XiaoMi-AI文件搜索系统
World File Search SystemGeneration

人grasps Generation
在预测具有平行颚夹具的机器人抓地力已得到很好的研究并广泛应用于机器人操作任务中,但多手指手的自然人抓握生成研究的研究仍然是一个非常具有挑战性的问题。在本文中,我们建议在世界上给定3D对象产生人类的抓。我们的主要观察结果是,对手接触点和物体接触区域之间的一致性建模至关重要。也就是说,我们鼓励先前的手接触点靠近对象表面,并且对象共同的接触区域同时通过手接触。基于手动接触一致性,我们在训练人类掌握的一代模型中设计了新的目标,还设计了一个新的自我监督任务,该任务允许在测试时间之前调整掌握生成网络。我们的实验表明,人类掌握的产生显着改善,而对最先进的方法的差距很大。更有趣的是,通过在测试时间内使用自我监督的任务来优化模型,它可以帮助您在看不见和室外对象上获得更大的收益。

Frequency-constrained Co-planning of Generation and ...
摘要 - 大规模可再生能源整合会降低系统的惯性并限制频率调节。为了使频率稳定性提高,分配适当的频率端口来源对计划者构成了关键的挑战。在此内容中,我们提出了一个频率约束的协调计划模型的热单元,风电场和电池储能系统(BESS),以提供令人满意的频率支持。首先,使用同步发电机和网格连接的逆变器的动态响应来说明了修改的多机频率响应(MSFR)模型,该模型是用预设功率主管构建的。其次,频率变化(ROCOF)和频率响应功率被推论以构建频率约束。基于超平面拟合和数据分类的数据驱动的分段线性化(DDPWL)方法可用于线性化高度非线性频率响应功率。第三,将频率组合插入我们的计划模型中,而基于热力发生混合系统的协调操作的单位承诺。终于将提出的模型应用于IEEE RTS-79测试系统。结果证明了我们共同计划模型保持频率稳定性的有效性。

Greenidge Generation LLC
目前在我面前待来的是格林奇和请愿人从裁决中提出上诉。部门的工作人员没有提出裁决的上诉,而是对绿地上诉作出回应。格林奇和请愿人都对对方的上诉作出了回应。《气候领导力和社区保护法》的工作人员根据《气候领导力和社区保护法》(CLCPA)否认了格林奇的续签申请(L 2019,ch 106)。CLCPA于2019年颁布,在此不相关的一个例外,2020年1月1日生效。CLCPA§1(立法调查结果和宣言)指出:“ [c]排斥变化对经济福祉,公共卫生,自然资源和纽约环境有不利影响”,并提供了气候变化不利影响的列表(CLCPA§1[1])。法规提供:

QJE-Machine-Gearning-for-Hypothesis Generation ...- cdn
*这是芝加哥展位工作论文的修订版22-15“算法-MIC行为科学:机器学习是科学发现的工具。”我们非常感谢Alfred P. Sloan基金会,Emmanuel Roman和芝加哥大学应用人工智能中心的支持,我们感谢Stephen Billings慷慨共享数据。For valu- able comments we thank Andrei Shleifer, Larry Katz, and five anonymous refer- ees, as well as Marianne Bertrand, Jesse Bruhn, Steven Durlauf, Joel Ferguson, Emma Harrington, Supreet Kaur, Matteo Magnaricotte, Dev Patel, Betsy Levy Paluck, Roberto Rocha, Evan Rose, Suproteem Sarkar, Josh Schwartzstein, Nick Swanson, Nadav Tadelis, Richard Thaler, Alex Todorov, Jenny Wang, and Heather Yang, plus seminar participants at Bocconi, Brown, Columbia, ETH Zurich, Har- vard, the London School of Economics, MIT, Stanford, the University of California Berkeley, the University of Chicago, the University of宾夕法尼亚州,多伦多的大学,2022年的行为经济学年度会议和2022年NBER夏季研究所。对于数据和分析的宝贵帮助,我们感谢Celia Cook,Logan Crowl,Arshia Elyaderani,尤其是Jonas Knecht和James Ross。这项研究由芝加哥大学社会和行为科学机构审查委员会(IRB20-0917)审查,并被认为是豁免,因为该项目依赖于公共数据源的次要分析。所有意见和任何错误都是我们自己的。

计算机的一代第一代(1942-1955)...
– 主存储器:大型半导体存储器 – 存储:大容量磁盘 – 便携式存储:磁带、软盘 • 软件:HLL(C 和 C++)、基于 GUI 的操作系统
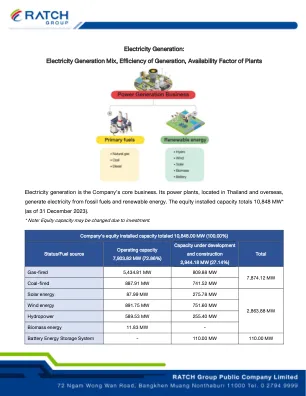
发电:发电混合物,产生效率,植物的可用性因子
发电是公司的核心业务。其位于泰国和海外的发电厂通过化石燃料和可再生能源产生电力。股权安装能力总计10,848兆瓦*(截至2023年12月31日)。*注意:由于投资,可能会更改股权。

下一个汽车一代的新电池生成
此系统允许关闭发动机以节省车辆在交通信号或交通拥堵期间暂时闲置时节省燃料。每当车辆静止不动时,所有电气设备都会从电池中接收能量,并充当额外的电池负载。每次自动停止后,发动机将重新启动,这在电池寿命周期内还会导致高速载荷阶段的数量明显更大。


人工智能一代
人工智能为当今社会带来了变革机遇,预计到 2030 年,全球市场价值将达到 4593 亿美元 1 。它是一种可应用于各个行业的平台技术,可在危机期间提供恢复能力。根据麦肯锡全球研究院的数据,预计人工智能的采用将增长,到 2030 年,约有 70% 的公司将采用人工智能技术,可能带来 13 万亿美元的额外经济产出,并使全球 GDP 每年增长 1.2%。与此同时,全球人才短缺一直被认为是人工智能扩张的关键问题。自 2016 年以来,在人工智能市场上竞争的领先国家已经设计了人工智能计划,以从小培养和留住最优秀、最聪明的人工智能人才。自 2017 年以来,中国一直是将人工智能教育集中整合并纳入 K-12 教育的最佳案例之一。尽管做出了这些努力,但全球人才短缺问题仍然存在。在此背景下,亚美尼亚有机会参与培养具有全球竞争力的人工智能研究人员和工程师。亚美尼亚在数学和自然科学方面具有强大的全球比较优势——甚至比在 ICT 方面更强。亚美尼亚 ICT 相关课程和自然科学、数学和统计学 (NSMS) 的毕业生超过全球平均水平,并胜过许多地区竞争对手。问题陈述按照目前的经济增长率,亚美尼亚需要 500 多年才能达到目前十大创新国家的水平。因此,亚美尼亚需要跨越式发展(例如,未来 20 年年增长率为 16.7%)。不利的地缘政治局势和稀缺的自然资源意味着亚美尼亚无法通过传统的经济手段实现跨越式发展。为了解决这个问题,亚美尼亚必须投资于人力资本,包括教育、医疗保健和社会领域,这占潜在资本份额的很大一部分。目前,亚美尼亚的平均劳动生产率(每小时工作 GDP)为 19.8 美元,远低于发达国家 94 美元的水平。公共教育经费投入也较低,占 GDP 的 2.14%(2021 年),远低于中高收入国家的平均水平(3.9%)。此外,只有一小部分公共支出用于高等教育,与经合组织和发达国家的较高比率形成鲜明对比。人力资本指数 (HCI) 表明,今天在亚美尼亚出生的孩子的生产力仅为他们在获得全套医疗和教育服务的情况下的生产力的 58%。因此,亚美尼亚必须大幅增加对教育的投资,以增强其人力资本,从而实现长期经济增长。亚美尼亚的人力资本指数 (HCI) 测量显示,今天在亚美尼亚出生的孩子的生产力仅为他们在获得全套医疗和教育服务的情况下的生产力的 58%。因此,亚美尼亚必须大幅增加对教育的投资,以发展其人力资本,从而实现长期经济增长。此外,与其将资源分散到多个部门,不如将精力集中在亚美尼亚具有竞争优势的细分领域,这样可以取得更好的结果。

生成.pdf
肢带型肌营养不良症 R1 型 (LGMDR1) 是一种人类常染色体隐性肌病,由钙蛋白酶 3 蛋白 (CAPN3) 缺乏引起。这种疾病缺乏有效的治疗方法和合适的模型,因此通过 CRISPR-Cas9 生成 KO 猪提供了一种更好地了解疾病行为学和开发新疗法的方法。显微注射是 CRISPR-Cas9 在猪胚胎中进行基因编辑的主要方法,但最近也有报道称使用电穿孔可以更快、更轻松地处理更多胚胎。本研究的目的是优化猪卵母细胞电穿孔,以最大限度地提高胚胎质量和突变率,从而有效生成 LGMDR1 猪模型。我们发现,与显微注射相比,使用 4 个电穿孔脉冲和双倍 sgRNA 浓度生成 CAPN3 KO 胚胎的效率最高。直接比较显微注射和电穿孔,发现胚胎发育速度和突变参数相似。我们的研究结果表明,卵母细胞电穿孔是一种比显微注射更简单、更快捷的方法,可与标准方法相媲美,为猪转基因的民主化铺平了道路。© 2022 作者。由 Elsevier Inc. 出版。这是一篇根据 CC BY 许可开放获取的文章(http://creativecommons.org/licenses/by/4.0/)。