XiaoMi-AI文件搜索系统
World File Search SystemMetrics



2023可持续性指标
从2023年的可持续性和企业责任(SCR)报告开始,我们通过利用公共可用的模板和披露来简化了我们的可持续性指标的介绍,这些模板和披露与下表相关联。此外,我们还更新了可持续性网站,以提高导航和透明度。

2023 年可持续发展目标和指标
本《可持续发展目标和指标报告》(“可持续发展报告”)和相关网站内容包含前瞻性陈述,包括与我们的可持续发展战略、计划和目标相关的陈述。这些前瞻性陈述是基于我们当前的假设、期望和预测做出的。这些前瞻性陈述是估计值,涉及许多风险和不确定性,可能导致实际结果大不相同。有关我们治理的其他风险、不确定性和信息,请参阅我们向美国证券交易委员会提交的 10-K 年度报告表和代理声明。其他未知或不可预测的因素也可能对我们的未来结果、业绩或成就产生重大影响。本《可持续发展报告》和相关网站中的所有信息均截至最初提交之日,我们不承担更新此信息的任何义务。


对全球生物多样性指标的影响
Supporting Information for Hard-to-sample species are more sensitive to land-use change: implications for global biodiversity metrics Claudia Gutiérrez-Arellano*, Tim Newbold, Jenny A. Hodgson *Email: c.gutierrez-arellano@liverpool.ac.uk This PDF file includes:

拟议的 2025 年绩效指标
PSEG Long Island 可以在截止日期之前提交可交付成果,如果时间允许,LIPA 将尽合理努力提供反馈,以便 PSEG Long Island 改进并在截止日期之前重新提交可交付成果。对于截止日期前提交的、被确定为不符合 LIPA 批准标准的可交付成果,LIPA 将提供原因摘要以及完成交付所需的条件,PSEG Long Island 可以在十个工作日内重新提交可交付成果。如果解决 LIPA 反馈所需的修订需要超过十个工作日才能完成,PSEG Long Island 将提交例外请求,并附上拟议时间表(包括理由),LIPA 将对此进行合理考虑。PSEG Long Island 在截止日期后只有两次机会重新提交可交付成果以获得 LIPA 批准,除非以例外请求的形式获得批准。
最佳经济指标
董事会和管理埃文·克兰斯顿(Evan Cranston) - 克兰斯顿(Cranston)主席是一位经验丰富的采矿主管,具有公司和采矿法的背景。彼得·艾伦(Peter Allen) - 董事总经理艾伦(Allen)是一位采矿高管,在营销锰产品,锂和一系列其他商品方面拥有超过20年的经验。wei li - 财务总监李先生是一位在矿产资源行业拥有丰富经验的特许会计师。李先生在北领地管理了一家私人基金金属勘探公司,并协助成功开发了在中国湖南的1.5亿美元电解型二氧化碳工厂。李先生的母语是普通话。Ashley Pattison - 非执行董事Pattison先生从公司财务和运营的角度拥有20多年的矿产资源领域经验。Brett Grosvenor - 非执行董事Grosvenor Mt是一位经验丰富的采矿主管,在采矿和能源行业拥有超过25年的经验。高度证书的团队进步FRB策略

陆地生物多样性的全球指标
生物多样性指标越来越多地向政府,企业和民间社会的决定提供信息。但是,最终用户这些指标的不同或最适合它们的目的并不总是清楚的。我们试图使用573个与生物多样性相关的指标,指标,指标和层的数据库回答这些问题,这些指标,指标,指标和层介绍了遗传性二元,物种和生态系统的各个方面。我们提供了指标及其在状态 - 压力 - 反应 - 结局框架中的用途,该框架被广泛用于保护科学。在此框架中确定互补性,我们建议少数被认为最相关的指标用于政府和企业的决策。我们通过强调未来的五个方向来确定:提高民族指标的重要性,确保更广泛的商业指标的吸收,同意政府和商业使用的最低指标,从而通过使用技术来自动计算,并为指标生产生成可持续资金。
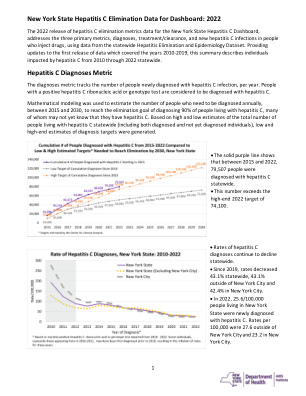
纽约州 HCV 消除指标
治疗/清除指标跟踪每年确诊感染丙型肝炎且有证据表明已接受治疗或清除丙型肝炎的人数。如果丙型肝炎核糖核酸或基因型检测呈阳性,随后丙型肝炎核糖核酸检测呈阴性或经其他数据来源表明接受过治疗,且未进行任何其他丙型肝炎核糖核酸或基因型检测,则认为丙型肝炎感染已得到治疗或清除。纽约市于 2014 年和全州于 2016 年开始报告丙型肝炎核糖核酸检测呈阴性的结果,从而可以识别出已清除感染的人(无论是经过治疗还是未经治疗而自行清除)。目标是到 2030 年治疗 80% 的丙型肝炎确诊患者。