,000,000.00 TBD TBD TBD N/A TBD TBDFY24 FY24 美国陆军工程兵团 - 西雅图区 CENWS-SB@usace.army.mil 斯威诺米什维护疏浚 N/A $1,700,000.00 TBD TBD TBD N/A TBD Q2FY24 FY24 美国陆军工程兵团 - 西雅图区 CENWS-SB@usace.army.mil 酋长约瑟夫大坝激振器 N/A $14,500,000.00 TBD TBD TBD N/A TBD Q4FY24 FY24 美国陆军工程兵团 - 西雅图区CENWS-SB@usace.army.mil Quillayute Rialto Rvt 维修 N/A $2,400,000.00 TBD TBD TBD N/A TBD Q2FY24 FY24 美国陆军工程兵团 - 西雅图区 CENWS-SB@usace.army.mil UFR Barnes Blvd. J84004 - Rpr McChord Bridges CE0772 N/A $6,092,780.00 TBD TBD TBD N/A TBD TBDFY24 FY24 美国陆军工程兵团 - 西雅图区 CENWS-SB@usace.army.mil

每月预测 - 安全理事会报告
3 月份,莫桑比克将担任安理会主席国。预计莫桑比克本月将组织两项重大活动。一项是有关“妇女、和平与安全:纪念第 1325 号决议 25 周年”的公开辩论。会议将由莫桑比克外交与合作部长 Verónica Nataniel Macamo Dlhovo 主持。预计联合国妇女署、红十字国际委员会和非盟的高级代表将作简报。预计民间社会代表也将作简报。第二项重大活动将是关于“通过加强联合国与区域组织和机制的合作打击恐怖主义和防止助长恐怖主义的暴力极端主义”的高级别辩论。预计莫桑比克总统菲利佩·哈辛托·纽西将主持此次会议。预计本月中旬将举行一次关于安全部门改革的简报会,届时联合国秘书处、非盟和民间社会的代表将出席。1540 委员会主席国厄瓜多尔预计将于本月就该委员会的工作进行简报。(第 1540 号决议于 2004 年通过,旨在防止非国家行为者获取大规模毁灭性武器。)安理会视察团计划于 3 月 9 日至 12 日访问刚果民主共和国 (DRC)。还将就联合国组织刚果民主共和国稳定特派团 (MONUSCO) 举行简报会和磋商。本月的工作计划中还有其他几个非洲问题,包括:

移动区 24 财年预测
土木工程局补充计划是一项价值 440 亿美元的计划,涉及五项主要拨款,为我们所有任务区提供基础设施。任务领域包括洪水风险管理、导航和生态系统恢复。您可以选择下面的链接查看我们的团队在全国范围内实施的数千个补充项目。查看者可以按位置、国会选区、公法和项目名称筛选项目。通过单击位置标记或“更多信息”按钮,用户还可以查看即将到来的项目里程碑、项目描述和链接,以了解有关项目或实施项目的地区的更多信息。地图是一个不断发展的工具,我们鼓励您探索其功能,并欢迎您向开发团队提交建议性改进。

PEO EIS 采购预测 - Army.mil
预计履行期限(年数) 履行地点 现任 当前合同编号 项目 POC 名称 项目 POC 电子邮件 DIBS(国防综合业务系统) DIBS PM DIBS 产品组合支持 PM DIBS 产品组合支持合同 ACC-RI TBD TBD TBD TBD TBD TBD TBD 弗吉尼亚州阿灵顿 N/A N/A Sharon Bond sharon.m.bond6.civ@army.mil ACWS-VCE QLIK 许可 QLIK 仪表板软件许可 ACC-NJ 541511 独立 N 2023 年 7 月 2023 年 8 月 15 万美元以下 1 Redstone Arsenal New Tech Solutions W15QKN-22-F-0514 Kimbel Heyward kimbel.heyward.civ@army.mil ACWS-VCE Fortify 许可 HP Fortify ACC-NJ 541511 独立 Y 2023 年 7 月2023 年 9 月 15 万美元以下 1 Redstone Arsenal FedBiz IT Solutions W15QKN-22-F-0464 Kimbel Heyward kimbel.heyward.civ@army.mil ACWS-VCE Splunk 许可 Splunk ACC-NJ 541519 独立 N 2023 年 7 月 23 日 9 月 15 万美元以下 1 Redstone Arsenal Carahsoft W15QKN-22-F-0574 Kimbel Heyward kimbel.heyward.civ@army.mil ACWS-VCE Micro Focus 许可 Micro Focus ArcSight — VCE ACC-NJ 423430 独立 N 2023 年 7 月 23 日 9 月 15 万美元以下 1 Redstone Arsenal Integration Technologies Group