XiaoMi-AI文件搜索系统
World File Search SystemLang

引用Gao M,Li J,Han X,Zhang B,Chen J,Lang J和Zhang Q(2024)褪黑激素对肠道微生物组和代谢组学对糖尿病认知I
作为糖尿病的中枢神经系统并发症,认知障碍逐渐受到糖尿病患者衰老的影响。痴呆是认知障碍最严重的阶段(Arvanitakis等,2019)。研究表明,在糖尿病患者中,分别在65 - 74岁和74岁以上的人中,有13.1%和24.2%的认知障碍(Feil等,2011)。基于横截面数据,在中国成年人中根据ADA标准诊断的糖尿病患病率为12.8%(Li等,2020)。随着中国人口的年龄,糖尿病认知障碍(DCI)的发生率正在上升。 然而,当前预防和治疗DCI的策略不足。 肠道是人体的第二个大脑,其中10 13〜10 14肠道微生物群的数量级生存,远远超出了体细胞总数(Gill等,2006)。 研究通过微生物脑轴通过认知功能调节DCI之间的联系与研究越来越多地得到了研究的支持。 CNS影响肠道菌群的平衡,相反,肠道微生物群的变化通过包括代谢物,神经递质,免疫反应,迷走神经等的各种机制影响CNS的功能(Ghaisas等,2016; Ansaldo等,2016; Ansaldo等,2019; Bercik et al; bercik et al。 研究以前已经强调了肠道微生物群多样性的区别,有和没有认知障碍的糖尿病患者(Zhang等,2021a)。随着中国人口的年龄,糖尿病认知障碍(DCI)的发生率正在上升。然而,当前预防和治疗DCI的策略不足。肠道是人体的第二个大脑,其中10 13〜10 14肠道微生物群的数量级生存,远远超出了体细胞总数(Gill等,2006)。研究通过微生物脑轴通过认知功能调节DCI之间的联系与研究越来越多地得到了研究的支持。CNS影响肠道菌群的平衡,相反,肠道微生物群的变化通过包括代谢物,神经递质,免疫反应,迷走神经等的各种机制影响CNS的功能(Ghaisas等,2016; Ansaldo等,2016; Ansaldo等,2019; Bercik et al; bercik et al。研究以前已经强调了肠道微生物群多样性的区别,有和没有认知障碍的糖尿病患者(Zhang等,2021a)。激素褪黑激素(MEL,N-乙酰-5-甲氧基丁胺)被松果腺分泌,并因其功能与昼夜节律的功能以及其抗氧化和抗抗炎作用而受到认可(Ahmad等人,2023年,20233; Cipolla-Neto and and and an。2型糖尿病患者和神经退行性疾病(如阿尔茨海默氏病)患者的体内水平降低(Hardeland等,2015)。最近的研究表明,通过缓解氧化应激,内质网应激和凋亡,在慢性脑灌注灌注的情况下,MEL的认知增强特性(Wang等,2023; Thangwong et al。,202222)。一些研究表明,在各种动物模型中,褪黑激素(MEL)(MEL)和微生物群 - 脑轴之间存在潜在的联系(Zhang等,2021b; He et al。,2024)。然而,肠道微生物组对DCI的贡献的确切机制尚不清楚。我们先前的研究表明,MEL通过其抗凋亡和抗炎性症对海马神经元的抗凋亡和抗炎性作用来减轻认知障碍(数据未显示)。本研究旨在研究MEL对DCI的药理作用,并通过调节肠道微生物组来阐明其神经保护机制。
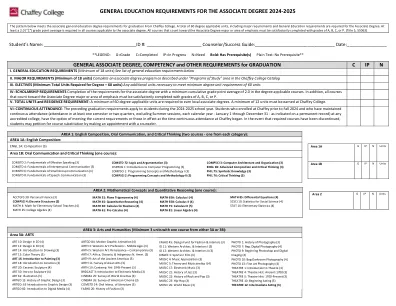
副学士学位2024-2025的通识教育要求
阿拉伯语1:Elem。现代阿拉伯语(4)阿拉伯语2:基本现代阿拉伯语(4)阿拉伯语3:Interm。现代阿拉伯语(4)阿拉伯语4:Interm。现代阿拉伯语(4)ASL 1:Elem。美国标志Lang。(4)ASL 2:Elem。美国标志Lang。(4)ASL 3:Interm。美国标志Lang。(4)ASL 4:Interm。美国标志Lang。(4)下巴1:基本普通话中文(4)下巴2:基本普通话中文(4)Chin 3:Interm。普通话中文I(4)下巴4:Interm。普通话中国II(4)下巴18:中国文明和文化(3)Engl 1C:文学概论(3)Engl 7a:创意写作:短篇小说(3)Engl 7B:创意写作:创意写作:Ficture Fiction(3)Engl 7D:创意写作:诗歌写作:诗歌(3)ENG 7E:创造性写作:非小说写作:非小说(3)

如何通过招标过程有效地为混合能源系统采购电池储能系统
IEC62933-2-1:2017-电源存储(EES)系统 - 第2-1部分:单位参数和测试方法 - 一般规格,2017年。 Epri,“ ESIC - 能源储能综合委员会”,https://www.epri.com/pages/pages/sa/epri-energ-storage-integration-council-council-esic?lang = en-usIEC62933-2-1:2017-电源存储(EES)系统 - 第2-1部分:单位参数和测试方法 - 一般规格,2017年。Epri,“ ESIC - 能源储能综合委员会”,https://www.epri.com/pages/pages/sa/epri-energ-storage-integration-council-council-esic?lang = en-us

中欧冷凝事日(CECMD)计划
CECMD计划奥地利:Silke Buhler-Paschen(Tu Vienna),Wolfgang Lang(U. Vienna)克罗地亚:Acraftia:Acraft,Denis Sundis Sunko,(U. Zagreb)Czechia:MCHALURBánek,1月)。 Milaval和经济学布达佩斯斯洛伐克:米拉夫拉特,斯洛夫特,滑动,斯洛文尼亚,斯洛文尼亚,斯洛文尼亚,斯洛维亚。 (Joear的Stefan Inst。瑞士:Johan Chang(U. Zurich))Switcherland,MID-eu倡议的负责人:Christian TeichertÖPG教堂负责人沃尔夫冈·朗(Wolfgang Lang)负责人

引用Stitzlein LM,Gangadharan A,Walsh LM,Nam D,Espejo AB,Singh MM,Patel KH,Lu Y,Su X,Ezhilarasan R,Gumin J,Singh S,Singh S,Sulman S,Sulman E,Sulman E,Lang Ff A
胶质母细胞瘤(GBM)患者的预后较差,即使有一线治疗,平均存活率也为12-15个月(1-3)。针对GBM分子定义的亚群的靶向治疗已进行了广泛的测试,但在很大程度上遇到了耐药性和生存的最小改善,促使需要开发更有效的治疗选择。对靶向疗法的抗性部分归因于整个肿瘤的异质性。 存在这种肿瘤内异质性的存在被认为是由于存在称为胶质母细胞瘤干细胞(GSC)的肿瘤亚群(4-7)所维持的。 GSC具有类似干细胞的特性,包括自我更新,这是重新植入高度适应性肿瘤的关键,该肿瘤可以逃避治疗功效(4,6)。 GBM中GSC的存在通过频繁的突变和宽松的表观遗传景观维持(6,8)。 因此,专注于GBM中的染色质调节剂失调可能会直接抑制GSC并促使持续的治疗反应。对靶向疗法的抗性部分归因于整个肿瘤的异质性。存在这种肿瘤内异质性的存在被认为是由于存在称为胶质母细胞瘤干细胞(GSC)的肿瘤亚群(4-7)所维持的。GSC具有类似干细胞的特性,包括自我更新,这是重新植入高度适应性肿瘤的关键,该肿瘤可以逃避治疗功效(4,6)。GBM中GSC的存在通过频繁的突变和宽松的表观遗传景观维持(6,8)。因此,专注于GBM中的染色质调节剂失调可能会直接抑制GSC并促使持续的治疗反应。

适用于高能物理和同步加速器应用的低增益雪崩探测器 (LGAD 和 iLGAD)
警告。访问本论文内容的前提是接受以下知识共享许可规定的使用条款:https://creativecommons.org/licenses/?lang=ca

儿童保证国家进度报告2023 -Familja
5欧洲统计局。有可能按年龄和性别划分贫困或社会排斥的人。从:https://ec.europa.eu/eurostat/databrowser/view/ilc_peps01n__custom_8426334/databrowser_842634/defele/table/table/table/table/table/table/Table/Table/ec.europa.eu/europa.eu/europa.eu/europa.eu/europa.eu/europa.eu/europa.eu/europa.eu/europa.eu/europa.eu/europa.eu/europa.eu/europa/div> 儿童(年龄小于18岁)有贫困或社会排斥的风险。 从:10/11/2023访问:https://ec.europa.eu/eurostat/eurostat/databrowser/view/tepsr_lm412__custom_8425884/defem_8425884/defeart/default/tefault/table/table/table? MT的儿童(年龄少于18岁)有贫困或社会排斥的风险。 从:https://ec.europa.eu/eurostat/databrowser/view/tepsr_lm412__custom_8426776/dabrowsom_8426776/defeart/table/table/table/table/table/table/table/table? 2021。 EU-SILC 2020:显着指标。 从:https://nso.gov.mt/wp-content/uploads/news2021_175.pdf 9 NSO访问: 2023。 EU-SILC 2022:显着指标。 从:https://nso.gov.mt/eu-silc-2022-salient-indicators/ 10中访问:https://nso.gov.mt/10这是指父母的教育程度较低,即 小于初等和下级中学教育(2011年国际标准分类的0-2级)。 11欧洲统计局。 儿童在危险中或社会的父母教育程度(年龄在0至17岁之间)。 从:10/11/2023访问:12 https://ec.europa.eu/eurostat/databrowser/view/ilc_peps60n__custom_8427363/defem_8427363/defem_8427363/default/default/table/table/table?儿童(年龄小于18岁)有贫困或社会排斥的风险。从:10/11/2023访问:https://ec.europa.eu/eurostat/eurostat/databrowser/view/tepsr_lm412__custom_8425884/defem_8425884/defeart/default/tefault/table/table/table?MT的儿童(年龄少于18岁)有贫困或社会排斥的风险。从:https://ec.europa.eu/eurostat/databrowser/view/tepsr_lm412__custom_8426776/dabrowsom_8426776/defeart/table/table/table/table/table/table/table/table?2021。EU-SILC 2020:显着指标。 从:https://nso.gov.mt/wp-content/uploads/news2021_175.pdf 9 NSO访问: 2023。 EU-SILC 2022:显着指标。 从:https://nso.gov.mt/eu-silc-2022-salient-indicators/ 10中访问:https://nso.gov.mt/10这是指父母的教育程度较低,即 小于初等和下级中学教育(2011年国际标准分类的0-2级)。 11欧洲统计局。 儿童在危险中或社会的父母教育程度(年龄在0至17岁之间)。 从:10/11/2023访问:12 https://ec.europa.eu/eurostat/databrowser/view/ilc_peps60n__custom_8427363/defem_8427363/defem_8427363/default/default/table/table/table?EU-SILC 2020:显着指标。从:https://nso.gov.mt/wp-content/uploads/news2021_175.pdf 9 NSO访问:2023。EU-SILC 2022:显着指标。 从:https://nso.gov.mt/eu-silc-2022-salient-indicators/ 10中访问:https://nso.gov.mt/10这是指父母的教育程度较低,即 小于初等和下级中学教育(2011年国际标准分类的0-2级)。 11欧洲统计局。 儿童在危险中或社会的父母教育程度(年龄在0至17岁之间)。 从:10/11/2023访问:12 https://ec.europa.eu/eurostat/databrowser/view/ilc_peps60n__custom_8427363/defem_8427363/defem_8427363/default/default/table/table/table?EU-SILC 2022:显着指标。从:https://nso.gov.mt/eu-silc-2022-salient-indicators/ 10中访问:https://nso.gov.mt/10这是指父母的教育程度较低,即小于初等和下级中学教育(2011年国际标准分类的0-2级)。11欧洲统计局。儿童在危险中或社会的父母教育程度(年龄在0至17岁之间)。从:10/11/2023访问:12 https://ec.europa.eu/eurostat/databrowser/view/ilc_peps60n__custom_8427363/defem_8427363/defem_8427363/default/default/table/table/table?


grsmbmip:1980- 2012年建模的格陵兰冰盖表面质量平衡的比较
Xavier Fettweis 1,Stefan Court 1.2,UTA Crebs-Kanzow 3,Charles Amory 1,Truo Ork,Truo Ork,Constantine J. Construction 6 Fujita 10,Paul Gierz 3,Heiko Greelzer 6.11.12,Edward Hanna 13,Akihiro Hashimoto Hashimoto 5,philip Huybright 15 Chorlots借出了LTEL 1,CORLOTS LANG 1,CORLOTS LANG。长期17.18,Jan T. M. Lenaerts 19,Glen E. Liston 20,Gerrit Lohmann 3,Sebastian H. Mernild 21.24.25,您Mikaliawicz 15,Kameswarra Modali 26,Ruth H. ,Jan Streffund 3,Broke 6的Willem,Broke 6的Michale 6,Wal 6.30的Rodeer S. W.

kgal ESPF 5完成了在萨克森 - 安哈尔特的太阳能公园集群的收购,总容量为120兆瓦
kgal gmbh&co。kgtölzerstr15 82031GrünwaldMarkus Lang市场与通信主管T +49 64143-307 Markus.lang@kgal.de Daniel Evensen通讯经理T +49 64143-555 Daniel.evensen@kggal.kgal.de