XiaoMi-AI文件搜索系统
World File Search SystemMRI


游戏者MRI
a Translational Imaging in Neurology (ThINk) Basel, Department of Medicine and Biomedical Engineering, University Hospital Basel and University of Basel, Basel, Switzerland b Neurologic Clinic and Policlinic, Departments of Medicine, Clinical Research and Biomedical Engineering, University Hospital Basel and University of Basel, Basel, Switzerland c Research Center for Clinical Neuroimmunology and Neuroscience Basel, University Hospital Basel and巴塞尔大学,巴塞尔大学,瑞士,D数字技术与创新,西门子卫生仪,新泽西州普林斯顿,美国E e放射物理学部,放射科学系,巴塞尔大学医院,巴塞尔大学,巴塞尔大学,瑞士,瑞士放射科。 Polytechnique f´Ed´eRalede lausanne,瑞士,瑞士I医学图像分析实验室,生物医学成像中心(CIBM),洛桑大学,洛桑大学,洛桑大学J.巴塞尔,Allschwil,瑞士l放射科学系,大卫·盖芬医学院,加利福尼亚大学,加利福尼亚州洛杉矶分校,美国加利福尼亚州洛杉矶分校,分子,分子和介入放射学系,美国纽约州西奈山的伊卡恩医学院临床分析的AI,Covera Health,纽约,纽约州,美国,美国

功能MRI
什么是功能性MRI(fMRI)?MRI代表磁共振成像。MRI机器使用大型磁铁拍摄孩子身体内部的照片。MRI不使用辐射。功能性MRI是一项在特定活动中为大脑拍照的考试。这些活动范围从物理运动(例如手指敲击或攻击)到语言任务。为什么要进行考试?进行此考试以查看大脑中某些关键功能发生的位置。期望什么,因为MRI使用强大的磁铁来创建图像,我们必须遵循严格的安全过程。为了确保您的孩子安全,我们将要求您回答安全问题列表,并使用手持金属探测器。如果您的孩子不需要药物入睡参加考试,则一位父母或监护人可能与您的孩子一起在MRI套件中。您将被要求完成与孩子相同的筛查过程。制定其他兄弟姐妹可能会有所帮助。出于安全原因,如果您怀孕,您将不允许陪伴您的孩子。准备孩子是这项研究成功的关键。为了帮助您的孩子做好准备,我们的孩子生活专家将帮助您缓解您的孩子的恐惧和焦虑。请让工作人员知道您是否对儿童生活咨询感兴趣,无需额外费用。MRI考试的成功取决于孩子躺在MRI隧道内的能力。机器在拍照时会发出不同类型的噪音。此页面上找到的MRI准备视频可能有助于为您的孩子准备:https://www.texaschildrens.org/departments/mri-metage-maket-resnance-imigance-imaging

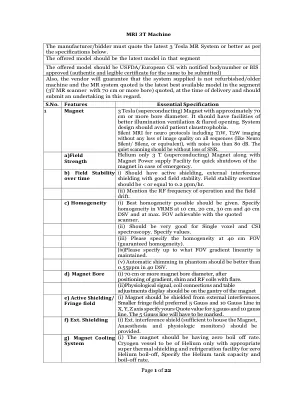
MRI 3T机器
i)应具有具有良好场地稳定性的主动屏蔽,外部干扰屏蔽。场稳定的加班应为<或等于0.2 ppm/hr。(ii)提及RF操作频率和场漂移。c)同质性(i)应提供最佳同质性。在10 cm,20 cm,30 cm和40 cm DSV的VRMS中指定同质性,最大。可以用引用的扫描仪来实现。(ii)对于单素体素和CSI光谱应该非常好。指定值。(iii)请在40 cm FOV(保证同质性)处指定同质性。(iv)请指定保持哪些FOV梯度线性。(v)幻影中的自动弹跳应优于40 dsv中的0.55ppm。d)磁铁孔(i)70厘米或更多的磁铁孔直径,梯度,垫片和射频线圈用耀斑定位后。(ii)生理信号,线圈连接和表调整应显示在磁铁的龙门上e)主动屏蔽/条纹场 div>
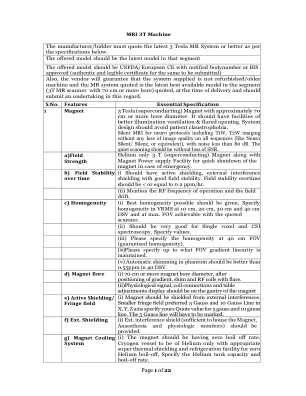
MRI 3T机器
i)应具有具有良好场地稳定性的主动屏蔽,外部干扰屏蔽。场稳定的加班应为<或等于0.2 ppm/hr。(ii)提及RF操作频率和场漂移。c)同质性(i)应提供最佳同质性。在10 cm,20 cm,30 cm和40 cm DSV的VRMS中指定同质性,最大。可以用引用的扫描仪来实现。(ii)对于单素体素和CSI光谱应该非常好。指定值。(iii)请在40 cm FOV(保证同质性)处指定同质性。(iv)请指定保持哪些FOV梯度线性。(v)幻影中的自动弹跳应优于40 dsv中的0.55ppm。d)磁铁孔(i)70厘米或更多的磁铁孔直径,梯度,垫片和射频线圈用耀斑定位后。(ii)生理信号,线圈连接和表调整应显示在磁铁的龙门上e)主动屏蔽/条纹场 div>



MRI 神经治疗方案
• 患者佩戴牙套或其他金属植入物,导致磁敏感伪影 – 移除 FS 并进行 GRE Cor 而不是 SWI。 • 如果在 SWI 轴向上发现运动,可以进行常规 GRE 冠状位检查。 • 咨询放射科医生获取 PRN gad 订单或未指定 gad 的 ARA 转诊

MRI 市政厅 2023
• MRI 征集书第 II 部分:计划描述:“MRI 将接受包括购买、安装、操作和维护设备和仪器以减少氦气消耗的请求。对此类请求的支持仅限于用于共享研究仪器的设备和仪器。请求可能是第 1 轨道或第 2 轨道提案的一部分(在适用于这些轨道的预算限制内),或作为“第 3 轨道”提案单独提出。第 1 轨道和第 2 轨道中的提案请求支持需要使用氦气的仪器,必须描述氦气的保护和/或回收和再利用计划;提交单独第 3 轨道提案的计划不足以构成此类计划。” • 有关第 3 轨道提案的科学依据的问题应向知情计划官员提出。