XiaoMi-AI文件搜索系统
World File Search SystemMaterial


补充材料 - repisalud
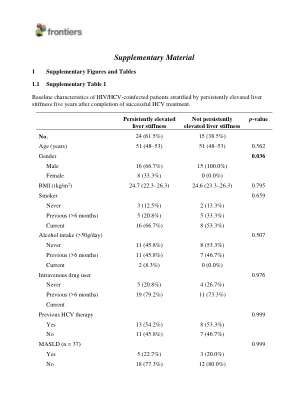
统计:数据是通过具有伽马分布(LOG-LINK)的广义线性模型(GLM)计算的。多变量模型按年龄,性别,HCV治疗(基于IFN的治疗或DAAS),在治疗后一年进行LSM调整,并且在两次之间经过的时间,以前是通过逐步方法(前进)选择的(请参阅结果部分)。Q值代表使用错误发现率(FDR; Benjamini和Hochberg程序)进行多次测试校正的p值。统计上的显着差异以粗体显示。缩写:AMR,算术平均比例; AAMR,调整后的AMR; 95%CI,95%的置信区间; P,意义水平; q,校正的意义水平; BTLA,B和T淋巴细胞衰减剂; CD,分化簇; GITR,糖皮质激素诱导的TNFR相关; HVEM,疱疹病毒入学调解人; IDO,吲哚胺2,3-二氧酶; lag-3,淋巴细胞激活基因-3; PD-1,程序性细胞死亡蛋白1; PD-L1,编程的死亡配体1; PD-L2,编程死亡配体2; TIM-3,T细胞免疫球蛋白和含有3的粘蛋白膜。



电池材料工程师~~~
电池技术,培训和技能的联盟 - 项目编号612675-EPP-1-2019-1-SE-EPPKA2-SSA-B。根据2019 - 612675年授予协议,欧盟委员会支持本出版物的生产,并不构成仅反映作者观点的内容的认可,并且对委员会对可能包含的信息的任何用途负责。


操纵所有内容的补充材料
动作生成模块。我们使用以代理为中心或以对象为中心的方法生成每个动作。对于以对象为中心的动作生成,我们利用了NVIDIA的基础掌握预测模型M2T2 [1]进行选择和放置动作。对于6-DOF抓握,我们从单个RGB-D摄像头(在现实世界中)或多个摄像机(在模拟中)输入一个3D点云。该模型在任何可抓取的物体上输出一组掌握提案,提供6-DOF的抓取候选物(3-DOF旋转和3D-DOF翻译)和默认的抓地力关闭状态。对于放置操作,M2T2输出一组6-DOF放置姿势,指示在基于VLM计划执行Drop原始操作之前,最终效应器应在何处。网络确保对象在没有冲突的情况下稳定地定位。我们还设置了mask_threshold和object_threshold的默认值,以控制拟议的GRASP候选人的数量。提出了模板抓取姿势的列表后,我们使用QWEN-VL [2]通过使用机器翻译模型[3]提示当前图像框架来检测目标对象。此检测应用于来自不同相机的所有重新渲染观点或观点。然后,我们将这些帧连接到单个图像中,将每个子图像用右上角的数字注释。接下来,我们将带有几次演示的GPT-4V API调用,并且任务目标提示GPT-4V输出所选数量的视点,这些视点为采样抓取姿势提供了最无用的视图以实现子任务。使用选定的观点,我们通过将最终效果通过运动计划者移动到采样的抓握姿势来执行掌握。

