XiaoMi-AI文件搜索系统
World File Search SystemMemory


记忆的奥秘:没有“生命”,没有记忆
我们从认罪开始,我们会混淆内存是仅由数据和信号组成还是其他信息状态?如何形成,存储,召回和检索不同信息状态的这种记忆?自然或有意识遗忘的机制是什么?我们如何以及为什么忘记某些问题,但还记得其他问题?为什么我们尚不确定不同种类的痴呆症中记忆丧失的不同机制,尽管知道皮质和海马神经元的丧失及其连通性?尽管整个神经和神经胶质网络的可用性,但为什么在没有生命的大脑或脑死患者中没有记忆,存储,召回和检索?在通过死亡期间如何完全记忆丧失?为什么要记住前出生的特殊事件?为什么我们在人工智能的任何设备中都对缺乏记忆的问题保持沉默?没有系统地清除记忆力,并且可以解释物种的演变和存在的转化!所有这些未解决的问题使记忆变得神秘,并要求对记忆进行更多调查!


记忆、神经科学和记忆增强
本文提出了对记忆的全新理解,这也将改变有关记忆增强的争论的坐标。我们不应该把记忆看作一个仓库,而应该从叙事的角度来思考记忆。这种观点让我们深入了解了我们构建记忆的实际过程——即通过构建有意义的摘要,而不是添加离散元素。我认为,这种关于记忆的新思维方式将使我们现有的或在不久的将来拥有的大多数增强记忆的技术在伦理上不再那么令人担忧。主要思想是,(生物)记忆与记忆增强以通常的方式以创造性和重新阐述的方式相互作用。最后,我将举几个案例来说明前面的观点。
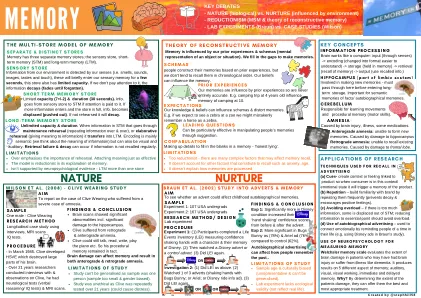


记忆的神经生物学
Hubel和Wiesel的开创性工作,他们在许多研究中表明,新生动物中视力的单眼遮挡导致视觉皮层的永久异常。因此,这些研究显着地表明,感觉输入在大脑的发展和组织中具有至关重要的作用。第二个范式与学习的两个方面:习惯和敏化。坎德尔博士在一个简单的学习动物模型上介绍了自己的作品,即海军陆战队的g aplysia加利福尼亚州的g。坎德尔博士在突触结构和效率如何与学习有关的变化方面提出了惊人的发现。他得出结论,所有体验事件,包括心理治疗干预措施,最终都会影响神经元突触的结构和功能。坎德尔博士在这篇1979年的文章中的两个范式的选择特别令人惊讶的是,这两个领域的成就得到了诺贝尔议会的认可,并获得了我们领域中获得的最高奖项。Hubel和Wiesel于1981年获得诺贝尔医学或生理学奖,坎德尔博士于2000年与Arvid Carlsson和Paul Greengard分享了相同的奖项。
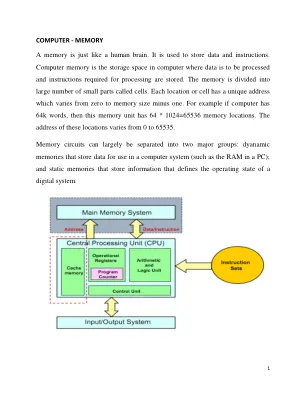


数字技术对记忆和记忆研究的影响
摘要 :随着智能手机、电脑和互联网的广泛融合,信息获取和处理发生了重大变化。本文探讨了积极和消极影响,承认通过轻松访问庞大的数据库和外部记忆辅助工具可以扩展认知能力,同时也解决了对记忆巩固减弱和依赖浅层编码策略的担忧。该研究考察了记忆研究的跨学科领域,还强调了心理学、神经科学、社会学和信息科学学者为理解数字技术对记忆的影响而做出的合作努力,并强调了记忆研究的挑战和未来方向,包括数字健忘症、信息过载和隐私问题等问题。总的来说,本文强调需要了解人类记忆与数字工具之间的关系,从而制定策略来增强记忆,抵消潜在的不利影响,并促进在记忆相关任务中平衡利用数字资源。