XiaoMi-AI文件搜索系统
World File Search SystemHet

荷兰的AI技术生态系统
人工智能(ai)是数字化转型的关键技术之一。荷兰已将人工智能视为解决社会挑战和提高盈利能力最有前景的技术之一。企业、投资者、科学家和政策制定者甚至将人工智能指定为具有革命性潜力的“通用技术”(GPT)。 1.2 GPT 是一种具有颠覆性潜力的技术,可以改变经济中的产品、流程和服务。先前的通用技术包括蒸汽机、电力和内燃机。 3 与仅由人类控制的系统相比,人工智能可以使流程更有效、更快速、更安全、更可持续。

重要的基因
他们给我留下了深刻的印象:关于患有严重遗传疾病的幼儿的故事。有一种新的基因疗法为长期健康的生活提供希望。有时,如果未偿还昂贵的治疗方法,则会采取众筹活动。不幸的是,治疗并不总是产生预期的。除了所有情绪外,高期望和高成本都是这些类型的信息的反复元素。这些期望并非来自任何地方。基因疗法的技术发展 - 调整DNA的医疗治疗 - 近年来彼此相互缩放,对患者可能意味着很多。高昂的成本通常是有关基因疗法的社会和政治讨论的主题。但是,技术和成本并不是决定基因疗法是否会很快改善患者生活的唯一因素。我们从多年的研究经验中知道,新技术的发展通常忽略了影响其嵌入的广泛社会因素的分析。鉴于DNA技术的可能性日益增长,公众投资不断增长,因此对此明确洞察的紧迫性正在增长。 从我们的独立立场中,我们围绕了基因治疗的研究,创新和实施的力场。 我们得出的结论是,在当前的政府政策中,许多方面都没有得到充实。 Dr. IR博士鉴于DNA技术的可能性日益增长,公众投资不断增长,因此对此明确洞察的紧迫性正在增长。从我们的独立立场中,我们围绕了基因治疗的研究,创新和实施的力场。我们得出的结论是,在当前的政府政策中,许多方面都没有得到充实。Dr. IR博士Dr. IR博士我们提请人们注意基因疗法的有限负担,我们陈述了政策制定者和政客使基因疗法成为我们公共卫生保健中负责任的地方的机会。这项研究是我们对CRISPR-CAS9和其他基因编辑技术对社会的影响的广泛探索的一部分。在我们的2023 - 2024年工作计划中,我们将继续关注这一点。我们想为该技术的负责发展做出贡献。因此,在不久的将来,您和我可以阅读越来越多的有关遗传性疾病的年轻人的信息,这些疾病因基因疗法而面临漫长而健康的生活。eefje Cuppen董事Rathenau Institute

Hall-Effect推进器(HET)
我们在这些年的大流行中问自己,我们该怎么做来帮助人民。答案非常简单,我们无事可做,只是等待灾难本身就会发生,并且自我保存是人类可以采用这种情况的最佳实践,因为我们从未为这种情况做好准备,因此我们实际上无法评估情况并获得最佳解决方案。,但幸运的是,我们现在有机会考虑种族的未来,我们可以将它们避免灭绝。现在要应对一些灭绝水平的威胁,例如大自然的大自小冲突,这可能会消灭恐龙时期发生的人口,我们必须考虑所有可能的最坏情况,以为我们的生存提供最佳解决方案。当“一旦我们确定没有其他可能出来的方式”


申请细菌轨道DNA的指南...
遗传性疾病原因越来越多地通过治疗医学专家在发芽DNA诊断后诊断。在肿瘤学护理中可以看到这种发展,例如,在这种诊断的结果下,妈妈癌的手术或药物类型的选择正在增加。de mogelijkheden van kiembaan dna-dna-diagnostiek,d.w.z。血液测试成遗传物质异常,也迅速扩展。在治疗医学专家可以申请发芽溜冰DNA诊断时提供具体的工具,临床遗传学Nederland(VKGN)已制定了非临床遗传学的指南。这是针对肿瘤学从业人员,心脏病学家,儿科医生和神经科医生的。例如,据描述,只能要求具有细菌溜冰DNA诊断的患者;健康的亲戚总是称为临床遗传学。此外,治疗专家,临床遗传学门诊和DNA诊断实验室之间的明确协议和短线很重要。该指南中的信息是在网站Arts&Genetics.nl上实际上适用的。本指南是根据卫生保健和青年检查局的建议制定的,以保证具有DNA诊断症状的患者的护理质量。
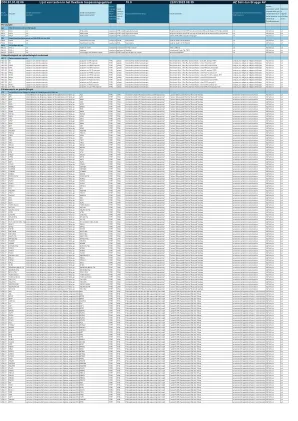
灵活应用领域测试清单(18).xlsx
HCO 2.2 ROS1 检测蛋白质表达 检测 ROS 表达 FFPE 载玻片 免疫组织化学染色 Benchmark Ultra /Ultra Plus Ventana Roche / 克隆 D4D6 方案 18 良性、恶性前期和恶性异常 AZ Sint-Jan nvt HCO 2.2 pan-TRK 检测蛋白质表达 检测 pan-TRK 表达 FFPE 载玻片 免疫组织化学染色 Benchmark Ultra /Ultra Plus Ventana Roche/ 克隆 EPR17341 方案 629 良性、恶性前期和恶性异常 AZ Sint-Jan nvt

您是否已经接种了人类乳头瘤病毒(HPV)接种疫苗?
1。Chesson HW等。在美国获取人乳头瘤病毒的估计寿命概率。性传输2014年; 11:660-664。2。Hartwig S.等。估计欧洲男性和男性的HPV相关肛门生殖器癌,癌前病变和生殖器疣的流行病学负担:与第一代HPV疫苗相比,九种价值第二代HPV疫苗的潜在增量受益。乳头状病毒res。2015; 1:90–100(附件3)。 3。 inami:变化de pratiquesmédicales。 融洽关系,col del'utérus。 rapport-fr-col_de_luterus_conisation_2022.pdf(Belgique enbonneSanté。 be)。 最后一个Acccess:04/2024。 4。 ICO/IARC HPV和癌症信息中心。 HPV及相关癌症,情况说明书2023比利时。 https://hpvcentre.net/statistics/reports/bel_fs.pdf?t=1711030349620。 上次访问:04/2024。 5。 Hoge Gezondheidsraad。 vaccinatie tegen感染Veroorzaakt门Het Humaan Papillomavirus。 布鲁塞尔:hgr; 2017。 向NR提出。 9181。 6。 ECDC2020。 欧盟国家HPV疫苗接种的指南:关注男孩,艾滋病毒感染者和9值HPV疫苗介绍(Europa.eu)。 上次访问:04/2024。 7。 Satterwhite Cl等。 美国男女之间的性传播感染:价值和发病率估计,2008年。 性传输2013年; 40:187–93。 8。 汉堡EA等。 9。2015; 1:90–100(附件3)。3。inami:变化de pratiquesmédicales。融洽关系,col del'utérus。rapport-fr-col_de_luterus_conisation_2022.pdf(Belgique enbonneSanté。be)。最后一个Acccess:04/2024。4。ICO/IARC HPV和癌症信息中心。HPV及相关癌症,情况说明书2023比利时。https://hpvcentre.net/statistics/reports/bel_fs.pdf?t=1711030349620。上次访问:04/2024。5。Hoge Gezondheidsraad。vaccinatie tegen感染Veroorzaakt门Het Humaan Papillomavirus。布鲁塞尔:hgr; 2017。向NR提出。9181。6。ECDC2020。欧盟国家HPV疫苗接种的指南:关注男孩,艾滋病毒感染者和9值HPV疫苗介绍(Europa.eu)。上次访问:04/2024。7。Satterwhite Cl等。美国男女之间的性传播感染:价值和发病率估计,2008年。性传输2013年; 40:187–93。8。汉堡EA等。9。在效果中获取因果人乳头瘤病毒(HPV)的年龄:利用模拟模型来探索HPV诱导的宫颈癌的自然史。临床感染。2017; 65:893-899。 Shi R等。 BMC Res注释。 2014; 7:544;美国成年女性中与生殖器人乳头瘤病毒感染有关的因素,NHANES,2007-2010。 10。 Bruni L等。 男性生殖器人乳头瘤病毒患病率的全球和区域估计:系统评价和荟萃分析。 柳叶刀全球卫生2023; 11:1345-1362。 11。 Hartwig S.等。 估计欧洲男性和男性的9值HPV疫苗类型的癌症,癌前病变和生殖器疣的估计。 感染剂癌。 2017; 12:19(附件1和2)。 12。 Woodman C.等。 宫颈HPV感染的自然史:未解决的问题。 nat Rev Cancer。 2007; 7:11–22。 13。 Pagliusi Sr等。 HPV疫苗简介的功效和其他里程碑。 疫苗2004; 23:569-578。 14。https:// baarmoederhalskanker。 bevolkingsonderzoek.be/fr。 上次访问:04/2024。 15。 Marth C等。 宫颈癌:ESMO临床实践GUI介绍了用于诊断,治疗和随访的诊断。 Ann Oncol 2017; 28(Suppl 4); 72-83。 16。 Joura ea等。 疫苗。 2021; 39:2800-2809。 17。 Hartwig S.等。 乳头瘤病毒res。2017; 65:893-899。Shi R等。BMC Res注释。2014; 7:544;美国成年女性中与生殖器人乳头瘤病毒感染有关的因素,NHANES,2007-2010。10。Bruni L等。 男性生殖器人乳头瘤病毒患病率的全球和区域估计:系统评价和荟萃分析。 柳叶刀全球卫生2023; 11:1345-1362。 11。 Hartwig S.等。 估计欧洲男性和男性的9值HPV疫苗类型的癌症,癌前病变和生殖器疣的估计。 感染剂癌。 2017; 12:19(附件1和2)。 12。 Woodman C.等。 宫颈HPV感染的自然史:未解决的问题。 nat Rev Cancer。 2007; 7:11–22。 13。 Pagliusi Sr等。 HPV疫苗简介的功效和其他里程碑。 疫苗2004; 23:569-578。 14。https:// baarmoederhalskanker。 bevolkingsonderzoek.be/fr。 上次访问:04/2024。 15。 Marth C等。 宫颈癌:ESMO临床实践GUI介绍了用于诊断,治疗和随访的诊断。 Ann Oncol 2017; 28(Suppl 4); 72-83。 16。 Joura ea等。 疫苗。 2021; 39:2800-2809。 17。 Hartwig S.等。 乳头瘤病毒res。Bruni L等。男性生殖器人乳头瘤病毒患病率的全球和区域估计:系统评价和荟萃分析。柳叶刀全球卫生2023; 11:1345-1362。11。Hartwig S.等。估计欧洲男性和男性的9值HPV疫苗类型的癌症,癌前病变和生殖器疣的估计。感染剂癌。2017; 12:19(附件1和2)。 12。 Woodman C.等。 宫颈HPV感染的自然史:未解决的问题。 nat Rev Cancer。 2007; 7:11–22。 13。 Pagliusi Sr等。 HPV疫苗简介的功效和其他里程碑。 疫苗2004; 23:569-578。 14。https:// baarmoederhalskanker。 bevolkingsonderzoek.be/fr。 上次访问:04/2024。 15。 Marth C等。 宫颈癌:ESMO临床实践GUI介绍了用于诊断,治疗和随访的诊断。 Ann Oncol 2017; 28(Suppl 4); 72-83。 16。 Joura ea等。 疫苗。 2021; 39:2800-2809。 17。 Hartwig S.等。 乳头瘤病毒res。2017; 12:19(附件1和2)。12。Woodman C.等。宫颈HPV感染的自然史:未解决的问题。nat Rev Cancer。2007; 7:11–22。 13。 Pagliusi Sr等。 HPV疫苗简介的功效和其他里程碑。 疫苗2004; 23:569-578。 14。https:// baarmoederhalskanker。 bevolkingsonderzoek.be/fr。 上次访问:04/2024。 15。 Marth C等。 宫颈癌:ESMO临床实践GUI介绍了用于诊断,治疗和随访的诊断。 Ann Oncol 2017; 28(Suppl 4); 72-83。 16。 Joura ea等。 疫苗。 2021; 39:2800-2809。 17。 Hartwig S.等。 乳头瘤病毒res。2007; 7:11–22。13。Pagliusi Sr等。HPV疫苗简介的功效和其他里程碑。疫苗2004; 23:569-578。14。https:// baarmoederhalskanker。bevolkingsonderzoek.be/fr。上次访问:04/2024。15。Marth C等。 宫颈癌:ESMO临床实践GUI介绍了用于诊断,治疗和随访的诊断。 Ann Oncol 2017; 28(Suppl 4); 72-83。 16。 Joura ea等。 疫苗。 2021; 39:2800-2809。 17。 Hartwig S.等。 乳头瘤病毒res。Marth C等。宫颈癌:ESMO临床实践GUI介绍了用于诊断,治疗和随访的诊断。Ann Oncol 2017; 28(Suppl 4); 72-83。 16。 Joura ea等。 疫苗。 2021; 39:2800-2809。 17。 Hartwig S.等。 乳头瘤病毒res。Ann Oncol 2017; 28(Suppl 4); 72-83。16。Joura ea等。疫苗。2021; 39:2800-2809。17。Hartwig S.等。乳头瘤病毒res。与16-26岁的女性相比,女性27-45岁的女性九级人乳头瘤病毒疫苗的不合情关心和安全性:一项开放式标签3期研究。与第一代第二代HPV疫苗相比,与第一代相关的第二代HPV疫苗相比,欧洲男性和男性在HPV相关的肛门生殖器癌,癌前病变和Geni Tal Warts的流行病学负担估计。2015; 1:90–100。 18。 tjalma W. aa。 等。 如果在患有CIN2+的女性中考虑预防性HPV疫苗接种,则在手术治疗之前或之后应给出什么值? EUR JORN INST&GYN&GRODUCT BIOLOGY。 2022; 98–101。2015; 1:90–100。18。tjalma W. aa。等。如果在患有CIN2+的女性中考虑预防性HPV疫苗接种,则在手术治疗之前或之后应给出什么值?EUR JORN INST&GYN&GRODUCT BIOLOGY。2022; 98–101。

开发和应用人工智能的伦理问题
政府必须履行各种任务,并且希望高效、有效地完成这些任务。这就是为什么它使用计算机、数据和软件、算法以及现在所谓的“AI”:人工智能。该术语之所以加引号,是因为“AI”通常不恰当地用于非真正人工智能的系统,因为它们依赖于大量的人力劳动,例如标记训练数据以及微调和纠正语言模型的体力劳动(Crawford 2021),并且并不是真正的智能,至少不是以人类的方式智能(Runciman 2023);人工智能系统可能会犯各种愚蠢的错误,因为它们缺乏常识(Russell 2019)。在本文中,我们将重点介绍政府目前正在使用的系统和算法(Van Veenstra 等人,2021a)。与基于深度学习的最先进的系统(其中“人工神经网络”在大量数据上进行训练,例如 ChatGPT)相比,这些通常是相对简单的算法。还请考虑中央司法收款机构 (CJIB) 用来估计某人是否会支付罚款的算法,以便 CJIB 可以帮助该人避免陷入(进一步)债务。 1 这种算法基于相对简单的if-then规则,例如:如果[以前的罚款已正确支付],则[发送标准提醒]。这种简单性具有诸多优势,例如在透明度方面。这样,作为开发者,你就可以

关于修改胚胎遗传 DNA 的讨论
2018年底,基因改造双胞胎露露和娜娜诞生了。他们的DNA甚至在胚胎阶段就被修改了。这种行为是现行法律法规所禁止的,包括中国在内。然而,研究员贺建奎在实验室中使用了新的 CRISPR-Cas9 技术来修改婴儿的遗传基因;这被称为种系改造。人类的这种基因增强引发了许多伦理、道德和实际问题。我们对此有何看法?将其合法用于医疗目的是否能给我们带来根除遗传性疾病的希望?我们能为子孙后代做决定吗?我们所能接受的底线在哪里?拉特瑙研究所等 11 个组织主动就这些问题发起了社会对话。基于文献研究、访谈和情景研讨会,我们概述了历史和国际背景、迄今为止的讨论以及发挥作用的社会和道德考虑。关于修改遗传 DNA 的讨论是关于我们希望给予生物技术改进的空间的更广泛讨论的一部分。我们是否了解新技术的后果和风险?它们如何改变我们对美好健康生活的形象及其界限?新技术发展各有特点,但也引发反复出现的问题。在“创造生命”这一主题下,我们对胚胎研究、人与动物结合以及生殖系改造的发展进行了研究。这一次又一次地表明,追求可行性也会使人们变得脆弱。为了确保有关修改遗传 DNA 的社会和政治辩论考虑到不同的观点和价值观,我们列出了最重要的考虑因素和论点。本报告包含有关该主题的广泛社会对话的内容和形式的十节课。因为出于对当代和后代的关心,非常谨慎地、共同地进行这一对话至关重要。自2019年10月起,全国各地的所有人都可以参加会议。

神经技术在刑法中的应用机遇与风险
ACC 前扣带皮层 aDBS 自适应深部脑刺激 ALS 肌萎缩侧索硬化症 BCI 脑机接口 CT 计算机断层扫描 DBS 深部脑刺激 DTI 扩散张量成像 EcoG 皮层脑电图 ECT 电休克疗法 EEG 脑电图 ECtHR 欧洲人权法院 ECHR 欧洲人权公约 fMRI 功能性磁共振成像 fNIRS 功能性近红外光谱 fTDC 功能性经颅多普勒 fUSI 聚焦超声成像 GVM 行为和自由限制措施 ISD 惯犯机构 MEG 脑磁图 MRI 磁共振成像 MRS 磁共振波谱 MS 多发性硬化症 PET 正电子发射断层扫描 sEEG 立体定向脑电图 SPECT 单正电子发射计算机断层扫描 Sr 荷兰刑法典 Sv 荷兰刑事诉讼法典 TBS 置于机构支配下 tDCS 经颅直流电刺激TMS经颅磁刺激TRL技术成熟度TFUS经颅聚焦超声刺激WODC科学研究与文献中心