XiaoMi-AI文件搜索系统
World File Search SystemPDFs

pdfgpt:使用生成AI
基于文档的知识检索系统迅速发展,随着检索功能增强的生成(RAG)和大型语言模型(LLMS)的兴起,在传统的关键字驱动的检索方法中提供了以前无法获得的深度和准确性的水平。抹布架构将大语言模型(LLMS)的生成能力与信息检索的精确度相结合。这种方法有可能重新定义我们如何与生成模型中的结构化和非结构化知识相互作用,以提高响应的透明度,准确性和上下文性[1]。但是,当今的许多基于破布和LLM的应用程序都锁定在高使用成本的背后,这使得对广泛的受众无法接触,尤其是在教育和非商业环境中。

通过Mellin空间中可解释的潜在表示学习PDF
代表质子和其他黑龙的Parton分布函数(PDF)通过柔性,高保真的参数化已成为粒子物理现象学的长期目标。尤其如此,因为所选的参数化方法可以在QCD全局分析中提取的最终PDF不确定性中起影响力。反过来,这些通常是LHC和其他设施到非标准物理的实验范围的确定性,包括在大X上,参数化效应可能很重要。在这项研究中,我们探索了一系列具有各种神经网络拓扑的编码器 - 模型学习(ML)模型,作为从可解释的潜在空间中存储的有意义的信息中重建PDF的有效手段。鉴于最近努力在QCD分析和晶格规范计算之间进行协同效应,我们根据PDF在Mellin空间中的行为(即它们的综合力矩)制定了潜在表示,并测试了各种模型从该信息中解释PDF的能力。我们引入了一个数值软件包PDFDE-CODER,该软件包实现了几种编码器模型,以重建具有高忠诚度的PDF,并使用此端到端工具来探索基于神经网络的模型可能如何将PDF Para-para-para-para-质量连接到诸如其Melllin Moments之类的属性属性。我们还剖析了编码的Mellin矩和重建的PDF之间学习相关性的模式,这些模式提出了进一步改进基于ML的PDF参数化方法和不确定性量化的机会。

英国——国家官员的外国刑事管辖豁免
1 最近一次是在第六委员会第 77 届会议(https://www.un.org/en/ga/sixth/77/pdfs/statements/ilc/28mtg_uk_2.pdf)、第 76 届会议(https://www.un.org/en/ga/sixth/76/pdfs/statements/ilc/21mtg_uk_2.pdf)、第 74 届会议(https://www.un.org/en/ga/sixth/74/pdfs/statements/ilc/uk_2.pdf)、第 73 届会议(https://www.un.org/en/ga/sixth/73/pdfs/statements/ilc/uk_3.pdf)和第 72 届会议(https://www.un.org/en/ga/sixth/72/pdfs/statements/ilc/uk_2.pdf)。

保持钢铁
“消费者的铁事实” https://ods.od.nih.gov/pdf/factsheets/iron-consumer.pdf可读性 - 毕业7。在西班牙语中可用,可在https://ods.od.nih.gov/pdf/factsheets/iron-datosenespanol.pdf“保持铁上保持强壮”。 http://www.onlineordersff.com/images/pdfs/6706.pdf Rearsibaly - 7年级可在西班牙语中获得http://www.onlineordersff.com/images/images/pdfs/pdfs/6707.pdf

adalimumab生物仿制药跟踪
*https://www.drugchannels.net/2024/06/drug-channels-news-news-news-news-news-newup-june-2024.html ** dam/resources/pdfs/guides/formularies/Jan2024_Premium_Standard_Abridged_508.pdf***https://www.optum.com/content/dam/o4-dam/resources/pdfs/guides/formularies/Jan2024_Premium_Standard_Abridged_508.pdf Source: IQVIA LAAD 3.0,美国市场访问策略咨询分析

对能源储能应用的离散和统一可逆燃料电池的技术经济分析
[4] HFTO,质子交换膜电解的技术目标。https://www.energy.gov/eere/fuelcells/technical-targets-proton-exchange-membrane-electrolysross [6] Marcinkoski等人,氢氢级8级长途卡车目标(2019)。https://www.hydrogen.energy.gov/pdfs/19006_hydrogen_class8_long_haul_haul_truck_targets.pdf [7] B. James,燃油电池成本和性能分析(2022)。https://www.hydrogen.energy.gov/docs/hydrogenprogragmlibraries/pdfs/review22/review22/fc353_james_2022_o-pdf.pdf.pdf?status=master = master [8] badgett et al。NREL/TP-6A20-8762500。

纽约州医疗补助药脊髓灰质炎疫苗的覆盖范围
•FFS索赔问题应致电(800)343-9000到EMEDNY呼叫中心。•FFS的承保范围和政策问题应通过电话(518)486-3209或通过电子邮件nyrx@health.ny.gov直接致电医疗补助药房政策部门。•MMC报销,计费和/或文档要求问题应针对入学者的MMC计划。•MMC计划联系信息可以在纽约州纽约州医疗补助计划信息中找到所有提供者 - 托管护理信息文档,位于以下位置:https://www.emedny.org/providermanuals/allproviders/pproviders/pdfs/pdfs/pdfs/pdfs/information_for_for_providers_providers_man aged_care_care_care_information。• For additional information regarding NYS Pharmacy FFS vaccine billing guidance please refer to the Pharmacists as Immunizers Fact Sheet found here: https://www.health.ny.gov/health_care/medicaid/program/phar_immun_fact.htm • Additional information regarding the Polio virus (Poliomyelitis) and the IPV vaccine, including NYS specific polio virus疫苗建议可在纽约州卫生部的“传染病事实说明”网页上获得:脊髓灰质炎(脊髓灰质炎,婴儿瘫痪)(NY.GOV)

印度空间与核能计划针对 SSC 和铁路...
我们考试专家团队制作了“BOOST UP PDFS”系列,提供关于推理、定量能力、英语部分和一般意识部分的所有主题的最佳免费 PDF 学习材料。此 Boost Up PDF 为您提供不同级别的问题,包括简单、中等和困难,以及新模式问题。我们还提供 SSC 和 RRB 考试的所有学习材料。每个 PDF 包含 50 个问题及其解释。有关更多 PDF,请访问:pdf.exampundit.in

考虑使用基孔肯雅疫苗时需评估的因素
链接:https://www.cdc.gov/chikungunya/media/pdfs/2024/05/Chikungunya-vaccine-risk-factors-508.pdf
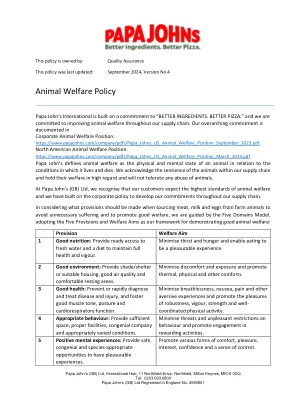
动物福利政策
帕帕·约翰(Papa John)的国际国家以对“更好的成分”的承诺为基础。更好的披萨。”我们致力于在整个供应链中改善动物福利我们的总体承诺记录在企业动物福利职位上:https://www.papajohns.com/company/company/pdfs/papa_johns_us_animal_welfare_position_position_position_sptemper_september_september_september_2023.pdf。北美动物福利职位:https://www.papajohns.com/company/company/pdfs/papa_johns_us_us_animal_welfare_position_position_march_2024.pdf papa papa john's将动物福利定义为与生命和dies相关的动物的物理和心理状态。我们承认供应链中动物的感知,并高度重视他们的福利,并且不会容忍任何对动物的虐待。