XiaoMi-AI文件搜索系统
World File Search SystemLan

Tammy Lan CV
2017年业务周刊出版物 - “抵抗原则。如何使我们更加压力和毒化”理查德·弗里贝(361页,德语至普通话)国家地理频道亚洲2015 - 2016年 - 研究,撰写,翻译,翻译和事实核对生产纪录片的脚本 div>>
Ai-Dongle LAN/WLAN/ Wi-Fi 棒
Ai-Dongle LAN/WLAN/Wi-Fi Stick 允许 Solplanet 逆变器连接到 Solplanet Cloud 和 App。逆变器和仪表数据通过互联网收集并发送到 Solplanet Cloud,以便轻松监控光伏电站。

1.1 局域网安全为何如此重要 ................................ 5 2 ...
1 简介.................... ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 1.5.1 分布式文件存储 — 关注点 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ... ...
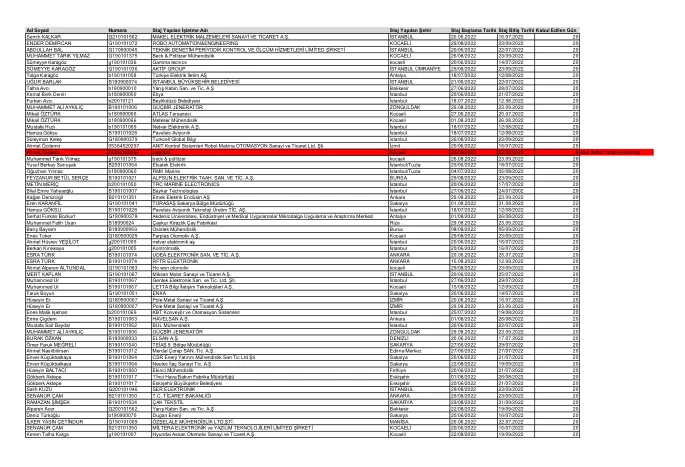
实习所在企业的名称
名字 姓氏 号码 实习公司名称 实习城市 实习开始日期 实习结束日期 接受日期 Semih KALKAR G210101562 MAKEL ELECTRICAL MATERIALS INDUSTRY AND TRADE INC.伊斯坦布尔 2022 年 6 月 20 日 2022 年 7 月 16 日 20 ENDER DEMİRCAN G190101072 ROBO AUTOMATION&ENGINEERING 科贾埃利 2022 年 8 月 29 日 2022 年 9 月 23 日 20 ABDULLAH BAL G170900045 技术检查定期控制和测量服务有限公司 伊斯坦布尔 2022 年 6 月 20 日 2022 年 7 月 22 日 20 MUHAMMET TARIK YILMAZ G190101375 Beck & Pollitzer Engineering 科贾埃利 2022 年 8 月 26 日 2022 年 9 月 23 日 20 Sümeyye Karagöz g190101036 Gamma tecnıcs 科贾埃利20/06/2022 14/07/2022 20 SÜMEYYE KARAGÖZ G190101036 ACTIVE GROUP ISTANBUL ÜMRANİYE 29/08/2022 23/09/2022 20 Tolga Karagöz b190101058 土耳其电力输送公司 安塔利亚 18/07/2022 12/08/2022 20 UĞUR BARLAK B180900074 伊斯坦布尔大都会市 伊斯坦布尔 21/06/2022 22/07/2022 20 Talha Avcı b180900010 Yarış Kabin San.和贸易。 A.Ş 巴勒克埃西尔 27/06/2022 28/07/2022 20 Kemal Berk Demir b180900050 Etiya 伊斯坦布尔 20/06/2022 21/07/2022 20 Furkan Avcı b20010121 贝伊利克杜祖市 伊斯坦布尔 18.07.2022 12.08.2022 20 MUHAMMET ALİ AYKILIÇ B190101006 GUCBIR 发电机 ZONGULDAK 29.08.2022 23.09.2022 20 Mikail OZTURK b180900066 ATLAS 船厂科贾埃利 27.06.2022 25.07.2022 20 Mikail OZTURK b180900066 Meteser Engineering Kocaeli 01.08.2022 26.08.2022 20 Mustafa Hızlı b190101069 Netvar Elektronik A.Ş.伊斯坦布尔 2022 年 7 月 18 日 2022 年 8 月 12 日 20 Hamza Göksu B190101028 Pavelsis Avionics 伊斯坦布尔 2022 年 7 月 18 日 2022 年 8 月 12 日 20 Süleyman Keleş G180900379 Turkcell Global Bilgi 伊斯坦布尔 2022 年 8 月 26 日 2022 年 9 月 23 日 20 Ahmet Özdemir 05364520297 ANIT 控制系统机器人机械自动化工贸有限公司斯蒂。 İzmit 20/06/2022 16/07/2022 20 Ahmet Özdemir 05364520297 Legrand Kocaeli 29/08/2022 23/09/2022 0 实习书上传错误。 Muhammet Tarık Yılmaz g190101375 beck & pollitzer kocaeli 08/26/2022 09/23/2022 20 Yusuf Berkay Sarıuşak B200101064 Elsatek Elektrik İstanbul/Tuzla 06/20/2022 07/18/2022 20 Oğuzhan Yılmaz b180900060 RMK Marine İstanbul/Tuzla 07/04/2022 08/05/2022 20 FEYZANUR BETUL SERÇE B190101021 ALPSUN ELECTRICAL CONTRACTING.歌唱。和贸易。作为。 BURSA 29/08/2022 23/09/2022 20METïnMeríçB200101050TRC Marine Electronicsİstanbul20/06/2022 17/07/2022 20 Bilal Emre Yahyao 210101351 EMEK Electric Industry Inc. Ankara 29.08.2022 23.09.2022 20 ErenKaranfïlG1901010101041TurasaşSakaryasakarya Regionate Sakarya Sakarya 01.08.08.2022航空电子技术生产贸易有限公司公司。伊斯坦布尔 2022 年 7 月 18 日 2022 年 8 月 12 日 20 Serhat Furkan Bozkurt G180900378 Akdeniz 大学,工业和医学应用微波应用与研究中心 安塔利亚 2022 年 8 月 1 日 2022 年 8 月 26 日 20 Muhammet Fatih Uyan B18090024 Çaykur Kirazlık 茶厂 里泽 2022 年 8 月 29 日 2022 年 9 月 23 日 20 巴里什 Bayram B180900069 Osistek Engineering 布尔萨 2022 年 8 月 8 日 2022 年 9 月 5 日 20 Enes Toker G180900029 Farplas Automotive A.Ş.科贾埃利 (Kocaeli) 29/08/2022 23/09/2022 20 Ahmet Hüsrev YEŞİLOT g200101009 netvar Elektronik AŞ 伊斯坦布尔 20/06/2022 16/07/2022 20 Berkan Kırıkkaya g200101005 控制仪伊斯坦布尔 20/06/2022 16/07/2022 20 ESRA TÜRK B190101074 UDEA ELECTRONICS SAN。和贸易。作为。安卡拉 20.06.2022 25.07.2022 20 ESRA TÜRK B190101074 RFTR ELECTRONICS 安卡拉 15.08.2022 12.09.2022 20 Ahmet Alperen ALTUNDAL G190101063 Ho won automobile kocaeli 29/08/2022 23/09/2022 20 MERT KAPLAN G190101067 Miksan Motor Industry and Trade Inc.伊斯坦布尔 20/06/2022 25/07/2022 20 Muhammed Ur B190101067 Gentek Elektronik San.和贸易。有限公司斯蒂。伊斯坦布尔 2022 年 6 月 27 日 2022 年 7 月 29 日 20 Muhammed Ur B190101067 LETTA 信息通信技术公司科贾埃利省 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Faruk Boyun G190101051 ENKA Sakarya 2022 年 6 月 20 日 2022 年 7 月 14 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 6 月 20 日 2022 年 7 月 16 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN作为。安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 202022 20 ESRA TÜRK B190101074 RFTR ELECTRONICS 安卡拉 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Ahmet Alperen ALTUNDAL G190101063 Ho won automobile kocaeli 2022 年 8 月 29 日 2022 年 9 月 23 日 20 MERT KAPLAN G190101067 Miksan Motor Industry and Trade Inc.伊斯坦布尔 20/06/2022 25/07/2022 20 Muhammed Ur B190101067 Gentek Elektronik San.和贸易。有限公司斯蒂。伊斯坦布尔 2022 年 6 月 27 日 2022 年 7 月 29 日 20 Muhammed Ur B190101067 LETTA 信息通信技术公司科贾埃利省 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Faruk Boyun G190101051 ENKA Sakarya 2022 年 6 月 20 日 2022 年 7 月 14 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 6 月 20 日 2022 年 7 月 16 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN作为。安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 202022 20 ESRA TÜRK B190101074 RFTR ELECTRONICS 安卡拉 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Ahmet Alperen ALTUNDAL G190101063 Ho won automobile kocaeli 2022 年 8 月 29 日 2022 年 9 月 23 日 20 MERT KAPLAN G190101067 Miksan Motor Industry and Trade Inc.伊斯坦布尔 20/06/2022 25/07/2022 20 Muhammed Ur B190101067 Gentek Elektronik San.和贸易。有限公司斯蒂。伊斯坦布尔 2022 年 6 月 27 日 2022 年 7 月 29 日 20 Muhammed Ur B190101067 LETTA 信息通信技术公司科贾埃利省 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Faruk Boyun G190101051 ENKA Sakarya 2022 年 6 月 20 日 2022 年 7 月 14 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 6 月 20 日 2022 年 7 月 16 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN作为。安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 202022 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统 伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN Inc.安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 202022 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统 伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN Inc.安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 20Ş Sakarya 22/08/2022 19/09/2022 20 Hüseyin BALTACI B190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20 Gökberk Aktepe B190101017 1st Air Maintenance Factory Directorate Eskişehir 01/08/2022 26/08/2022 20 Gökberk Aktepe B190101017 Eskişehir Metropolitan Municipality Eskişehir 20/06/2022 21/07/2022 20 Salih KUZU G200101046 SER ELECTRONICS ISTANBUL 29/08/2022 23/09/2022 20 SENANUR ÇAM B210101350 TC贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 20Ş Sakarya 22/08/2022 19/09/2022 20 Hüseyin BALTACI B190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20 Gökberk Aktepe B190101017 1st Air Maintenance Factory Directorate Eskişehir 01/08/2022 26/08/2022 20 Gökberk Aktepe B190101017 Eskişehir Metropolitan Municipality Eskişehir 20/06/2022 21/07/2022 20 Salih KUZU G200101046 SER ELECTRONICS ISTANBUL 29/08/2022 23/09/2022 20 SENANUR ÇAM B210101350 TC贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 20

如何使LAN现代化起作用
在过去的几年中,您的LAN流量的特征可能发生了巨大变化。您需要了解网络上的原始流量,而不仅仅是平均一天,而且在每个人都在办公室并观看最新团队与首席执行官会面时的高峰日。重要的是,您还需要确定每个应用程序/用例的要求,因为每个应用程序/用例都有不同的网络需求(生产力套件,协作工具,UP/下载,安全摄像头,恒温器等)。

快速安装指南 MRX LAN www.insys-icom.com
配置网络中的 IP 地址 仅当 IP 地址已被使用或需要不同的地址范围时,才需要更改配置网络中路由器的 IP 地址。通过新的地址即可立即访问 Web 界面。 1. 菜单接口 > IP 网络 1:在配置:网络中调整路由器的 IP 地址 2. 使用保存设置并激活配置文件保存配置文件中的设置 3. 如果未自动获取 IP 设置,则在 PC 上调整相应的 IP 设置以进行进一步配置(参见步骤 B) 4. 菜单服务 > DHCP 服务器:如果使用路由器的 DHCP 服务器,则将地址范围调整为配置网络

fidelidadelança气候变化影响中心
关于ICCC顾问委员会成员Andrew Revkin Revkin花了40年的时间来应对气候和其他可持续发展挑战,尤其是对于《纽约时报》。它于1988年开始专注于全球变暖,并且从未停止过,在北极,在亚马逊森林的北极,白宫撰写了屡获殊荣的故事。目前,它指导了一个受到赞扬的实时网络广播,维持What What,它吸引了数百万观众,并在500集中包括了一千多位客人。Butch Bacani担任NU环境计划保险领域的董事,领导联合国可持续保险原则 - 联合国和保险业之间最大的合作 - 并主持了联合国论坛到从保险到净零净的过渡。 领导了第一位全球埃斯比亚指南的创建,即弱势国家的V20可持续保险设施;并共同创建了NU可持续保险论坛的监管机构。 Insuranceerm已承认Butch是领导和塑造全球气候变化反应的最有影响力的人之一。 Julia Seixas是新大学不可或缺的老师,自2021年以来担任可持续发展的院长。 您的科学利益涵盖了能源和气候主题,重点是综合能量建模,气候脱碳选择和能源系统的适应性。 他对政府间小组对气候变化的贡献值得2007年诺贝尔和平奖。。Butch Bacani担任NU环境计划保险领域的董事,领导联合国可持续保险原则 - 联合国和保险业之间最大的合作 - 并主持了联合国论坛到从保险到净零净的过渡。领导了第一位全球埃斯比亚指南的创建,即弱势国家的V20可持续保险设施;并共同创建了NU可持续保险论坛的监管机构。Insuranceerm已承认Butch是领导和塑造全球气候变化反应的最有影响力的人之一。Julia Seixas是新大学不可或缺的老师,自2021年以来担任可持续发展的院长。您的科学利益涵盖了能源和气候主题,重点是综合能量建模,气候脱碳选择和能源系统的适应性。他对政府间小组对气候变化的贡献值得2007年诺贝尔和平奖。已有20多年了,协调对公共政策的支持,即在气候缓解领域,例如2050年到2050年的葡萄牙经济中的碳中性中立性的长期战略,已提交给UNFCCC。LuísaSchmidt是里斯本大学社会科学研究所的社会学家和协调研究员。团队成员在葡萄牙引入环境社会学。博士学位课程科学委员会成员在“气候变化和可持续发展政策”中。协调各种环境研究项目和气候变化。上一本书:“从斯德哥尔摩会议到现在的50年的环境政策”(org)(2023年)。Nuno Oliveira是一位葡萄牙生态学家和企业家,以其在生态系统和生物多样性的战略和管理方面而闻名。是NBI - 自然商业智能的执行合伙人兼首席执行官,这是一家专注于生态和可持续商业实践的咨询公司。Nuno具有强大的学术背景,并在生态,地理和商业战略方面进行了研究。在葡萄牙和国际层面都从事多个知名度的项目。也是演讲者和教育工作者,在几个研究生课程中进行讲座,并参加包括TEDX活动在内的各种会议。佩德罗·马托斯(Pedro Matos)在里斯本大学科学学院(University of Lisbon)的地理工程,地球物理学和能源和能源部地理工程,地球物理学和能源和首席研究员的助理教授。集中于调查气候建模,气候变化以及能源和可持续性的努力,从2018年到2022年,IDL调查小组在气候变化,大气层和极端过程中进行了IDL调查小组。这是EEA赠款项目的科学协调员“国家适应剧本2100-评估葡萄牙领土对21世纪气候变化的脆弱性(RNA 2100)”,并带领“区域性战略来适应Alentejo的气候变化”和“ Barcelos Municipal Climate Pailipal气候行动”。最近,他被任命为葡萄牙气候行动理事会,并且是气候变化和可持续发展政策博士学位委员会的成员以及葡萄牙健康与环境委员会。

室内用 LAN 电缆
2024 年 6 月 21 日 — 主题/规格或标准。单位数量。截止日期。履行地点。第 4 补给中队。06-1-1995-5000-0003-00。室内使用的 LAN 电缆,如下所示,项目 19 2024 年 9 月 30 日。(空中交通管制中队)。1 名参与者...

OmniAccess 4324 无线局域网交换机安装指南
本设备已经过测试,符合 FCC 规则第 15 部分对 A 类数字设备的限制。这些限制旨在为设备在商业环境中运行时提供合理的保护,防止有害干扰。本设备会产生、使用并能辐射射频能量,如果不按照说明手册进行安装和使用,可能会对无线电通信造成有害干扰。在住宅区操作本设备可能会造成有害干扰,在这种情况下,用户需要自行承担纠正干扰的费用。

企业有线和无线LAN基础架构的魔术象限
阿尔卡特朗讯企业(ALE)是这个魔术象限的利基球员。其OmnisWitch开关,OmniAccess Stellar Wireless访问点和Omnivista Management产品广泛地解决了企业网络市场。ale的投资组合包括带有网络结构细分和IT和IoT提供通用网络策略的基于云的管理选项。公司优先考虑中型企业(MSE)业务市场领域,其客户主要在政府,医疗保健和运输垂直领域中。Gartner希望ALE继续在网络安全,可见性和保证的软件能力上进行有机投资,并通过对供应商技术合作伙伴关系进行无机投资,以继续填写用于投资组合产品的解决方案。