XiaoMi-AI文件搜索系统
World File Search SystemLimits

COVID-19 与经济增长模式的局限性 - ncpag
在新冠疫情期间,威权主义和新自由主义暴露了全球化市场中自由化和私有化肆无忌惮的背景下,以经济增长模式为基础的发展理论的局限性。病毒使本已饱受全球贸易战和独裁者崛起困扰的人民和经济陷入瘫痪。然而,疫情对人民和国家的影响尤为严重,加剧了国家内部和国家之间的不平等和贫困。菲律宾总统罗德里戈·杜特尔特在低通胀的体制下乘上了经济增长的浪潮,该国享有所谓的“强劲的宏观经济基本面”。然而,新冠疫情彻底改变了全球格局,并揭示了市场失灵。几十年来,菲律宾经济首次萎缩至最低点,目前正陷入衰退。该国在努力控制新冠病毒的同时,实施了最长、最严格的封锁。在危机中,杜特尔特加大了镇压措施,但在刺激性支出方面却吝啬。本文将探讨政府在政治、财政、货币和人力发展措施方面应对疫情的举措。

有限效率量子监测的感知限制
量子理论基于这样一个事实:系统的量子态编码了所有可能的测量预测以及系统的后验演化。然而,一般来说,不同的代理可能会根据他们对系统的了解,为同一系统分配不同的状态。系统物理状态的完整信息等同于纯态,在数学上由希尔伯特空间中的单位向量建模。相比之下,混合状态对应于系统缺乏完整的描述,这要么是由于准备过程中的不确定性,要么是由于系统与次级系统相关。在本文中,我们讨论了不同知识水平的观察者对系统的感知有何不同。具体而言,我们量化了两个代理在通过连续测量获取信息时对同一系统提供的有效描述有多大差异。考虑一个受监控的量子系统,即一个在时间上被连续测量的系统。假设全知代理 O 知道系统中发生的所有交互和测量。特别是,她可以访问所有测量结果


第10章商品衍生位置限制和...
(4)MIFID RTS 21澄清说,如果非金融实体的商业活动的性质或价值发生重大变化,或者其商品衍生品中的交易活动发生了重大变化,则非金融实体应通知FCA。义务与变更有关的描述与非金融实体的交易的性质和价值相关,并在商品衍生工具中持有的职位及其在其已提交的职位限制限制申请中的经济上等效的OTC合同。在这种情况下,如果非金融实体打算继续使用豁免,则必须提交新申请。

对负CO2排放的生物物理和经济限制
皮特·史密斯1 *,史蒂文·J·戴维斯2,菲利克斯·克鲁特齐格3,4,萨宾·福斯3,扬·米克斯3,5,6,贝诺伊特·加布里埃尔7,8,埃茨希·盖托9,埃茨西·盖托9,罗伯特·杰克逊·杰克逊·杰克逊·韦特尔·韦特尔·范·沃里恩12,13 , David 15 , Glen Peters 19 , Robbie Andrew 19 , Volker Krestha 20 , Pierre Friedlingstein 21 , Thomas Gasser 16,22 , Arnulf Grübler 15 , Wolfgang K. Heidu 23 , Matthiaas Jonas 15 , Chris D. Jones 24 , Florian Kraxner , José Roberto Morera 26 , Nebojsa Nakcenovic 15 , Michael Obeersteiner 15 ,Anand Patwardhan 27,Mathis Roner 15,Ed Rubin 28,Ayyob Sharifi 29,AsbjørnTorvanger 19,Yoshiki Yamagata 30,Jae Edmonds和Cho Yonssung 32 32 32

测试大语言模型的认知极限
要解释,列出Cheryl生日的可能日期以网格格式,如图1所示。在这个网格中,阿尔伯特被告知谢丽尔的生日那个月,而伯纳德则在谢丽尔的生日那天被告知。因此,如果谢丽尔(Cheryl)的生日是5月19日,艾伯特(Albert)会被告知“五月”,而伯纳德(Bernard)会被告知“ 19”。但被告知“ 19”将允许伯纳德立即获得正确的答案,因为在一个月的第19天只有一个可能的日期。同样,如果谢丽尔(Cheryl)的生日是6月18日,伯纳德(Bernard)可能会立即达到正确的答案,因为只有一个可能的日期属于一个月的第18天。阿尔伯特的说法“我确定伯纳德都不知道”,这是很有意义的,因为它告诉我们,阿尔伯特能够排除5月19日和6月18日。如果他被告知“五月”或“六月”,他就无法将他们排除在外。因此,阿尔伯特(Albert)可以断言伯纳德(Bernard)不知道这一事实意味着他(阿尔伯特(Albert))并未被谢丽尔(Cheryl)告知“五月”或“六月”。

信息时代的小农农业:局限性与机遇
联合国最近的预测显示,为了满足世界不断增长的人口的营养需求,到 2050 年粮食产量需要翻一番。这一增长的关键推动因素是小农家庭农场,它们是全球农业 (AG) 生产的骨干。为了满足这种日益增长的需求,小农农场需要在任务管理和协调、作物和牲畜监测以及高效的农耕实践方面取得重大进展。信息和通信技术 (ICT) 将在这些进步中发挥关键作用,它提供集成的、价格合理的网络物理系统 (CPS),可以纵向测量、分析和控制 AG 操作。在本文中,我们在此类 AG-CPS 的设计和集成方面取得了进展。我们首先根据农场互联网使用的流量分析来描述小农农业的信息和通信技术需求。我们的研究结果为端到端 AG-CPS(称为 FarmNET)的设计和集成提供了信息,它提供了(i)用于多传感器 AG 数据收集和融合的强大控制机制,(ii)用于无处不在的农场连接的广域异构无线网络,(iii)用于农场数据分析的算法和模型,可根据收集到的农业数据生成可操作的信息,以及(iv)用于自主、主动农业的控制机制。

艺术治疗与神经科学:证据、局限性和误区
尽管对艺术治疗工作原理的机械理解仍然有限,但艺术治疗有效性的证据基础仍在不断增长。通过神经科学的视角,增加我们对艺术治疗如何以及为何起作用的理解的一个有希望的途径是。基于神经科学的艺术治疗方法为提高对神经过程的理解提供了机会,这些过程是艺术治疗过程中感知、认知、情感和行为之间复杂相互作用的基础。了解治疗变化如何发生可以改善治疗并为患者带来更好的结果。然而,将艺术治疗和心理学理论直接与神经反应联系起来可能很棘手。这一观点的目的是概述神经可塑性、镜像系统和内感受等神经生物学概念在艺术治疗实践中的当前证据和局限性,并提供有关仍在临床实践中积极使用的过时概念的最新信息。然后,可以使用对当前科学知识库的批判性分析和理解来指导艺术治疗实践,并支持基于假设的研究的发展,以确定推动艺术治疗干预观察到的效果的主要机制。
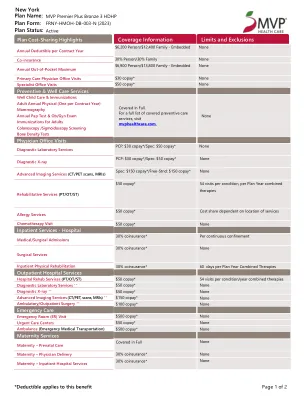
计划状态:覆盖信息限制和排除...
本计划概述旨在提供保险范围的一般概述。如果本文件与您的保险证书 (COC)、附表和任何适用的附加条款有任何冲突,则以您的 COC、附表和附加条款为准。如需了解计划详情,请致电 1-800-TALK-MVP (825-5687) 或访问 mvphealthcare.com。

SP-308:新建筑的氯化物阈值和限值
氯化物阈值的概率处理 Carmen Andrade、Fabiano Tavares、Nuria Rebolledo、David Izquierdo 摘要:众所周知,氯化物阈值是一个变量值,取决于与水泥化学、混凝土特性和外部环境相关的许多参数。已经进行了多项研究,试图找到可以预测特定混凝土阈值的一般规律。虽然这个目标是解决问题最严格的方法,但在实际工作中测量所有影响参数似乎非常困难。另一种方法是以合理的方式分析变异性。这是在当前工作中根据新模型代码 2010 中提出的最新方法完成的,该方法考虑了确定性到概率模型来预测使用寿命。首先从其渐进性的角度分析脱钝事件,旨在确定氯化物阈值变化,其统计分布已在实验室中测量,并且已显示与实际结构中的观察结果一致。此外,还对脱钝概率的含义及其从结构角度的考虑进行了评论。最后提到了一种加速测试方法,该方法能够在短于 4 至 8 周的测试时间内确定氯化物阈值。使用加速测试评估仅含波特兰水泥和含矿渣波特兰水泥的样品的测试。关键词:氯化物;混凝土;腐蚀;统计;测试;阈值。