XiaoMi-AI文件搜索系统
World File Search SystemForge
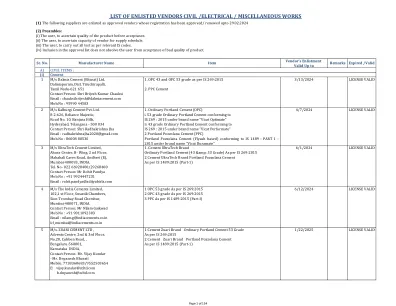
入伍供应商的清单民用 /电气 /其他作品< /div>
1碳钢锻造的管型肘部,T恤,还原器,连接器,交叉,插座,焊缝,螺纹螺纹,螺纹,联合,尺寸15NB至65 NB和1000#1000#,2000#,3000#符合相应的级别。是1239第2部分,ASTM A 105;品牌“ United Forge”品牌2碳钢对接管配件肘,T恤,尺寸为25 nb至500 nb的还原器,以及“ C”&SCH 40,SCH 80和SCH 160符合各自的成绩。是1239第2部分,ASTM A 234 WPB,为3589; Brand“ Unter Forge” Brand“ Uniter Forge” 3碳钢插座焊缝焊缝凸起的脸部(SWRF)法兰,焊接颈部凸起的脸部(WNRF)法兰,滑动的凸起(Sorf)法兰,盲凸面(BLRF)尺寸15nb至350至350和300#150#,300#,300#,300#,300#的构造,以达到300#的配料,以达到级别A105/IS 2062;品牌“ United Forge”
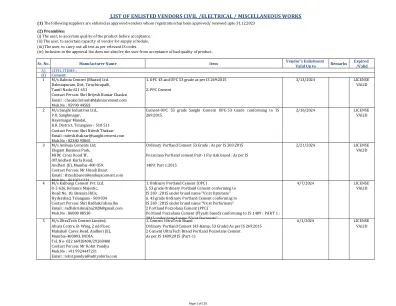
入伍供应商的清单民用 /电气 /其他作品< /div>
1碳钢锻造的管型肘部,T恤,还原器,连接器,交叉,插座,焊缝,螺纹螺纹,螺纹,联合,尺寸15NB至65 NB和1000#1000#,2000#,3000#符合相应的级别。是1239第2部分,ASTM A 105;品牌“ United Forge”品牌2碳钢对接管配件肘,T恤,尺寸为25 nb至500 nb的还原器,以及“ C”&SCH 40,SCH 80和SCH 160符合各自的成绩。是1239第2部分,ASTM A 234 WPB,为3589; Brand“ Unter Forge” Brand“ Uniter Forge” 3碳钢插座焊缝焊缝凸起的脸部(SWRF)法兰,焊接颈部凸起的脸部(WNRF)法兰,滑动的凸起(Sorf)法兰,盲凸面(BLRF)尺寸15nb至350至350和300#150#,300#,300#,300#,300#的构造,以达到300#的配料,以达到级别A105/IS 2062;品牌“ United Forge”
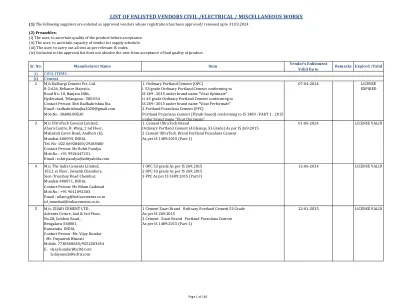
入伍供应商的清单民用 /电气 /其他作品< /div>
1碳钢锻造的管型肘部,T恤,还原器,连接器,交叉,插座,焊缝,螺纹螺纹,螺纹,联合,尺寸15NB至65 NB和1000#1000#,2000#,3000#符合相应的级别。是1239第2部分,ASTM A 105;品牌“ United Forge”品牌2碳钢对接管配件肘,T恤,尺寸为25 nb至500 nb的还原器,以及“ C”&SCH 40,SCH 80和SCH 160符合各自的成绩。是1239第2部分,ASTM A 234 WPB,为3589; Brand“ Unter Forge” Brand“ Uniter Forge” 3碳钢插座焊缝焊缝凸起的脸部(SWRF)法兰,焊接颈部凸起的脸部(WNRF)法兰,滑动的凸起(Sorf)法兰,盲凸面(BLRF)尺寸15nb至350至350和300#150#,300#,300#,300#,300#的构造,以达到300#的配料,以达到级别A105/IS 2062;品牌“ United Forge”
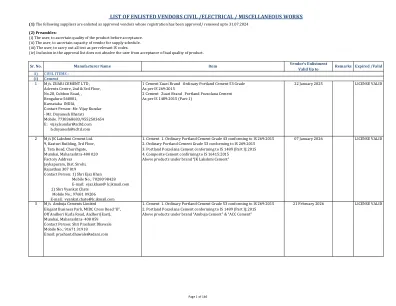
入伍供应商的清单民用 /电气 /其他作品< /div>
1碳钢锻造的管型肘部,T恤,还原器,连接器,交叉,插座,焊缝,螺纹螺纹,螺纹,联合,尺寸15NB至65 NB和1000#1000#,2000#,3000#符合相应的级别。是1239第2部分,ASTM A 105;品牌“ United Forge”品牌2碳钢对接管配件肘,T恤,尺寸为25 nb至500 nb的还原器,以及“ C”&SCH 40,SCH 80和SCH 160符合各自的成绩。是1239第2部分,ASTM A 234 WPB,为3589; Brand“ Unter Forge” Brand“ Uniter Forge” 3碳钢插座焊缝焊缝凸起的脸部(SWRF)法兰,焊接颈部凸起的脸部(WNRF)法兰,滑动的凸起(Sorf)法兰,盲凸面(BLRF)尺寸15nb至350至350和300#150#,300#,300#,300#,300#的构造,以达到300#的配料,以达到级别A105/IS 2062;品牌“ United Forge”


西北无线电台站 - 美国陆军
旧 d,aivnatlon Ntw dtilgnatfcm Wa1ter Reed 陆军医院------· Walter Reed 综合医院。 Brooke 陆军医院------------- Brooke 综合医院。 Letterman 陆军医院_ _ _ _ _ _ _ _ Letterman 综合医院。 Fitzsimons 陆军医院_ ___ • __ .__ Fitzsimons Gcnor11l Hoapita.1。 Madigan 陆军医院 ••。 ~-- -~ __ Madigan 综合医院。 William Bet1.umont 陆军医院。 __ William Beaumont 综合医院。 Valley Forge 陆军医院 _______ Valley Forge 综合医院。


H.R. 8665,超临界地热研究与发展法案
H.R.8665 指示 DOE 通过现有的地热技术办公室支持活动,建立一个具有特定超临界地热研究重点领域的计划。此外,H.R.8665 指示 DOE 为继续和扩大适用于地热能源研究前沿观测站 (FORGE) 站点的活动提供补助金。在本法案颁布一年内,DOE 应确保至少一个 FORGE 站点有能力包括在超临界条件下测试超临界地热或闭环地热系统。该法案还将鼓励 DOE 与内政部合作进行数据收集和分析,以便更好地让行业了解丰富的地热资源位于何处。


美国太平洋舰队司令部...
Nautilus Institute › uploads › 2012/09 › CINC...迄今为止在鱼雷测试计划中发现的缺陷已经 ... 由于船体腐蚀而出现。... Valley Forge (CVA 45)。按船型减少。