XiaoMi-AI文件搜索系统
World File Search SystemGrus

使用复发神经网络(RNN)
在本文中,我们使用复发性神经网络(RNN),该神经网络(RNN)结合了多个门控复发单元(GRUS),长期短期记忆(LSTM)和Adam Optimizer来开发用于心脏病预测的新的混合学习模型。该提出的模型的出色精度为98.6876%。该提出的模型是GRU和RNNS模型的混合体。该模型是在Python 3.7中开发的,通过整合与Keras和Tensorflow一起工作的多个GRU和RNN作为深度学习过程的后端,并得到各种Python库的支持。使用RNN的最新模型可实现98.23%的精度,而深神经网络(DNN)的精度达到了98.5%。由于神经网络的复杂设计,在神经网络模型中具有冗余性的大量神经元以及克利夫兰不平衡的数据集,现有模型的常见缺点是准确性较差。实验,结果表明,使用RNN的拟议模型和几个具有合成少数族裔过采样技术(SMOTE)的GRU达到了最高水平的性能。完成了。这是他使用Cleveland数据集的RNN最准确的结果,并且显示出对患者心脏病的早期预测的希望。

起重机之间的系统发育关系(Gruiformes
ABSTRACR。-我使用DNA-DNA杂交方法在Gruidae(Cranes)和外部limpkin(Ara-Midae)之间产生1,200多个成对比较。基于每个细胞的3-10个复制实验,遗传距离的矩阵包括所有细胞的平均delta tm值以及起重机之间的倒数值。i选择了Delta t•作为适当的差异度量,因为在标准的实验条件下,起重机基因组中几乎所有同源的单拷贝DNA序列都足够相似。所有起重机物种对的归一百分比杂交百分比(NPH)值接近100。由于与小遗传距离的测量相关的实验变化,delta TM数据略微脱离了度量。DNA数据以最佳拟合树方法进行了分析,并通过具套品来检查内部一致性,支持传统的观点,即加冕起重机(Balearica)是现存的最古老的Gruid谱系。神秘的西伯利亚起重机(Grus leucogeranus)作为其余物种的姊妹组,分为四个密切相关的群体。Bugeranus和Anthropoides是姊妹团体。澳大利亚的三种种类(Antigone,Rubicunda和Vipio)形成了进化枝,五种主要是果皮的Grus(Grus,Monachus,Monachus,Nigricollis,Japo-Nensis和Americana)也是如此。Sandhill Crane(G. Canadensis)虽然显然是Gruine进化枝的成员,但它是一个没有近亲的旧血统。1989年3月21日收到,1989年5月18日接受。

Siang Biotiverity Expedition 2022的鸟类学结果,印度阿鲁纳恰尔邦Siang Biotiverity Expedition 2022的鸟类学结果,印度阿鲁纳恰尔邦
摘要在2022年,我们对1911 - 12年殖民地Abor Expedition期间在阿鲁纳恰尔邦的西安格山谷进行了多税调查。调查包括来自东西安格,西安格和上西安格地区的鸟类。在2月至2022年5月之间进行的鸟类调查涉及通过直接或间接目击事件在该地区报告的所有鸟类物种进行分类,包括记录在摄像机陷阱上获得的鸟类数据,作为偶然捕获和死亡或狩猎鸟类标本的偶然捕获和相遇。由于调查,总共有267个清单和94种鸟类的发声为公民科学ebird门户提供了贡献。记录了共有285种(加上一种混合动力车),并在上西安格和西安格地区的Avifauna中增加了一些。这包括26种被记录为死亡或狩猎的物种。然而,目前尚未记录1911 - 12年研究中的12种研究。重要记录包括Temminck的Tragopan Tragopan Temminckii,Blyth的Tragopan Tragopan Blythii,Sclater的Monal Lophophorus sclateri和迁移的一群常见的起重机。这项来自阿鲁纳恰尔邦人类改造的栖息地的调查将是与该州类似海拔高度的完整栖息地的丰富性相比。
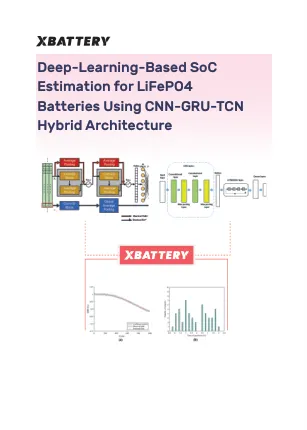
b'摘要\xe2\x80\x94准确估计充电状态 (SOC) 对于储能应用中电池管理系统 (BMS) 的有效和相对运行至关重要。本文提出了一种结合卷积神经网络 (CNN)、门控循环单元 (GRU) 和时间卷积网络 (TCN) 的新型混合深度学习模型,该模型结合了 RNN 模型特征和电压、电流和温度等非线性特征的时间依赖性,以与 SOC 建立关系。时间依赖性和监测信号之间的复杂关系源自磷酸铁锂 (LiFePO4) 电池的 DL 方法。所提出的模型利用 CNN 的特征提取能力、GRU 的时间动态建模和 TCN 序列预测强度的长期有效记忆能力来提高 SOC 估计的准确性和鲁棒性。我们使用来自 In\xef\xac\x82ux DB 的 LiFePO4 数据进行了实验,经过处理,并以 80:20 的比例用于模型的训练和验证。此外,我们将我们的模型的性能与 LSTM、CNN-LSTM、GRU、CNN-GRU 和 CNN-GRU-LSTM 的性能进行了比较。实验结果表明,我们提出的 CNN-GRU-TCN 混合模型在 LiFePO4 电池的 SOC 估计方面优于其他模型。'
b'摘要\xe2\x80\x94准确估计充电状态 (SOC) 对于储能应用中电池管理系统 (BMS) 的有效和相对运行至关重要。本文提出了一种结合卷积神经网络 (CNN)、门控循环单元 (GRU) 和时间卷积网络 (TCN) 的新型混合深度学习模型,该模型结合了 RNN 模型特征和电压、电流和温度等非线性特征的时间依赖性,以与 SOC 建立关系。时间依赖性和监测信号之间的复杂关系源自磷酸铁锂 (LiFePO4) 电池的 DL 方法。所提出的模型利用 CNN 的特征提取能力、GRU 的时间动态建模和 TCN 序列预测强度的长期有效记忆能力来提高 SOC 估计的准确性和鲁棒性。我们使用来自 In\xef\xac\x82ux DB 的 LiFePO4 数据进行了实验,经过处理,并以 80:20 的比例用于模型的训练和验证。此外,我们将我们的模型的性能与 LSTM、CNN-LSTM、GRU、CNN-GRU 和 CNN-GRU-LSTM 的性能进行了比较。实验结果表明,我们提出的 CNN-GRU-TCN 混合模型在 LiFePO4 电池的 SOC 估计方面优于其他模型。'

使用 Vision Transformers 增强 SEED-IV 数据集上的情绪分析:一项比较研究
本文介绍了一种利用深度学习模型(特别是视觉变换器 (ViT) 模型)进行情绪分类的新方法,用于分析脑电图 (EEG) 信号。我们的研究实施了一种双特征提取方法,利用功率谱密度和差分熵来分析 SEED IV 数据集。这种方法对四种不同的情绪状态进行了详细分类。最初设计用于图像处理的 ViT 模型已成功应用于 EEG 信号分析。它表现出色,测试准确率达到 99.02%,方差很小。值得注意的是,它在这方面的表现优于 GRU、LSTM 和 CNN 等传统模型。我们的研究结果表明,ViT 模型在准确识别 EEG 数据中存在的复杂模式方面具有很高的有效性。具体而言,该模型的准确率和召回率超过 98%,而 F1 分数估计约为 98.9%。该研究的结果不仅证明了基于变压器的模型在分析认知状态方面的有效性,而且还表明它们在改善人机交互系统方面具有巨大的潜力。

calrec:依次推荐的生成LLM的对比度对准
传统的推荐系统(例如矩阵分解方法)主要集中于学习共享密集的设备空间,以表示项目和用户偏好。sub-sub-sub,诸如RNN,GRUS和最近的序列模型在顺序推荐的任务中出现并出色。此任务需要了解用户历史交互中存在的顺序结构,以预测他们可能喜欢的下一个项目。基于大型语言模型(LLM)在各种任务中的成功,最近使用在庞大的文本中鉴定的LLM进行了研究,以进行顺序建议。要使用LLM进行顺序推荐,用户交互的历史记录和模型对下一个项目的预测都以文本形式表示。我们提出了CALREC,这是一种两阶段的LLM登录框架,它使用两种对比性损失和语言建模损失的混合物以两位较高的方式对经过验证的LLM进行了验证:LLM首先是在来自多个域中的数据混合物上进行的,随后是一个目标域芬特芬特登录。我们的模型极大地胜过许多最先进的基准( + 37%的回忆@1和ndcg@10中的24%),我们的系统消融研究表明,(i)两种固定阶段至关重要,当结合使用时,我们在相反的绩效中获得了相似的绩效,以及(ii)对比的一致性在目标域中有效地探索了我们的实验。