XiaoMi-AI文件搜索系统
World File Search SystemMas

采用 MAS Blackboard 系统的 LiFePO4 电池储能系统的双层 SOC 和 SOH 均衡方案
1 齐齐哈尔大学机电工程学院,齐齐哈尔 161000;luzhongda@163.com;wangqilong3411@163.com;xufengxia_hit@163.com

德克萨斯大学土木、建筑和环境工程系(CAEE)的超材料和先进结构实验室(MAS Lab)
关于 PI:张云兰 (Emma) 我获得了俄亥俄州立大学土木工程学士学位,之后在普渡大学攻读博士学位,研究机械超材料和仿生材料。超材料经过精心设计,具有天然材料所不具备的新颖特性。之后,我在牛津大学工作了大约两年,将这些知识应用于可部署医疗设备的设计。这些经历让我看到了土木工程教育的多功能性。我喜欢与学生一起工作,就像进行研究一样,并邀请对开发创新结构感兴趣的学生申请加入我的实验室。

临床科学 Still 病和巨噬细胞活化综合征 (MAS) 治疗的有效性和安全性:EULA 的系统评价
摘要 目的 分析 Still 病和巨噬细胞活化综合征 (MAS) 治疗的疗效和安全性。方法 在 Medline、Embase 和 Cochrane 图书馆中搜索临床试验(随机、随机对照试验 (RCT)、对照和临床对照试验 (CCT))、观察性研究(回顾性、纵向观察回顾性 (LOR)、前瞻性和纵向观察前瞻性 (LOP))和系统评价 (SR),其中研究人群为 Still 病和 MAS 患者。干预措施是任何药物治疗(已批准或正在评估)与任何对照药物或安慰剂的对比,结果包括任何相关的疗效和安全性事件。使用 Cochrane RoB 和 AMSTAR-2(评估系统评价的方法学质量-2,第 2 版)评估 SR 的偏倚风险 (RoB)。结果 共纳入 128 篇全文:25 篇 RCT、1 篇 CCT、11 篇 2013 年以后发表的 SR 和 91 篇 LOP/LOR 研究。在 Still 病中,白细胞介素 (IL)-1 抑制剂 (IL-1i) 和 IL-6R 抑制剂 (IL-6i) 是研究最多的药物。两项 RCT 荟萃分析显示,IL-1i 和 IL-6Ri 达到 ARC50 反应率的 OR 分别为 6.02(95% CI 2.24 至 21.36)和 8.08(95% CI 1.89 至 34.57)。回顾性研究表明,早期开始使用 IL-1i 或 IL-6i 与临床无活动性疾病的高发生率相关。在 MAS 中,所有患者均使用了 GC,通常与环孢素和/或阿那白滞素联合使用。报告的完全缓解率范围为 53% 至 100%。Emapalumab 是 CCT 中唯一测试的药物,完全缓解率为 93%。结论 IL-1i 和 IL-6Ri 在治疗 Still 病方面表现出最高水平的疗效。对于 MAS,在高剂量糖皮质激素的背景下,IL-1 和干扰素-γ 抑制似乎有效。

使用合作伙伴阅读策略对MAS YP的园艺博览会文本的英语阅读理解成就的影响。 haji datuk
教育过程从未与人类与人类生活和文化环境的沟通分离。在印度尼西亚社会的生活中,互动肯定是单独发生的,或者是在群体中发生的,社会化的过程与与社会系统有关的文化学习过程涉及(Darma&Joebagio,2018年)。英语是世界上最重要的外语,被用作国际语言。根据(Errington,2006)。作为一种全球语言,很明显,英语在国际互动中起着重要作用。国际互动包括国家之间的经济关系,国际业务关系,全球贸易等。词汇是英语教学学习的重要方面之一。另一个方面是,老师必须在寻找,选择和简化使学生掌握词汇的材料方面具有创造力和耐心,换句话说,学习词汇学生的语言技能会遇到麻烦(Sugiarti,2022年)。在这种国际互动中,英语主要充当全球语言。通用语言是一种语言,用于与来自不同国家的不同人群进行交流。

自主环境中的协作与竞争
智能中的抽象尖端技术涉及多代理系统(MAS),这些系统使自主代理可以通过共同的合作或竞争实现共同或个人目标来在共享环境中进行交互。这项研究深入研究了MAS中合作和竞争的各个方面,并说明了它们在实际情况下的应用,例如自动驾驶汽车,机器人的互动和财务环境。除此之外,我们还探索了在创建MAS框架时进行的协调,学习和沟通等障碍,以及如何进行深入强化学习等复杂算法有助于运行这些代理。通过解决MAS中的两种竞争互动,我们的目标是对在这一领域的可能用途和即将到来的道路进行彻底掌握。像OpenAIS代理商模型这样的新兴技术在展示MAS不断变化的景观及其对医疗保健和国防等各个行业的变革性影响方面发挥了重要作用。关键字:多代理系统(MAS),自主代理,协作,竞争,深度强化学习,游戏理论,分发AI,基于代理的智能,基于代理的建模,AI协调,AI协调,对抗性AI介绍MAS MAS是AI部署领域的游戏规则,与传统AI Systems相比
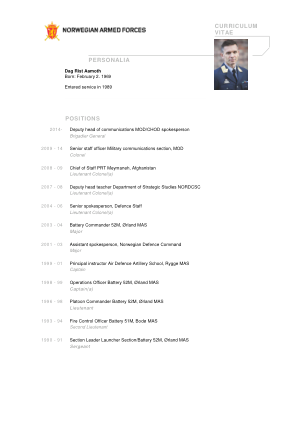
个人简历 个人职位
2014- 国防部/CHOD 通讯副主管发言人 准将 2009 - 14 国防部军事通讯科高级参谋 上校 2008 - 09 阿富汗梅曼内 PRT 参谋长 中校(a) 2007 - 08 副校长 NORDCSC 战略研究系 中校(a) 2004 - 06 国防参谋部高级发言人 中校(a) 2003 - 04 Ørland MAS 第 52M 炮兵连指挥官 少校 2001 - 03 挪威国防司令部助理发言人 少校 1999 - 01 Rygge MAS 防空炮兵学校首席教员 上尉 1998 - 99 作战官 Ørland MAS 第 52M 炮兵连 上尉(a) 1996 - 98 炮兵排指挥官52M,厄兰 MAS 中尉 1993 - 第 94 消防官连 51M,博德 MAS

文凭持有者计划 - 政府赞助
BACHELOLOR OF MEDICEELOR OF MEDICEELOR OF BACHELOLOR OF SURGERY (MAM) ~ NAME CTRY CTRY DISTRICT 1 MUGISA Pau l Edwin l Edwin 2 MUGISA l Edwin 2 MUGAMPA 2 MUMANB OF 2 MUMMB ERE 3 3 MASCS 3 MAS 3 MAS 3 MAS 3 MAIS I KAID 4 CHAING MY RAID 4 KOID 3 NJA 5 KSAMBA nakhiraht f bu
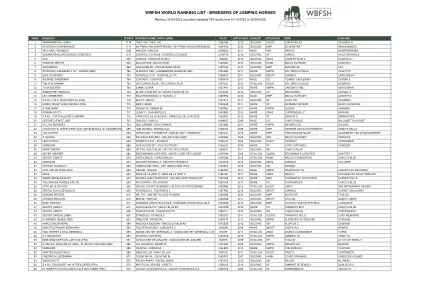
障碍赛马饲养者 - 障碍赛世界
294 M. DOMINIQUE MAES, MME FREDERIQUE MAES, CHAILLY EN BIERE (法国) 313 VANGOG DU MAS GARNIER / VANGOG DU MAS GARNIER 104WE32 2009 种马 SF 短号 QELBOID DEv