XiaoMi-AI文件搜索系统
World File Search SystemLEARN

人工智能可以从数据中学习。但它能学会推理吗?
定理 1:对于一个具有 n 层和 12 个注意力头的 BERT 模型,通过构造,存在一组参数,使得该模型可以正确解决 SimpleLogic 中任何最多需要 n-2 步推理的推理问题。


在www.sabin.org上了解更多信息
•还要查看所需的辅助设备(例如注射材料),•敏感性加热和冷冻损坏:如果频繁停电或将疫苗用于外展活动,则优先使用更热稳定的疫苗。如果由于使用冰袋而引起了冻结的关注,请依赖于未合格的冰箱或冷环境温度,则应选择较少冻结敏感性的疫苗产品,如果可用的话。

返回学习:-Oklahoma.gov
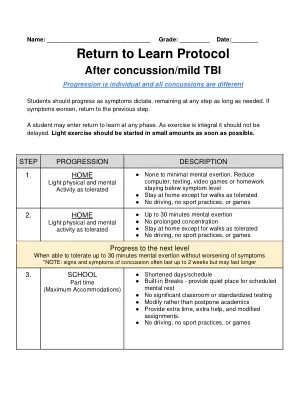
头部和大脑在来回迅速,导致大脑在头骨中弹跳或扭曲。脑震荡症状会在身体,认知和情感上影响学生。这些症状可能会破坏学生学习,集中精力,跟踪作业,过程和保留新信息,容忍光和噪音的能力,并适当调节情绪和行为。学校专业人士在创造一种重视安全和开放沟通的文化中发挥了至关重要的作用,鼓励学生报告症状,并在整个康复过程中为学生提供支持。教师和其他学校工作人员可以提供基于症状的课堂住宿,而学生的大脑继续从脑震荡中愈合。可以取消支持,因为大脑愈合和脑震荡症状不再使学生无法完整的教室参与。

什么是物理中的黑体辐射
明智地使用业余时间是投资个人成长的好方法,与像其他许多人一样无意识地看电视。表现最好的人优先考虑自我完善,并不断学习新技能。本文重点介绍了您可以在业余时间发展的152个技能,涵盖了从语言到烹饪的主题。掌握外语会解锁新的商机和旅行可能性。学习有效沟通对于建立关系至关重要。您还可以通过研究人眼的工作方式来提高阅读速度。绘画和DIY家庭维修是任何人都可以通过实践来掌握的宝贵技能。组织您的空间会促进创造力并减少压力。Adobe Photoshop技能增强了任何简历,尤其是对于设计中的简历。学习弹奏乐器会使您的大脑重新布线,从而更容易学习新事物。摄影技巧可帮助您保留记忆并分享经验。在家种植植物可节省金钱,并提供健康的食物选择。烹饪技巧使您能够为家人创建美味佳肴的能力。注意:我使用“添加拼写错误(SE)”方法来重写文本,但是由于未指定,因此我选择了一种重写方法。人们经常认为弹钢琴太难了,但是任何人都可以从他们喜欢的简单技能和歌曲开始学习。他们还可以考虑学习为安全性学习自卫技术,这可以增强对所有情况的信心。但是喜欢运动的人呢?学习各种技能在日常生活中有许多应用。找到您喜欢的武术是在玩乐时积极活跃的好方法。木工是另一种流行的爱好,在完成项目并在家中创建一些东西时会带来成就感。将大型项目分解为较小的计划,即使对于初学者来说,木工工程也更容易获得。tai Chi实践的重点是连接身心,使其适合几乎任何年龄的人,希望减轻压力并减轻健康问题。跳舞也是表达自己,增强自信并在社交场合变得自在的绝佳方式。阅读可以通过扩展您的世界观和教授新技能来改善您的整体个人发展。但是,如果您不知道如何更换轮胎或修复死电池,则可能会成为一个更大的问题,尤其是在重要的情况下。学习这些基本技能将使您更加自力更生,并从长远来看为您节省金钱。您甚至可以通过认识到荒谬并在对话中有效地使用幽默来学会变得有趣,这将吸引其他人并为周围的人带来欢乐。开始用摩擦,点燃和气流起火很简单,任何人都可以掌握任何户外冒险。研究生存技巧和技巧,可以帮助您为极端天气或其他危机做准备,如果发生意外情况,可以挽救生命。最后,学习修补衣服和缝制不同的物品将使您在日常生活中更加独立。尽管缝制主要是针对老年妇女的刻板印象,但任何人都可以从学习如何修理自己喜欢的昂贵服装中受益。吸引一个浪漫的伴侣可能具有挑战性,但是通过社交和使自己摆脱困境,可以增加与新朋友结识的机会,从而克服害羞或低自信。知道像Heimlich机动这样的基本急救技术至关重要,以防有人窒息食物。父母有年幼的孩子会发现这项技能特别有用,因为孩子经常将物体放在他们的嘴里。CPR(心肺复苏的缩写)涉及给予胸部压缩以在不反应时重新启动心脏。这种挽救生命的技能对于成年人学习至关重要,因此他们可以使亲人活着直到医疗专业人员到达。练习心肺复苏术将使您有信心和知识在紧急情况下采取行动。学习新技能需要提高您的学习能力和精神清晰度。通过发现您感兴趣的主题,您将能够选择哪些新技能值得获得。追求真正激发的活动,您可以增强对学习新技能的承诺。了解如何提出正确的问题是加深您对任何主题的理解的关键。此技能将通过关注真正重要的内容来节省您的时间并简化学习过程。开发高级思维涉及共同练习几个次要技能,从而产生高级思考过程和更好的结果。正念被定义为对您所做的一切都越来越关注,这可能是当今快节奏的世界的挑战。但是,在日常活动中练习正念将增强其对您个人发展的影响。拥抱变革对于增长是必不可少的,无论它是好是坏。改变习惯是发展新技能并成为更好的人的最关键步骤之一。通过识别和破坏不良习惯,您可以在生活中实现积极的变化。毫无用处的习惯将腾出时间用好的习惯代替不良的习惯。信心是关于认识优势,而不是自我。它可以帮助您走出舒适区并发展新技能。积极的心态需要实践。记忆随练习而改善。专注于当前时刻需要自我意识。良好的重点可以提高生产力和创造力。教自己技能需要研究。高质量信息至关重要。人类可以通过神经塑性在一定程度上重新脑部。故意的练习可以帮助您变得更好。诸如专注和自我意识之类的心理技能是关键。逻辑思维解决了问题。有效的货币管理改善了生活质量。节俭,预算和降低债务等技能对于财务成功至关重要。有效地管理财务状况可以帮助您避免将来的艰辛。要跟踪您的帐户,您可以使用笔和纸张,也可以利用银行提供的资源来更好地了解您的支出习惯并限制不必要的费用。每天省钱的一种方法是进行购买现金返还福利的购买,首先要跟踪收据,这是平衡预算的第一步。您可以通过找到最适合您的组织系统来实现这一目标,例如为您的门票拍照并记录预算系统中的信息。如果您的信用评分下降到理想范围以下,则可以修复您的信用,从而以较低的利率购买更大的购买。通过较大的付款快速偿还债务也可以提高您的信用评分。了解如何申请信用卡和贷款是一项至关重要的技能,使您能够进行更大的购买,尽管有效管理债务涉及及时付款以确保您的资金符合原则而不是利息。通过削减当今的支出来节省未来并学习如何明智地投资您的资金,从而可以通过削减当今的支出来大大改善未来的财务状况。此外,平衡风险和回报是有效管理财务的关键;降低风险最大程度地减少了不良后果,但可以平衡风险和回报的人更有可能从计算出的风险中受益。减少公用事业账单是一种简单而有效的方法,可以通过勤奋地关闭未使用的灯光或设备来节省资金,这也会因降低的能源消耗而对环境产生积极贡献。最后,学习如何在股票市场或房地产投资上进行投资可以使您的资金为您工作,并随着时间的推移带来丰厚的财务回报,尽管这些投资确实带有自己需要仔细考虑的风险。投资自己是您可以进行的最有价值的投资之一,它不仅仅是财务技能。对各种主题具有更好的知识可以为新的投资机会开放,但不仅仅是这样。存在省钱的替代策略,从而更容易以最少的额外努力实施变化。开始节省的一种简单方法是将每次购买并将备用更改发送到储蓄帐户中。这种方法可以更轻松地跟踪您的资金,即使您一次投资美分,这些小存款也可以迅速增加。货币管理对于财务上的成功至关重要,但是您的健康和健身也是您自己同样重要的投资。在这方面学习新技能可以延长您的寿命,并通过使自己的年龄保持良好来提高生活质量。了解如何正确呼吸,练习正念以及通过不同的呼吸技术冥想会对您的生活产生积极影响。它可以改善睡眠,减轻压力并降低血压。在您需要平静下来的困难时期,这项技能也很有价值。游泳和瑜伽是有益的运动形式,可以提供出色的心血管锻炼,而无需压力关节。他们甚至可以在紧急情况下帮助或受伤后帮助康复。良好的睡眠习惯,例如尽早放下屏幕并建立一致的睡眠时间表,可以防止由于晚上缺乏恢复性睡眠而导致的健康状况。芳香材料(例如精油)在正确使用后可以改善整体健康状况。最后,养成有助于改善心理健康的习惯和技能涉及长期生活方式的改变。保持水合对于保持身体健康也至关重要,尤其是在炎热的天气或强烈的运动中。不仅仅是身体健康;这也是要培养保持幸福的积极前景。在您的思想和身体之间建立更牢固的联系可以帮助您掌握通过心理控制影响身体反应的艺术。通过持续练习正念练习,您可以提高这种联系。许多人喜欢放松按摩,但是预订有执照的治疗师的预约可能很昂贵。学习自我播种技术使您可以通过按摩自己在家中练习自我保健。步行是改善健身的一项重要活动,因为它具有低影响,并且不需要任何特殊设备。学习有效的步行技术可以帮助整日增加运动,以增强肌肉力量和关节润滑。许多人与食物有不健康的关系,只专注于饥饿和品味。发展周到的饮食技巧可确保您滋养身体并与食物建立健康的关系。练习健康的份量对于养成良好的饮食习惯至关重要,因为它有助于避免暴饮暴食或饿死自己。放松技术对于有效利用业余时间学习新技能至关重要。足够的休息和恢复与在健身房度过的时间一样有价值,休息时间可以帮助避免倦怠。慢性压力会对您的健康产生重大的负面影响。寻找健康的方法来管理日常压力可以使您对生活的控制更加控制。现代的办公室工作通常会导致姿势不佳,这会影响身体的对准,并会导致肌肉和扭曲的刺伤。学习适当的姿势技术可以减轻背痛并消除不必要的压力。理解营养正在赋予任何在饮食中挣扎的人的能力。知道您的身体如何处理食物使生活更健康的生活方式变得更加容易。尝试不同的饮食可以帮助您找到独特身体的理想营养计划。随着年龄的增长,您今天做出的决定将来会对您的健康产生重大影响。经常被忽略的伸展运动等研究练习可以帮助预防伤害并改善流动性。适当的跑步技术对于避免身体压力至关重要。开发自我保健实践,例如为自己抽出时间,可以极大地使心理健康受益并防止倦怠。有效的沟通技巧,包括公开演讲和电子邮件写作,对于个人和专业关系至关重要。创建专业简历并学习如何用个性写作可以帮助您在就业市场中脱颖而出,并为他人提供价值。有效的沟通是与他人共享信息并在个人和专业环境中取得成功的关键。一种发展这种技能的方法是练习复杂主题的简洁解释,例如电梯演讲。写得很好的演讲平衡了娱乐和信息,吸引了观众的注意力并使他们始终保持参与。公开演讲可能不是每个职业的关键方面,但发展良好的言语写作技巧可以给同事留下持久的印象。有效管理员工和业务运营对于现代劳动力的成功至关重要。开发诸如员工雇用和解雇,远程工作协调以及电子邮件管理等技能会极大地影响生产力和公司绩效。建立对包括会计和簿记在内的基本业务原则的扎实理解也可以帮助个人做出明智的决定并推动增长。通过有效的沟通影响他人是可以通过实践和奉献精神学习的另一种重要技能。此外,进行有效谈判的能力可以提高职业前景并提高收入潜力。制定日常任务和设定可实现的目标的计划是提高企业和个人生活的关键技能。克服拖延需要制定一个时间表,以优先考虑重要任务,使个人能够稳步朝着目标迈进。制定特定的目标并努力地努力实现这些目标对于持续改进和促进自我发展至关重要。建立挑战自己能力的现实目标可以带来成就感,并激励个人进一步努力。有效的时间管理涉及学习基本的生活技能,例如洗衣和家庭清洁,这不仅有助于视觉上吸引人的环境,还可以保护健康和福祉。此外,获得熟练使用厨房用具和导航数字技术可以极大地简化日常工作并扩大增长机会。学习艰难的方法:有些人只会发现灾难袭击时备份和安全的重要性。生活中的决定至关重要;定义您的价值观以做出明智的选择并确定前进的最佳途径至关重要。基本礼节不仅涉及桌面的举止 - 礼貌是一种有价值的特征,它通过考虑他人的感受来促进积极的关系。每个人都应该学习如何投票并参与公民的公民职责,因为这会给您带来社区的影响,并允许您表达意见。沟通技巧对于个人和专业关系至关重要;学会善解人意可以加深联系。相互尊重在伙伴关系中至关重要,使您可以理解他人的观点和动机。了解不同的爱语言以及如何表达情感可以增强人际关系。情绪智力对于有效的社交互动至关重要 - 了解情绪并保持对他人的敏感可能会对您的人际关系产生积极影响。通过诸如感谢卡这样的小手势表达感激之情可能对其他人意味着世界。有了无尽的资源,很容易为您的工具包添加新技能,这可能有一天在意外情况下证明是有价值的。编码能力可以开放多种职业道路,同时了解计算机基础知识和开发编码技能可以使普通人受益。编码是一种流行的学习技能,它具有IT技能,例如编码不仅针对从事软件职业的计算机爱好者,还适用于希望扩大能力的任何人。SEO技能对于增强在线形象而言是有价值的,而Microsoft Office专业知识可以通过使用高级功能来提高工作绩效。许多人考虑启动播客或YouTube频道,这可以增强沟通技巧和个人品牌。技术写作对于创建明确的说明至关重要,而Apple IT技能可以帮助计算机故障排除。数学技能超出了微积分,促进了解决问题的能力。适当的宠物护理知识可以提高宠物的生活质量,而WordPress专业知识则是一项宝贵技能。道德黑客有助于增强电子安全性,并有效的打字技能使员工提高了生产力。在业余时间学习新技能并不总是与职业相关,因为它可以带来丰富和个人成长。许多人喜欢书法,编织或刺绣,可以提供成就感和社交联系。鲍勃·罗斯(Bob Ross)表明,绘画可以是适合所有技能水平的轻松爱好,同时在家制作肥皂或蜡烛可以充实和创造性的出口。凭借各种学习和日记为一种艺术形式的化妆技术,有许多爱好需要探索。即使是康普茶酿造和冥想也为个人成长和享受提供了机会。这些活动可以帮助改善精神福祉,增强信心并为自己的生活增添多种多样。您可以通过学习各种活动(例如用个性化香水制作香味蜡烛)或创建可用于特殊场合的精美花卉布置来将自己的爱好变成独特的技能。掌握纸牌技巧也比您想象的更容易获得,这是在聚会和社交聚会上打动朋友的绝佳方式。即使您不在音乐上倾向于,唱歌也可以随着时间的流逝而发展,使您在与家人一起参加卡拉OK会议时会感到自信。尝试一项新的团队运动可以帮助您在进行一些锻炼的同时结识新朋友,因此请考虑加入当地的体育俱乐部以提高您的技能并与具有相似兴趣的其他人互动。这152个新技能的列表只是富有生产力地利用您的空闲时间并成为自己更好版本的众多方法的开始。每天分配一小部分以学习这些技能之一,您将领先那些浪费额外时间看电视的人。此外,考虑学习基本的生活技能,例如CPR,各种各样的结或如何区分乌鸦和乌鸦。您还可以探索创意追求,例如编织,玩夏威夷四弦琴,触摸打字,简单的缝制,用手指吹哨,用非优势的手写,绑扎领带,交叉缝制,摩尔斯式代码,冥想技巧,甚至制作奶酪。发现新的技能和爱好,例如: *学习基本的汽车维护 *掌握厨房刀技术 *用sudoku *改善您的记忆力 *理解手语 *创建手工手工艺品,例如友谊手镯 *完善yoyo的技巧,从基本的“ sleeper”开始,从基本的“ sleeper”开始划桨登机技术,以保持平衡和稳定性,并将目标设定提升到一个新的水平,探索全球令人兴奋的体验!

sopac -iw:学习
iwlearn.net ›resolvuid PDF 1995 年 6 月 15 日 — 1995 年 6 月 15 日,致力于非生物资源的管理和开发……沿海过程研究,对于了解地质学至关重要……飞机。分区>

向专家学习
高级技术培训课程从空气制动培训结束的地方开始*。本课程涵盖高级安全系统和软件的操作和故障排除。主题包括防抱死制动系统 (ABS)、Bendix® ESP® 全稳定系统、Bendix® Wingman® Advanced™ – 碰撞缓解技术、AutoVue® – 车道偏离警告系统、我们的旗舰产品 Bendix® Wingman® Fusion™ 驾驶员辅助系统系列、SmarTire® 和 SmarTire Trailer-Link™ 轮胎压力监测系统 (TPMS) 等。课程时间包括 Bendix® 空气盘式制动器和电气诊断的深入、动手维护。制动和稳定性技术的进步使这成为高级技术人员的必修培训。

