XiaoMi-AI文件搜索系统
World File Search SystemNIP

成人预防接种
• 越来越多的疫苗可供使用,并被《澳大利亚免疫手册》推荐用于成年期。 • 如果成年人因年龄、职业、个人行为或医疗状况等因素而患病风险增加,则可能会建议他们接种某些疫苗。一些推荐的疫苗由国家免疫计划 (NIP)、州和领地计划或通过工作场所为某些群体提供资金,而其他疫苗则可以通过处方私下购买。 • 免疫接种提供者在促进成年期接种疫苗方面发挥着重要作用,应抓住一切机会识别并向符合条件的个人提供疫苗接种。 • 目前建议所有 5 岁以上的人接种 COVID-19 疫苗,并且对所有人免费。 • 根据国家免疫计划,季节性流感、肺炎球菌和带状疱疹 (带状疱疹) 疫苗由符合条件的成年人资助。 • 从 2021 年起,澳大利亚有两种带状疱疹疫苗可供 50 岁以上的健康人群使用,以预防带状疱疹及其并发症:Zostavax 和 Shingrix。 Shingrix 也适用于免疫功能低下的 18 岁以上人群。• 由于 Zostavax 是一种减毒活疫苗,因此一般禁用于免疫功能低下的人群。• 孕妇可接种流感和百日咳疫苗,NIP 对此提供资助。• 在咨询期间,请务必注意原住民和托雷斯海峡岛民的身份,因为原住民和托雷斯海峡岛民接种 NIP 资助疫苗的适应症和资格与非原住民不同。

利用双台面结构电容电压测量确定 II 型超晶格中的背景掺杂类型
我们提出了一种确定半导体背景掺杂类型的方法,即在过度蚀刻的双台面 pin 或 nip 结构上使用电容电压测量。与霍尔测量不同,此方法不受基板电导率的限制。通过测量具有不同顶部和底部台面尺寸的器件的电容,我们能够最终确定哪个台面包含 pn 结,从而揭示本征层的极性。当在 GaSb pin 和 nip 结构上演示时,此方法确定该材料是残留掺杂的 p 型,这已由其他来源充分证实。然后将该方法应用于 10 单层 InAs/10 单层 A1Sb 超晶格,其掺杂极性未知,并表明该材料也是 p 型。

肺炎球菌感染后的不良事件信号检测...
2017年,韩国的肺炎球菌感染率达到历史最高,肺炎链球菌是细菌性肺炎的主要原因。1,2尽管在过去50年中使用了抗生素和重症监护,但肺炎球菌菌血症的病死率在儿童和青少年中仍然高达15–20%,在老年人中高达30–40%。3-5此外,各种肺炎球菌的耐药率一直在稳步上升。在这种情况下,疫苗接种已成为预防肺炎球菌感染最经济有效的方式。6肺炎球菌疫苗主要有两种类型:23价肺炎球菌多糖疫苗(PPSV)和肺炎球菌结合疫苗(PCV),其中多糖与蛋白质结合。 7 韩国国家免疫计划 (NIP) 于 2013 年为 65 岁及以上人群推出了 23 价 PPSV,2014 年为 5 岁以下儿童推出了 8 价 PCV。9 NIP 的推广似乎使儿童和青少年都受益

Quant Mutual Fund
The Government of India's commitment to implementing successive reforms, the focus on executing ambitious projects under the National Infrastructure Pipeline (NIP) and the growth in state capital expenditure have all contributed to creating a favourable investment climate Source: Internal research, RBI, CMIE, Sector reports

p17809207abd440ae0be820ac ...
泰国是一个拥有近7000万人的国家,是东盟国家中第四大的国家。2002年,它开创了该机构国家卫生保障办公室(NHSO),以确保为泰国人民提供普遍的卫生保险,包括获得免费的高质量疫苗。自2018年以来,泰国就已经制定了一项国家战略政策和行动计划,以确保疫苗的可持续供应并支持国内疫苗行业。泰国的国家免疫计划是在1977年引入的,在过去20年中达到了高疫苗覆盖率(大于80%)。NIP时间表当前包括12种疫苗,包括用于轮状病毒,该疫苗最近于2020年推出。国内产量符合BCG疫苗的年度需求,占季节性流感疫苗的50%;进口NIP的所有其他疫苗。NHSO与Siraraj医院合作监督NIP疫苗的采购,而进口和分销由上市公司政府制药组织(GPO)管理。泰国拥有四个国内疫苗制造商 - 一名公众,两个公共/私人私人疫苗,其中一名具有上游和下游疫苗制造能力,但总体上缺乏全光谱生产能力。泰国疫苗制造商优先考虑与大学,生物技术公司,实验室和其他疫苗制造商建立牢固的协作关系,以进行技术传输和能力建设。泰国在2020年1月报告了第一个Covid-19和两个月后的第一次死亡。迅速实施的公共卫生和社会措施在大流行的初始阶段成功控制了疾病。安全有效的COVID-19疫苗,首先生产并交付给高
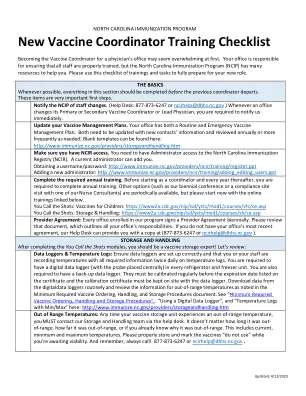
新疫苗协调员培训清单
添加新管理员:http://www.immunize.nc.gov/providers/ncir/training/adding_editing_users.ppt 完成所需的年度培训。在担任协调员之前以及此后的每一年,您都需要完成年度培训。其他选项(例如我们的两年一度的会议或与我们的护士顾问之一一起进行的合规现场访问)定期提供,但请立即开始使用下面链接的在线培训。 您决定接种疫苗:儿童疫苗:https://www2a.cdc.gov/nip/isd/ycts/mod1/courses/vfc/ce.asp 您决定接种疫苗:储存和处理:https://www2a.cdc.gov/nip/isd/ycts/mod1/courses/sh/ce.asp 提供商协议:参加我们计划的每个办公室每两年签署一次提供商协议。请查看该文件,其中概述了您办公室的所有职责。如果您没有办公室最新的协议,我们的帮助台可以为您提供一份副本(877-873-6247 或 ncirhelp@dhhs.nc.gov)。

CDC免疫更新2025年2月26日
•Abrysvo®可以与百日咳(DTPA -DIPHTHERIA,TETANUS和TETTUSSIS)和流感疫苗共同管理。母体疫苗接种消费者手册|澳大利亚政府卫生和老年护理局•在“免疫计划”和报告标签下找到的NIP疫苗订单表格Abrysvo®疫苗| NT健康网站。

轮状病毒疫苗更新 - 下一代产品
WHO WHO战略咨询小组(SAGE)2020年10月 - 重申RV疫苗应包括在所有NIP中,应该是一个优先事项: - 6周龄的首次剂量。- 支持高负担设置中的赶上竞选活动。- 不建议儿童> 24个月大。- 建议使用所有四个人PQ实时衰减,口服轮状病毒疫苗。

Pharmacy-flu-rorder-form.pdf
昆士兰州健康免疫计划药房NIP资助的流感疫苗订单•流感的疫苗订单可以在消费者高峰期的有限时间内每周提交。•当每周订购退役时,需要每月订购。•步骤1 - 输入手头的疫苗数量,疫苗到期日期和所需数量•步骤2 - 将完成的表格发送到qhip-admin@health.qld.qld.gov.au
