XiaoMi-AI文件搜索系统
World File Search SystemLaws

芬太尼清理:各州法律摘要
2013 年,美国缉毒局首次注意到阿片类药物芬太尼过量导致的死亡人数异常高。1 到 2019 年,每年的死亡人数惊人地增加了 12 倍:超过 36,000 人。2 芬太尼及其类似物对滥用者而言具有明显的致命性,但对旁观者而言,它们却构成了单独且独特的危险。意外过量的风险巨大,原因有很多。首先,效力:芬太尼的致死剂量仅为约 2-3 毫克,大小不超过 5-7 粒食盐。 3 第二,人体容易吸收:将芬太尼粉碎成药丸形式会产生粉尘,这些粉尘会漂浮在空气中并覆盖在物体表面,4 并且由于芬太尼可以“口服、通过鼻子或嘴巴吸入,或通过皮肤或眼睛吸收”,因此有多种途径可能意外接触。5 过量用药症状的出现仅需几分钟。

适用于本部门的基本法律汇编
本《住房和城市发展部适用法律汇编》并非美国法典的正式法律版本。本文件中的公共法律由总法律顾问办公室立法和法规办公室编纂,该办公室力求在上述日期之前尽可能使本汇编完整准确。但是,在公开发布本文件时,并未对本文件内容的准确性或完整性作出任何声明、主张、承诺或保证。美国法典的正式版本可在法律修订顾问办公室的网站 http://uscode.house.gov/ 和美国政府印刷局的网站 http://www.gpo.gov/fdsys/browse/collectionUScode.action?collectionCode=USCODE 上找到。

1995 年华盛顿州法律
235 E2SIIB 1156 非营利性教育基金会 ...................................... 794 236 HB 1186 儿童抚养费-社会保障福利 ...................................... 795 237 SIB 1195 场地勘探被排除在实质性海岸线开发之外 ........................................ 796 238 SIIII 1348 托管代理监管 ............................................. 800 239 IN liSIIB 1206 教师退休制度计划 Ill .................... 805 240 fll 1425 执法同行顾问保密 ...................................... 837 241 ilb 1858 犯罪受害者宣传办公室成立 ...................................... 838 242 Sill 2058 失业补偿-受打击承包商旅行销售商 .. ... ... .. ... ... ..... ....... ......... 839 243 SSB 5089 911 兼容性…… ...................................... 840 244 SSE 5118 退休——超额补偿的计算…… ........................ 847 245 SB 5120 执法人员和消防员退休制度——死亡福利…… ........................ 856 246 IN ESSI 5219 家庭暴力预防…… ........................ 858 247 SB 5292 天然气管道安全违规——民事处罚…… ........................ 891 248 SSI 5326 性犯罪者登记——修订…… ........................ 892 249 SSB 5400 市场利率——Consunier 信贷交易…… ........................ 897 250 SS1 5421 背景调查——修订…… ........................ 898 251 SSB 5443 财产税——授权税收的公开听证会。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。..... .... .. ... .... ............ 10 74 273 EStlB 1730 执法人员的利益仲裁 .......... 1078 274 1113 1225 许可证——修订车辆、燃油税的规定 .... 1081 275 SIlM 1237 贫困人士——获得律师帮助的权利——诉讼费和成本 ... 1100 276 SHB 1250 工业保险裁决——要求及时付款 .... 1103 277 PV ESHB 1679 私人保安和调查的专业许可 ... 1104 278 111 1359 香烟税——管理和征收 ............ 1127 279 S1iB1 1383 市政当局吞并非建制领土90 1 252 ESSB 5592 沿海螃蟹捕捞许可证 ........................................ 902 253 ESB 5613 工人赔偿令-暂停权力 ........................................ 905 254 ESSB 5629 机动车保修-修订 ........................................ 907 255 E2SSIB 5633 杂草控制 ........................................ 921 256 ESS1 5685 报废车辆 ........................................ 931 257 IN SSB 5724 州法院报告 ........................................ 947 258 SSB 5742 职业农业教师-招聘 ........................................ 950 259 SB 5748 歧视法-修订 ........................................ 952 260 SSB 5799 成人家庭保险-许可和运营 ........................................ 960 261 PV SB 5898 露天焚烧种子草 ...................................... 967 262 SB 5956 收取法院判决的法定财务义务 ........................ 969 263 ESB 5998 现场污水处理系统规则-当地豁免 ........................ 970 264 ESB 6045 退休行政人员-不损失养老金的服务 ........................ 971 265 ESItB 1046 医疗改革-修订和简化 ........................ 973 266 ESSB 5386 基本健康计划扩展 ........................................ 998 267 ES1B 1589 医疗质量保证 ........................................ 1005 268 HB 1088 性犯罪者-定义范围的澄清 ........................ 1019 269 ESHlB 1107 委员会和委员会-取消和合并 ........................ 1031 270 EHB 1173 收养支持 ............................................ 1069 271 ill 1193 交通资本设施账户 - 取消租赁费率要求 ........................................ 1074 272 ESIII 1209 华盛顿州巡逻队商业车辆安全执法 .... ... .

管理授权访问垫子的法律
更多的卵石在另一个场合,我正在一个团队工作,以管理和协调复杂的文档请求。我是一个骄傲的书呆子:我为自己获取复杂信息并将其分解成更简单,较小的组件以进行处理而感到自豪。这项工作非常适合我,我与大多数团队有着悠久而信任的关系。在一个工作会议结束时,一个新的团队成员,一个白人,他的脸上有一个关注的表情。他转向我,是房间里唯一有色人种的人,问道:“在我们离开之前,你得到了所有这些,丹诺特拉吗?”我很生气和失望。我确定他认为他在支持我,但是我唯一可以处理的是:“他为什么将自己的困惑和关注对我?为什么我被选为可能不了解这一点的人?”当我说话之前,血液涌向我的脸时,我与我一起工作了多年的另一位白人男性同事将他的手放在新来者的肩膀上,轻声摇了摇头,并向他放心,“相信我,她知道了。”在那一刻不必为自己辩护,真是一种解脱!会议结束后,捍卫我的同事为发生的事情道歉,并分享了他对我和我所做的工作的赞赏。那是我对白色盟友的第一个经历之一。
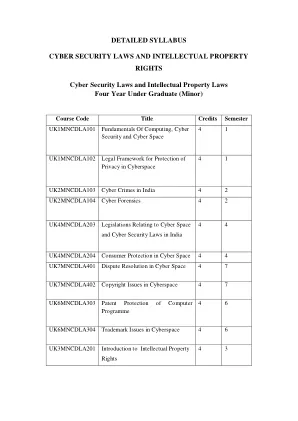
详细的教学大纲网络安全法和...
i.c. 问题论文的模式应为问题论文的模式。 部分(a) - 非常简短的答案此部分包括非常简短的答案问题。 将在第8部分中提出问题,候选人必须回答任何5个问题。 每个问题都带有2个标记,这部分总共带有10分。 5 x 2标记= 10分部分(b) - 简短答案问题该部分由简短的答案问题组成。 将在第8部分中提出问题,候选人必须回答任何5个问题。 每个问题都带有2个标记,这部分总共带有10分。 5 x 5标记= 25分部分(c) - 论文问题该部分由论文问题组成。 将在第3部分中提出问题,候选人必须回答任何2个问题。 每个问题带有12.5分。 2 x 12.5分数= 25分数检查持续时间:3小时。 最大分数:100分(WE 60分和IA 40分)[我们 - 书面考试,IA - 内部评估]i.c.问题论文的模式应为问题论文的模式。部分(a) - 非常简短的答案此部分包括非常简短的答案问题。将在第8部分中提出问题,候选人必须回答任何5个问题。每个问题都带有2个标记,这部分总共带有10分。5 x 2标记= 10分部分(b) - 简短答案问题该部分由简短的答案问题组成。将在第8部分中提出问题,候选人必须回答任何5个问题。每个问题都带有2个标记,这部分总共带有10分。5 x 5标记= 25分部分(c) - 论文问题该部分由论文问题组成。将在第3部分中提出问题,候选人必须回答任何2个问题。每个问题带有12.5分。2 x 12.5分数= 25分数检查持续时间:3小时。最大分数:100分(WE 60分和IA 40分)[我们 - 书面考试,IA - 内部评估]

2025 年生效的新法律
修订《油漆管理法》。在有关油漆管理计划的条款中,规定在提交计划后 90 天内,环境保护署 (EPA) 应批准或拒绝该计划,但需满足某些要求。规定该计划应在 2025 年 7 月 1 日之前提交。规定制造商应在 2028 年 7 月 1 日以及此后每年 7 月 1 日向该机构提交一份报告,详细说明制造商在上一日历年实施该计划的情况。将油漆和油漆相关废物以及某些属于危险废物的油漆和油漆相关废物排除在“特殊废物”的定义之外。规定属于危险废物的油漆和油漆相关废物被指定为通用废物,并受简化危险废物规则的约束。规定 EPA 应提出,污染控制委员会应采纳,
1995 年华盛顿州法律会议
235 E2SIIB 1156 非营利性教育基金会 ...................................... 794 236 HB 1186 儿童抚养费-社会保障福利 ...................................... 795 237 SIB 1195 场地勘探被排除在实质性海岸线开发之外 ........................................ 796 238 SIIII 1348 托管代理监管 ............................................. 800 239 IN liSIIB 1206 教师退休制度计划 Ill .................... 805 240 fll 1425 执法同行顾问保密 ...................................... 837 241 ilb 1858 犯罪受害者宣传办公室成立 ...................................... 838 242 Sill 2058 失业补偿-受打击承包商旅行销售商 .. ... ... .. ... ... ..... ....... ......... 839 243 SSB 5089 911 兼容性…… ...................................... 840 244 SSE 5118 退休——超额补偿的计算…… ........................ 847 245 SB 5120 执法人员和消防员退休制度——死亡福利…… ........................ 856 246 IN ESSI 5219 家庭暴力预防…… ........................ 858 247 SB 5292 天然气管道安全违规——民事处罚…… ........................ 891 248 SSI 5326 性犯罪者登记——修订…… ........................ 892 249 SSB 5400 市场利率——Consunier 信贷交易…… ........................ 897 250 SS1 5421 背景调查——修订…… ........................ 898 251 SSB 5443 财产税——授权税收的公开听证会。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。..... .... .. ... .... ............ 10 74 273 EStlB 1730 执法人员的利益仲裁 .......... 1078 274 1113 1225 许可证——修订车辆、燃油税的规定 .... 1081 275 SIlM 1237 贫困人士——获得律师帮助的权利——诉讼费和成本 ... 1100 276 SHB 1250 工业保险裁决——要求及时付款 .... 1103 277 PV ESHB 1679 私人保安和调查的专业许可 ... 1104 278 111 1359 香烟税——管理和征收 ............ 1127 279 S1iB1 1383 市政当局吞并非建制领土90 1 252 ESSB 5592 沿海螃蟹捕捞许可证 ........................................ 902 253 ESB 5613 工人赔偿令-暂停权力 ........................................ 905 254 ESSB 5629 机动车保修-修订 ........................................ 907 255 E2SSIB 5633 杂草控制 ........................................ 921 256 ESS1 5685 报废车辆 ........................................ 931 257 IN SSB 5724 州法院报告 ........................................ 947 258 SSB 5742 职业农业教师-招聘 ........................................ 950 259 SB 5748 歧视法-修订 ........................................ 952 260 SSB 5799 成人家庭保险-许可和运营 ........................................ 960 261 PV SB 5898 露天焚烧种子草 ...................................... 967 262 SB 5956 收取法院判决的法定财务义务 ........................ 969 263 ESB 5998 现场污水处理系统规则-当地豁免 ........................ 970 264 ESB 6045 退休行政人员-不损失养老金的服务 ........................ 971 265 ESItB 1046 医疗改革-修订和简化 ........................ 973 266 ESSB 5386 基本健康计划扩展 ........................................ 998 267 ES1B 1589 医疗质量保证 ........................................ 1005 268 HB 1088 性犯罪者-定义范围的澄清 ........................ 1019 269 ESHlB 1107 委员会和委员会-取消和合并 ........................ 1031 270 EHB 1173 收养支持 ............................................ 1069 271 ill 1193 交通资本设施账户 - 取消租赁费率要求 ........................................ 1074 272 ESIII 1209 华盛顿州巡逻队商业车辆安全执法 .... ... .


致命的自主武器系统(法律)
《战争法》,这些武器的使用引起了联合国参与国际安全的担忧。15 Marosaria Taddeo和Alexander Blanchard在2021年的研究重点是自主武器系统(AWS)的定义。根据对这些武器系统提出的道德和法律问题的各种方法,该定义涵盖了AWS的各个方面,并根据各州和国际组织(例如红十字会和北大西洋条约组织(北约)提供的AWS的官方定义进行了比较。此策略可能被视为改善AWS理解的不利之处,这可以帮助促进就部署条件和规则(包括使用AWS的基本考虑)达成共识。16根据克里斯·詹克斯(Chris Jenks)的一篇文章,法律已经存在了一段时间,尽管它们主要是防御性和反物质。但是,当更复杂的防御法律(例如复杂的蜂群制度蓬勃发展)时,政府肯定会创造对策。无法排除从防守式操纵到全面反攻纳入的过程。17“新形式的技术武器”一词是由克里斯汀·艾奇斯(Kristen Eichensehr)创造的,他观察到,大多数战争法则主要适用于新开发的技术,而新技术的任何新法律都应是战争法则的一小部分,适用于这种现有技术。18法律是自主武器系统,曾经被激活,完全或几乎完全没有人类控制。这些成本必须作为法律总体评估的一部分,因为这种能力有可能彻底改变警务和战争,并可能对人类福利产生重大,有害的后果。Asif Khan和Maseeh Ullah的另一篇论文回顾了有关制定国际AWS的最新著作。该研究对某些学者的担忧做出了回应,即由于多种原因,这种禁令将很难。这是一个理论基础的理论基础,以基于人权和人道主义关注的道德和法律考虑的这种禁令。在开发各种可能对人们的基本权利构成严重威胁的自动化和自动武器系统之前,作者认为,最好将此职责确立为国际标准并通过条约表达这一职责。19在他的2020年研究中,埃里克·塔尔伯特·詹森(Eric Talbot Jensen)专注于国家的观点,其中许多是由于某些常规武器公约的各州之间的讨论而公开的。 他研究了学者和非政府组织(NGO)所陈述的观点,19在他的2020年研究中,埃里克·塔尔伯特·詹森(Eric Talbot Jensen)专注于国家的观点,其中许多是由于某些常规武器公约的各州之间的讨论而公开的。他研究了学者和非政府组织(NGO)所陈述的观点,

法律的道德挑战和联合国的作用
15“武器控制和裁军。”,外交部,巴基斯坦,2024年7月12日,https://mofa.gov.pk/arms-control-and-disarmament。