XiaoMi-AI文件搜索系统
World File Search SystemNaive

设备使用机器学习的设备健康监测...
现代文明中科学技术的快速增长导致机械和设备的规模,复杂性和自动化的增加。现代工业生产的两个最重要方面是问题识别和机械状况监测。通过有效的状况监测使早期问题检测成为可能,这在考虑到生产效率,操作可靠性,维护成本和停机时间等变量时至关重要。研究问题的识别和机械的健康监测具有实际意义。为了进行设备监控和故障诊断的目的,记录了有关设备的温度,振动,噪声水平和润滑状态的信息。之后,该信息被用来确定该问题的主要来源,并采取补救措施。条件监视系统的核心元素是故障预测,功能提取和问题诊断。特征提取和故障诊断对于正常检测,问题定位和失败严重性预测至关重要。本文包括故障诊断和计算智能在状态监控和故障检测中的应用,本文还介绍了一种使用机器学习(ML)技术进行设备状态监测的方法。流行的机器学习(ML)分类方法,例如随机森林(RF),随机树(RT),天真贝叶斯(NB),XG Boost(XGB)和Logistic Recression(LR),用于组装。紧迫需要提高机器的可靠性并减少由于机器故障而导致的生产损失的可能性,这是对机器状况监测的越来越重视的原因。关键字:故障预测,机器学习,天真的贝叶斯,生产,随机森林,随机树,意外的停机时间。

基于眼部跟踪信号的眼睛疲劳检测特征和算法的探索“ 2279糖尿病预测的深度学习技术
糖尿病是我们社会中的一种常见疾病。每个第三人都会受到这种严重疾病的影响。这是由不规则的生活方式,不良的饮食习惯以及缺乏运动以及怀孕期间引起的。在人体中,血糖水平受胰腺释放的胰岛素激素控制。由于胰岛素激素的任何原因,由于任何原因,血糖水平也会影响。这样,一个人可能会受到糖尿病的影响。可以通过定期运动和采用健康的生活方式来治愈受影响的患者。要控制血糖水平,可以给予某些药物或可以明确给予胰岛素。要知道一个人是否受到糖尿病的影响,需要进行一些诊断。如果我们在早期了解这种疾病,我们可能会防止这种有害疾病。用于早期预测机学习技术已被使用(Kerner&Bruckel,2014)。机器学习技术从数据集中学习以预测结果。Some data is used as a training data which is used to train and then we can perform prediction using test data (Bottou,2014).For early stage diabetes prediction the various researchers have been used Support Vector Machine(Vishwanathan et al.,2002),Naive Bayes (Rish,2001), Artificial Neural Network (Wang,2003), Decision tree (Safavian et al.,1991)(Pal,2005),K nearest Neighbour (Liao&Vemuri,2002),LSTM(长期记忆)(Sherstinsky,2020)。

一种用于充血性心力衰竭预测的集成机器学习方法
摘要:充血性心力衰竭(CHF)是全球人口中死亡率和发病率的主要来源之一。全球超过2600万个人受心脏病的影响,其患病率每年增加2%。随着医疗保健技术的进步,如果我们在早期阶段预测CHF,则可以减少全球领先的死亡率因素之一。 因此,这项研究的主要目的是使用机器学习应用来增强CHF的诊断,并通过采用最低特征来预测发生CHF的可能性,以降低诊断成本。 我们使用深层神经网络(DNN)分类器进行CHF分类,并将DNN的性能与各种机器学习分类器进行比较。 在这项研究中,我们使用了一个非常具有挑战性的数据集,称为心血管健康研究(CHS)数据集,以及通过整合C4.5和K-Nearest邻居(KNN)的独特预处理技术。 虽然C4.5技术用于查找重要功能并从数据集中删除异常数据,但使用KNN算法用于缺失数据。 为分类,我们比较了六个最先进的机器学习(ML)算法(KNN,Logistic回归(LR),Naive Bayes(NB),Random Forest(RF),支持向量机(SVM)和决策树(DT))。 为了评估性能,我们使用七个统计测量值(即准确性,特异性,灵敏度,F1得分,精度,Matthew的相关系数和假阳性率)。 提出的模型获得了97.03%的F1得分,95.30%的精度,96.49%的灵敏度和97.58%的精度。随着医疗保健技术的进步,如果我们在早期阶段预测CHF,则可以减少全球领先的死亡率因素之一。因此,这项研究的主要目的是使用机器学习应用来增强CHF的诊断,并通过采用最低特征来预测发生CHF的可能性,以降低诊断成本。我们使用深层神经网络(DNN)分类器进行CHF分类,并将DNN的性能与各种机器学习分类器进行比较。在这项研究中,我们使用了一个非常具有挑战性的数据集,称为心血管健康研究(CHS)数据集,以及通过整合C4.5和K-Nearest邻居(KNN)的独特预处理技术。虽然C4.5技术用于查找重要功能并从数据集中删除异常数据,但使用KNN算法用于缺失数据。为分类,我们比较了六个最先进的机器学习(ML)算法(KNN,Logistic回归(LR),Naive Bayes(NB),Random Forest(RF),支持向量机(SVM)和决策树(DT))。为了评估性能,我们使用七个统计测量值(即准确性,特异性,灵敏度,F1得分,精度,Matthew的相关系数和假阳性率)。提出的模型获得了97.03%的F1得分,95.30%的精度,96.49%的灵敏度和97.58%的精度。总的来说,我们的结果反映了我们提出的综合方法,从CHF预测方面,它优于其他机器学习算法,从而减少了医疗测试的数量来减少患者费用。

迈向人机交互决策科学
“浅层”模型:逻辑回归[16、39、41、45、68、86、106、143],线性回归[28、37、101、111],广义加性模型∗(GAM)[1、13、39、43、49、128、135],决策树 / 随机森林[29、45、54、55、86、92、97、137、144、155],支持向量机(SVM)[41、80、81、86、94、114、147、 152]、贝叶斯决策列表[82]、K最近邻[77]、浅层(1至2层)神经网络[45,106]、朴素贝叶斯[125]、矩阵分解[78]
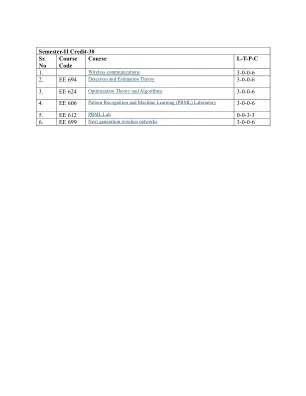
学期-II Credit-30 Sr.没有课程代码课程LTPC 1。
概率理论的概述,线性代数,凸优化。简介:模式识别和机器学习的历史,模式识别和机器学习重点的区别。回归:线性回归,多元回归,逻辑回归。聚类:分区聚类,分层聚类,桦木算法治疗算法,基于密度的基于密度的聚类PCA和LDA:主成分分析,线性判别分析。内核方法:支持向量机图形模型:高斯混合模型和隐藏的马尔可夫模型贝叶斯方法的简介:贝叶斯分类,贝叶斯学习,贝叶斯最佳分类器,天真的贝叶斯分类器和贝叶斯网络..
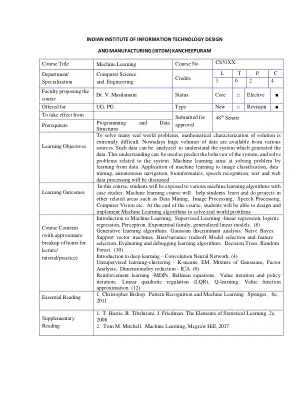
机器学习(4个学分)
机器学习介绍,监督学习 - 线性回归,逻辑回归,感知。指数族,广义线性模型。(8)生成学习算法。高斯判别分析。幼稚的贝叶斯。支持向量机。偏见/方差权衡模型选择和特征选择。评估和调试学习算法,决策树,随机森林。(10)深度学习简介 - 卷积神经网络。(4)无监督的学习聚类 - k-均值,em,高斯的混合物,因子分析。降低降低 - ICA。(8)增强学习-MDP,Bellman方程,价值迭代和政策迭代,线性二次调节(LQR),Q学习。值函数近似。(12)

最小量子玻璃模型的光谱统计
在量子场理论的背景下,研究了最近提出的可集成性破坏性扰动的分类。使用随机矩阵方法诊断所得的量子混沌行为,我们通过考虑poissonian和wigner-dyson分布之间的交叉分布在被截断为有限的二维Hilbert空间的系统中,研究了大规模标量的φ4和φ6相互作用。我们发现,跨界耦合与旋转链中的体积的缩放缩放的天真延伸并不能为量子场理论带来令人满意的结果。相反,我们证明,考虑到交叉耦合与粒子数量的缩放率会产生强大的特征,并能够区分φ4和φ6量子场理论中的可集成性破坏的强度。

接受骨髓纤维化治疗的患者
二项式反应/无反应终点可能无法完全表征骨髓纤维化治疗的贫血相关益处。在这些对来自第 2 和第 3 阶段试验的骨髓纤维化患者随时间输血负担的新分析中,momelotinib 与未使用和使用过 JAK 抑制剂的人群的平均红细胞输血负担减少有关。在所有试验中,≥ 77% 接受 momelotinib 治疗的患者与基线相比保持或经历了输血强度的改善,这突出表明 momelotinib 为大多数骨髓纤维化患者提供了持续的贫血益处。目的:贫血是骨髓纤维化的主要特征,通常通过红细胞 (RBC) 输血进行治疗,这可能导致负面预后、生活质量和医疗保健相关的经济影响。 Janus 激酶 (JAK) 1/JAK2/激活素 A 受体 1 型抑制剂 momelotinib 获批用于治疗骨髓纤维化和贫血患者,其依据是临床试验中贫血、脾脏和症状获益的证据,这些获益以二项式反应/无反应终点表示。在本事后描述性分析中,进一步描述了 momelotinib 对未使用和使用过 JAK 抑制剂的患者中 RBC 输血负担随时间的影响。方法:在基线和 24 周治疗期间收集所有输血的 RBC 单位,最初在单组 2 期研究中作为概念验证分析,然后在 3 期 SIMPLIFY-1、SIMPLIFY-2 和 MOMENTUM 研究中分别与对照药物(芦可替尼、最佳可用疗法 [BAT] 和达那唑)进行比较。结果:在第 2 阶段研究中,平均输血需求变化为 -1.5 单位/28 天,85% 的患者 (35/41) 实现了输血量数字减少。在 SIMPLIFY-1、SIMPLIFY-2 和 MOMENTUM 中,平均输血需求下降

心脏疾病诊断 - 使用 - 诊断 - 与...
摘要:治疗医疗数据的进步每天都会显着增长。准确的数据分类模型可以帮助确定患者疾病并诊断医疗领域的疾病严重程度,从而减轻医生的治疗负担。尽管如此,医疗数据分析列出了由于不确定性,各种测量和数据的高维度之间的相关性而引起的挑战。这些挑战负担统计分类模型。机器学习(ML)和数据挖掘方法已被证明在近年来有效地了解了这些方面的重要性。这项研究采用了名为决策树(DT)的众所周知的监督学习分类模型。dt是一种典型的树结构,由中央节点,连接的分支以及内部和末端节点组成。在每个节点中,我们都必须做出决定,例如基于规则的系统。这种类型的模型可帮助研究人员和医生更好地诊断疾病。为了降低所提出的DT的复杂性,我们使用特征选择(FS)方法探索了更简单的诊断模型,其因素较少。此概念将有助于减少数据收集阶段。在开发的DT和其他各种ML模型之间进行了比较分析,例如Logistic回归(LR),支持向量机(SVM)和Gaussian Naive Bayes(GNB),以证明已开发模型的有效性。DT模型的结果建立了93.78%的明显精度,ROC值为0.94,比其他算法比其他算法。开发的DT模型提供了有希望的结果,并可以帮助诊断心脏病。

在视觉状态空间模型中探索令牌修剪
状态空间模型(SSM)具有与变压器的注意模块相比保持线性计算复杂性的优势,并且已将视觉任务应用于视觉任务作为一种新型强大的视觉基础模型。受到观察的启发,即视觉变压器(VIT)的最终预测仅基于最有用的代币的子集,我们采取了新的步骤,即通过基于令牌的修剪来提高基于SSM的视力模型的效率。但是,即使经过广泛的微调,为VIT设计的现有代币修剪技术的直接应用也无法提供良好的性能。为了解决此问题,我们重新审视了SSM的独特计算特征,并发现Naive Application破坏了顺序令牌位置。这种洞察力促使我们设计了一种专门针对基于SSM的视力模型的新颖和通用的代币修剪方法。我们首先引入一种修剪感知的隐藏状态对准方法,以稳定剩余令牌以增强性能的邻里。此外,根据我们的详细分析,我们提出了一种适用于SSM模型的令牌重要性评估方法,以指导令牌修剪。采用有效的实施和实际加速方法,我们的方法带来了实际的加速。广泛的实验表明,我们的方法可以实现大量的计算减少,而对不同任务的性能的影响最小。值得注意的是,我们在成像网上获得了81.7%的精度,而修剪的plainmamba-l3的拖鞋降低了41.6%。此外,我们的工作为了解基于SSM的视力模型的行为提供了更深入的见解。