XiaoMi-AI文件搜索系统
World File Search SystemNeighbor

基于脑电信号的个人热舒适度预测
与仅使用问卷相比,需要对热舒适条件进行定量测量才能获得更有效的测量结果。本研究旨在使用脑电图 (EEG) 信号进行初步研究,以预测室内环境中的个人热舒适度。个人的满意度或不满意度描述了个人对热条件暴露的热舒适度。本研究应用的分类方法是 k-最近邻分类。所得结果表明,大脑的枕叶(以 O2 通道为代表)和额叶(以 FC5 通道为代表)被怀疑可以量化个人热舒适度。量化是在 O2 通道中的 delta(0-4 Hz)和 theta(4-8 Hz)频带以及 FC5 通道中的 beta(13-30 Hz)频带中生成的。k-最近邻算法的准确率为 85%,适合预测个人热舒适度。

福音派计划form_sample_2
- !建立健康和建立友谊部 - 人员,预算等。(Jan) - !打招呼您的邻居友谊福音派重点(Mar -May) - !社区卫生诊所或博览会(JUN) - !每月晚餐俱乐部举行健康演讲(Jun -Sep) - !度假圣经学校(JUL) - !神圣音乐会(Aug)

使用级联集成学习从多光谱 MRI 数据中分割脑肿瘤*
摘要 — 集成学习方法经常用于医疗决策支持。在图像分割问题中,基于集成的决策需要后处理,因为集成不能充分处理相邻体素的强相关性。本文提出了一种基于集成级联的脑肿瘤分割程序。第一个由二叉决策树组成的集成经过训练,基于 4 个观察特征和 100 个计算特征将局灶性病变与正常组织分离。从第一个集成提供的中间标签开始,为每个体素计算六个局部特征,作为第二个集成的输入。第二个集成是一个经典的随机森林,它加强了相邻像素之间的相关性,使病变的形状规则化。分割准确率为 85.5% 的整体 Dice Score,比之前的解决方案高出 0.5%。索引词 — 图像分割、脑肿瘤分割、磁共振成像、集成学习。

模仿学习2-机器人学习
(i)学习πθ1:z 7→u(z包含一些“地面真相”数据,例如状态,交通信号灯,邻居行为)(ii)使用πθ1生成数据d = {(x i 1:t i 1:t i,u I 1:t i)} n i = 1(iii)
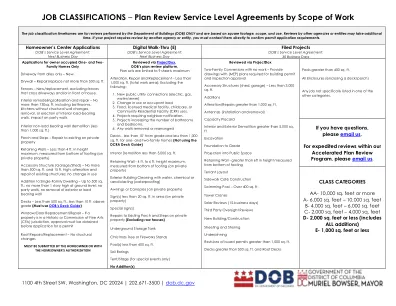
工作分类 – 根据工作范围审查服务水平协议
1. 新的公共设施连接(电力、煤气、水/下水道) 2. 用途或居住负荷的变化 3. 食品、持牌医疗机构、儿童保育或社区住宅设施 (CRF) 用途。 4. 需要邻居通知的项目。 5. 增加浴室和卧室数量的项目。 6. 拆除或重新布置任何墙壁

IE360系列IE360系列
IPv6功能RFC 1981 IPv6 RFC 2460 IPv6规格RFC 2464 IPV6数据包在以太网网络RFC 3484 IPV6 RFC选择IPv6 RFC 3587 IPV6 IPV6全局UNICAST地址ipv6 rfc 3596 DNS EPV6 RFF6 RFC SCRETCERTY 7 ipv6 rfc 3484的默认地址SCRETRECTIOS ipv6 rfc 3484 IPV6规格RFC 2464 IPV6规格RFC 2464 IPV6分支机构ipv6 rfc 3596 dns rff6 rff6 RFC 4193 Unique local IPv6 unicast addresses RFC 4213 Transition mechanisms for IPv6 hosts and routers RFC 4291 IPv6 addressing architecture RFC 4443 Internet Control Message Protocol (ICMPv6) RFC 4861 Neighbor discovery for IPv6 RFC 4862 IPv6 Stateless Address Auto-Configuration (SLAAC) RFC 5014 IPv6套接字API用于源地址选择RFC 5095 IPv6 RFC 5175 IPv6 Router Advertisement(RA)标志的type 0路由标头的弃用(RFC 6105 IPV6 IPV6 Router Advertisement(RA)Guard

使用
摘要研究研究了三种分类算法,即使用来自Kaggle的数据集对糖尿病的分类进行分类,以分类糖尿病。k-nn使用欧几里得距离公式依靠测试和训练数据之间的距离计算。K的选择,代表最近的邻居,显着影响K-NN的有效性。天真的贝叶斯是一种概率方法,可以根据过去事件预测类概率,并采用高斯分布方法进行连续数据。决策树,以易于实现的规则形成预测模型。数据收集涉及获取具有八个属性的糖尿病的糖尿病数据集。数据预处理包括清洁和归一化,以最大程度地减少不一致和数据不完整的数据。使用RapidMiner工具应用了分类算法,并比较结果的准确性。天真的贝叶斯产生77.34%的精度,K-NN的性能取决于所选的K值,而决策树生成了分类规则。该研究提供了对糖尿病分类每种算法的优势和缺点的见解。关键字:分类算法,决策树,糖尿病,k-nearest邻居,幼稚的贝叶斯1。引言技术的发展和持续的时间发展对人类生活方式产生了重大影响,人类的生活方式正在迅速从传统变为现代。这些改变还带来了疾病出现模式的改变,尤其是与个人生活方式相关的疾病[1]。一种不健康的生活方式有助于肥胖,高血压,冠心病和糖尿病等疾病的发展。糖尿病,通常称为糖尿病,是一种长期代谢疾病,其血糖水平高于正常水平[2]。高糖水平是由于人体无法将食物加工成能量而引起的[1]。

基于物理的非均匀热电子模型...
图。2反极图(IPF),显示了使用最近的邻居算法将晶粒方向分组为八个方向组之一。颜色指示分配给每个方向组的工作函数值,这是W表面的功能值,其最稳定的化学计量学BA-O通过密度功能理论(DFT)计算得出。

k-nearest-neymen-nighbor学习基于糖果 - 糖 -
如今,EHealth Service已成为一个蓬勃发展的领域,该领域是指基于计算机的医疗保健和信息提供,以在本地,区域和全球改善卫生服务。 通过分析电子健康数据不仅可以照顾患者,而且还通过相应的数据驱动的eHealth Systems提供服务,有效的疾病风险预测模型。 在本文中,我们特别关注预测和分析糖尿病,这是一种日益普遍的慢性疾病,是指在长时间内以高血糖水平为特征的一组代谢性疾病。 k-nearest邻居(KNN)是利用相关健康数据建立这种疾病风险预测模型的最流行和最简单的机器学习技术之一。 为了实现我们的目标,我们提出了基于患者在各个维度中的习惯属性的基于基于学习的预测模型的最佳K-最近的邻居(OPT-KNN)。 此方法确定了误差率较低的最佳邻居数,以在结果模型中提供更好的预测结果。 该机器学习eHealth模型的效果通过对医疗医院收集的现实世界糖尿病数据进行实验来检查。如今,EHealth Service已成为一个蓬勃发展的领域,该领域是指基于计算机的医疗保健和信息提供,以在本地,区域和全球改善卫生服务。通过分析电子健康数据不仅可以照顾患者,而且还通过相应的数据驱动的eHealth Systems提供服务,有效的疾病风险预测模型。 在本文中,我们特别关注预测和分析糖尿病,这是一种日益普遍的慢性疾病,是指在长时间内以高血糖水平为特征的一组代谢性疾病。 k-nearest邻居(KNN)是利用相关健康数据建立这种疾病风险预测模型的最流行和最简单的机器学习技术之一。 为了实现我们的目标,我们提出了基于患者在各个维度中的习惯属性的基于基于学习的预测模型的最佳K-最近的邻居(OPT-KNN)。 此方法确定了误差率较低的最佳邻居数,以在结果模型中提供更好的预测结果。 该机器学习eHealth模型的效果通过对医疗医院收集的现实世界糖尿病数据进行实验来检查。有效的疾病风险预测模型。在本文中,我们特别关注预测和分析糖尿病,这是一种日益普遍的慢性疾病,是指在长时间内以高血糖水平为特征的一组代谢性疾病。k-nearest邻居(KNN)是利用相关健康数据建立这种疾病风险预测模型的最流行和最简单的机器学习技术之一。为了实现我们的目标,我们提出了基于患者在各个维度中的习惯属性的基于基于学习的预测模型的最佳K-最近的邻居(OPT-KNN)。此方法确定了误差率较低的最佳邻居数,以在结果模型中提供更好的预测结果。该机器学习eHealth模型的效果通过对医疗医院收集的现实世界糖尿病数据进行实验来检查。

应用KNN机器学习和模糊C均值诊断糖尿病
这种疾病在人类中是普遍的。攻击人类的疾病不认识任何人,也不知道年龄。一个人所经历的疾病从普通水平开始,直到可能严重到处于死亡风险的地步。在这项研究中,进行了早期诊断与糖尿病有关的糖尿病是糖尿病是患者体内糖水平低于正常水平的疾病。受害人经历的症状包括频繁的口渴,尿液频繁,频繁饥饿和体重减轻。基于这些问题,需要一个系统可以快速发现患者所经历的诊断。这项研究旨在根据早期症状在早期诊断糖尿病。使用的方法是基于KNN和基于Web的模糊C均值。创建基于Web的系统可以代表医疗人员专家以快速诊断的糖尿病方法。该系统是嵌入糖尿病特征的计算机程序。测试KNN和模糊的C均应用程序的应用和方法对于K-最近的邻居方法的准确度为96%,而对于使用混淆矩阵计算的模糊C-Means方法,获得了96%的精确度,因此可以得出结论,因此可以得出结论,即Fuzzy C-Means方法比K-nearears方法更好。