XiaoMi-AI文件搜索系统
World File Search SystemModel


A Maturity Model for European Micro-credentials
Technology & Data for Micro-credentials • Aligning with the ELMv.3 allows for comparability and transferability • Several member states possess unique digital authentication systems • EUDI wallet is a tool to allow portability of micro-credentials (coming soon)

型号 ADHO24-4 型号 AD24-2 型号 AERO-24
结构 AeroLogic ® 单灯风管模型专为住宅应用而设计,采用轻质阳极氧化铝制成。阳极氧化铝具有更高的表面硬度,耐用性和耐腐蚀性与不锈钢相似。这种坚固的结构与防水电源线(适用于室内/室外使用)和防液体电线夹一起构成了“防滴”组件。


企业中的生成AI -Model自定义
在此设计中,我们主要关注骆驼2。Llama 2可免费提供研究和商业用途。它为聊天用例优化的生成文本和微调模型提供了一系列验证的模型。Llama 2型号在2万亿代币数据集上进行了培训,其特征是Llama1。此外,超过100万个新的人类注释进一步丰富了Llama 2聊天模型。这些模型建立在优化的变压器体系结构上,并具有各种参数尺寸。使用开放源的大型语言模型(例如Llama 2)的本地部署为客户提供了随着时间的推移的价值,并以可预测的成本和对数据的完全控制,从而降低了安全性和IP泄漏的风险,并确保遵守法规。

Model RT 5120 / RT 5320 - prom.st
[1]测试条件:100%排放深度(DOD),0.2C的费率电荷和排放在25℃[2] [2]电荷/放电降低时,当工作温度从-10℃到5℃&45℃至55℃[3]时,会发生工作温度。请参阅保修字母
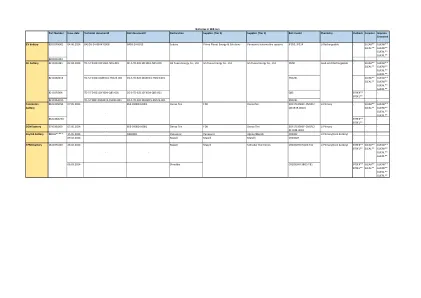
零件编号发行日期技术文件#文档文件#声明供应商(Tier 2)供应商(第1层)Batt Model Model Intrack Forester Impreza
03.07.2024 57491FL053 KEY KIT 05.04.2024 - D240003 Panasonic Energy Panasonic Tokai Rika CR1620 03.07.2024 57491FL063 KEY KIT 05.04.2024 - D240003 Panasonic Energy Panasonic Tokai Rika CR1620 03.07.2024 57491FL152 KEY KIT 05.04.2024 - D240003 Panasonic Energy Panasonic Tokai Rika CR1620 03.07.2024 57491FL162 KEY KIT 05.04.2024 - D240003 Panasonic Energy Panasonic Tokai Rika CR1620 03.07.2024 57491SG230 KEY KIT EU 05.04.2024 - D240003 Panasonic Energy Panasonic Tokai Rika CR1620 03.07.2024 57491SG280 KEY KIT E2 05.04.2024 - D240003 Panasonic Energy Panasonic Tokai Rika CR1620 03.07.2024 57491SG330 KEY KIT EK 05.04.2024 - D240003 Panasonic Energy Panasonic Tokai Rika CR1620 03.07.2024 57491SJ051密钥套件05.04.2024 -D240003 Panasonic Energy Panasonic Tokai Rika CR1620 03.07.07.2024 CR1620 03.07.2024 57491VA122密钥套件EU 05.04.2024 -D240003 Panasonic Energy Panasonic Panasonic Tokai Rika CR1620 03.07.2024 57491VA192 57491VA220密钥套件05.04.2024 -D240003 Panasonic Panasonic Tokai Rika CR1620 03.07.2024 57497AJ142密钥板钥匙板钥匙板2024/5/27(P)2024/6/6/25(M) -

开发用于评估业务模型的模型
伊斯兰伊斯兰阿扎德大学Dehaghan Branch公共行政副教授,伊朗伊斯法汉摘要目的:本研究的目的是设计一种用于评估创业商业模型中数字创新和转型的模型。 方法:这种重置的方法是描述性探索性的,采用了定性方法。 主题分析用于研究启动业务模型中的数字创新和转型。 这项研究的参与者是学术和工业专家,在精益创业公司的研究和执行工作背景下。 最初,使用目的抽样方法来选择样品,然后使用雪球方法进行了扩展。 最终,研究人员进行了14项专家访谈以收集数据。 根据主题分析,使用编码对访谈中获得的数据进行了审查和分析。 最初,从访谈的文本中提取了代码。 这些代码汇总为更通用的代码,这些代码得到了进一步研究并集成到组件中。 来自这些组件,相关伊斯兰伊斯兰阿扎德大学Dehaghan Branch公共行政副教授,伊朗伊斯法汉摘要目的:本研究的目的是设计一种用于评估创业商业模型中数字创新和转型的模型。方法:这种重置的方法是描述性探索性的,采用了定性方法。主题分析用于研究启动业务模型中的数字创新和转型。这项研究的参与者是学术和工业专家,在精益创业公司的研究和执行工作背景下。最初,使用目的抽样方法来选择样品,然后使用雪球方法进行了扩展。最终,研究人员进行了14项专家访谈以收集数据。根据主题分析,使用编码对访谈中获得的数据进行了审查和分析。最初,从访谈的文本中提取了代码。这些代码汇总为更通用的代码,这些代码得到了进一步研究并集成到组件中。来自这些组件,相关

评估特斯拉 Model 3 驾驶辅助系统的可靠性...
15.补充说明 与美国运输部、联邦公路管理局合作进行。16.摘要 配备可同时执行自动转向和加速的高级驾驶辅助系统 (ADAS) 的车辆数量正在增加,预计这些功能将在低成本车型和豪华车中提供。这些系统要求人类驾驶员保持警惕并随时待命,以防他们需要接管。因此,在配备 ADAS 的车辆中,人与机器之间的界面至关重要。对此类 ADAS 系统的开发的正式测试和指导有限。这项工作的目标是在涉及人类驾驶员和 ADAS 系统之间界面的四种场景中评估配备 ADAS 的车辆之间和车辆内部的变化。这些场景包括:(1) 在高速公路自动驾驶期间评估驾驶员监控系统的性能;(2) 在自动驾驶期间向分心的驾驶员发出意外道路模式的警报;(3) 协助分心的驾驶员应对无意的车道偏离;(4) 当车辆无法再自信地行驶时,将驾驶员交接给分心的驾驶员。鉴于特斯拉可能面临一系列潜在的苛刻环境,特斯拉 Model 3S 是测试平台。结果表明,计算机视觉系统的性能变化极大,这种变化可能是部分(但不是全部)延迟向双手不在方向盘上的驾驶员发出警报的原因。单辆车的性能并不一致,因为一辆车在最具挑战性的驾驶场景(在驾驶员忽略接管请求的情况下驾驶极端弯道)中表现最佳,但在看似更简单的场景(如检测车道偏离)中表现最差。这些结果表明,从业者需要开发一套更丰富的测试来捕捉汽车内和汽车之间的变化,同时也表明通过无线更新进行的软件升级可能会引发导致安全问题的潜在问题。

Multi-scale Fusion Model Based on Gated Recurrent Unit ...
摘要 - 电池储能系统(BESS)的最新电荷(SOC)的准确预测对于电动汽车的安全性和寿命至关重要。为了克服多尺度特征融合和全球特征提取之间现有方法的不平衡,本文介绍了基于门控复发单元(GRU)的新型多尺度效果(MSF)模型,该模型是专门为实用BESS中复杂的多步社预测而设计的。Pearson相关分析首先是为了识别与SOC相关的参数。然后将这些参数输入到多层GRU中以进行点特征。同时,参数在输入双阶段多层GRU之前进行修补,从而使模型能够在不同的时间间隔内捕获细微的信息。最终,通过自适应重量融合和完全连接的网络,进行了多步骤的SOC预测。在数天内进行了广泛的验证,可以说明所提出的模型在实时SOC预测中达到的绝对误差小于1.5%。