XiaoMi-AI文件搜索系统
World File Search SystemMs

电气和计算机工程中的MS程序
与计算机和计算机网络有关的安全基础。法律和道德。社会工程和基于心理的攻击。信息收集,网络映射,服务枚举和漏洞扫描。与访问控制,利用和磁盘取证有关的操作系统安全性。shellCoding。在物理,网络和应用程序层处有线和无线网络安全性。理论课程通过案例研究和证明性实验实验室增强。4CR ENG EC 523 A1深度学习Batmanghelich Mathagical和Machine Learning背景的深度学习背景。进料向前网络,反向传播。深层网络的培训策略。卷积网络。循环神经网络。深入的强化学习。深度无监督的学习。暴露于TensorFlow和其他现代编程工具。其他最新主题,时间允许。与CAS CS 523。学生可能不会获得两者的学分。4CR ENG EC 524 A1优化理论和方法Castanon教授

数字供应链管理,MS
主要教授在与学生协商时,审查了学生的学术背景和职业目标,并设计了一项符合学位要求一致的适当学习计划。在为没有工商管理本科背景的学生制定研究计划时,要确保对管理领域的不同方面的基本接触以及在被选定的专业领域进行深入准备。

人力资本分析和技术(MS)
人力资本分析和技术科学硕士(HCAT)是为新兴和中级专业人员(三到五年或更多相关经验)而设计的,他们对人分析和技术在商业战略和计划中的作用充满了兴趣和欣赏。完成该计划后,毕业生将不仅能够研究,评估和实施分析方法和技术,而且还能够为广泛的利益相关受众群体围绕数据构建叙事。学生还将获得领导人力资本分析和技术功能所需的分析方法,技术准备,业务敏锐度和沟通技巧。

Georg Dorffner,ao.univ.prof。外交。 2024年6月Christina Morgenstern,博士,MS C
P ROFESSIONAL E XPERIENCES M EDICAL U NIVERSITY OF V IENNA Vienna, Austria Bioinformatician and Data Scientist Since 10/2023 U NIVERSITY OF G RAZ Graz, Austria Postdoctoral Scientist (part-time) 09/2022 – 12/2023 U NIVERSITY C OLLEGE FOR T EACHER E DUCATION C ARINTHIA & Klagenfurt & Graz, Austria U NIVERSITY OF G RAZ 09/2014 – 09/2023 Lecturer S CIENCE I MPULS Seeboden, Austria Business Owner, Science Communicator 07/2009 – 09/2024 C ARINTHIA U NIVERSITY OF A PPLIED S CIENCES Villach, Austria Part-time Lecturer 03/2010 – 07/2017 M ERCK KG A A & C O .w erk s pittal spittal/drau,奥地利质量保证08/2011 - 09/2012 c ancer c ancer c ancer c ancer r esearch uk l ondon l ondon l ondon r esearch i nstitute n stitute n stitute n stitute london,UK PHD学生07/2005 - 06/2009

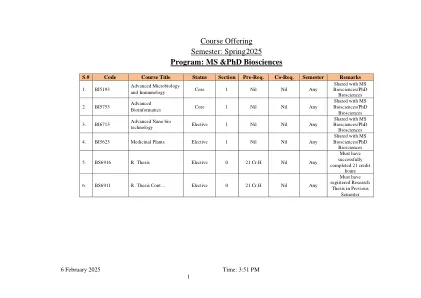
MS/PH.D。研究生计划手册
1。介绍性信息A.序言欢迎来到园艺和作物科学系(HCS)!园艺和作物科学系的使命是通过创新和发现获得有关植物及其用途的知识,然后传播这些知识以使俄亥俄州立大学,俄亥俄州人民和世界受益。多年来,我们的计划提供了影响植物科学的结果,并特别强调园艺和作物科学。我们可以通过通过应用生物科学的应用,扩展和研究工作来通过创新,发现和应用来为经济增长做出贡献。我们的努力将以节能和环境可持续的方式提供营养食品,用于优质城市栖息地的植物以及植物性的产品,有助于应对粮食安全和人类健康,环境质量和可持续性的全球挑战,以及先进的生物能源和生物基础产品。本HCS研究生研究手册描述了研究生课程中使用的规则,过程和程序(M.S.和Ph.D.)在HCS中。该文档由研究生研究委员会(GSC)撰写和更新,新版本均由HCS的所有投票教师批准。B.与研究生院手册的关系本园艺和作物科学系(HCS)研究生手册补充了研究生院手册,应与研究生学校手册一起使用。和Ph.D.研究生课程。本手册概述了适用于HCS M.S.涉及的研究生,教职员工和计划的特定规则,程序,政策和要求C.学位提供了园艺和作物科学系提供以下研究生学位:

商业人工智能 (MS) - 概述
商业人工智能硕士 (MSAIB) 课程面向具有前瞻性思维的多元化专业人士,他们既有希望在公司、组织或咨询机构的业务运营中率先采用人工智能的人,也有希望获得更深入的人工智能技术专长以增强其现有的 IT 知识库的人。该课程强调整合现实世界的应用程序,利用人工智能的变革能力来提高业务角色和职能的速度和效率。其创新课程的开发旨在为那些对人工智能有基本了解的人以及那些多年来一直从事人工智能工作的人提供最大的灵活性。

纺织管理硕士课程大纲.pdf
在动荡的商业环境中,为工程驱动型公司制定竞争战略的关键问题:企业使命;关键结果领域和情境分析,包括优势、劣势、机会和威胁;确定规划假设、关键问题、设定目标、制定战略。将技术作为公司的战略资源进行管理;了解流程。技术创新的作用和回报;将技术的战略关系与战略规划、营销、财务、工程和制造相结合;政府、社会和国际问题;与文化多样性和道德问题有关的问题。主观、判断和专家决策;涉及技术替代方案的战略决策中的冲突解决;分层决策模型;个人和集体决策;决策差异和群体分歧评估。

教学大纲-MS(Pharm。)药理学和毒理学
1。Frank Hawking的化学疗法2。Julius P. Kreier和Ristic的寄生原生动物3。Maraia撰写的Julius P. Kreier 4。Wallace Peter 5。Wallace Peter和Geoffrey Pasvol的热带医学和寄生虫学的地图6. 曼森的热带疾病:戈登C.库克7. 的专家咨询基础 热带传染病:理查德·L·Guerrant,大卫·H·沃克和彼得·韦勒8。 Richard L. Guerrant,David H. Walker,Peter F. Weller 9。 F. E. G. Cox 10。的人类寄生虫学历史 P. C. C. Garnham 11。 Bailey&Scott的诊断微生物学12。 Samuel Baron的医学微生物学13。 P. C. Baveja的微生物学教科书14。 Prati Pal Singh和V. P. Sharma编辑的药物和国家重要性的人类寄生虫感染15。 Martin Filion编辑的应用微生物学的定量实时PCRWallace Peter和Geoffrey Pasvol的热带医学和寄生虫学的地图6.曼森的热带疾病:戈登C.库克7.热带传染病:理查德·L·Guerrant,大卫·H·沃克和彼得·韦勒8。Richard L. Guerrant,David H. Walker,Peter F. Weller 9。F. E. G. Cox 10。P. C. C. Garnham 11。Bailey&Scott的诊断微生物学12。Samuel Baron的医学微生物学13。P. C. Baveja的微生物学教科书14。Prati Pal Singh和V. P. Sharma编辑的药物和国家重要性的人类寄生虫感染15。Martin Filion编辑的应用微生物学的定量实时PCR