XiaoMi-AI文件搜索系统
World File Search SystemPLE

推动行为还是提升能力?
深度学习 (DL) 是机器学习 (ML) 的一个子领域,专注于开发深度神经网络 (DNN) 模型 (Shahroudnejad,2021)。DNN 是能够在各种任务上实现高性能的复杂模型。许多深度神经网络模型都是不可解释的黑匣子,这通常导致用户对它们的信任度降低 (Miller,2019)。这种可解释性和信任度的缺乏可能会产生负面影响——人们可能会使用会犯错误的人工智能,或者不使用可以提高获得期望结果的机会的人工智能。为了提高黑盒模型的可解释性和可信度,可解释人工智能 (XAI) 研究专注于开发方法来以人类可以理解的方式解释这些模型的行为 (Molnar,2020)。

国际标准分类 - ISO
如果标准的内容不能明确其应用领域,索引编制者可以考虑负责制定该标准的相关技术委员会、分委员会和工作组的范围。3.3 ICS 的字母索引可用作识别适当领域、组、子组的补充工具,但索引中找到的符号应与系统表仔细核对。原因是只有系统表包含与组符号有关的完整信息,例如其标题、所属领域、子组的细分、有时的范围说明以及显示其与其他组或子组关系的参考说明。否则可能会出现索引错误。3.4 建议使用所有可用的级别对给定标准进行分类。例如,标准

FCS 3-540:糖尿病管理
当人们进行体育锻炼时,身体会消耗能量,从而降低血糖水平。规律的运动是管理血糖水平的有效工具。美国糖尿病协会建议每周锻炼 150 分钟。将这段时间分散到五到七天有助于将锻炼纳入时间表。考虑每天多次散步 10 分钟,例如饭后或零食后。美国糖尿病协会建议两次运动之间的间隔不要超过 48 小时,以保持肌肉处于使用葡萄糖的状态,帮助管理运动后的血糖水平。体育锻炼有助于管理血糖水平并支持心脏健康。在开始或改变活动水平之前,请咨询医疗保健提供者。
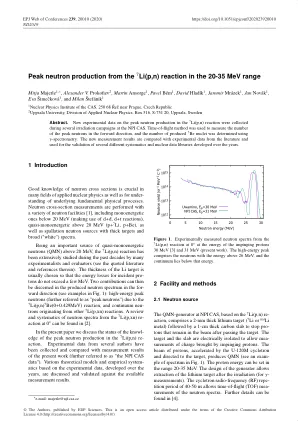
在20-35 MEV范围内从7LI(P,N)反应中的中子产生峰值
基于7 li(p,n)的NPI CAS的QMN生成器,包括一个2毫米厚的锂靶(7 li或nat li Metal),然后是1厘米厚的碳板,以停止在通过目标后保留在束中的碳纤维板。靶标和平板是电隔离的,以允许通过撞击质子带来的电荷进行调查。由U-120m的回旋子加速并导向目标的质子束(请参见图。1)。质子能可以设置在20-35 MeV范围内。发电机的设计允许在辐照后提取锂靶(用于γ-测量)。40-50 ns的回旋射频(RF)复活周期允许中子光谱的流动时间(TOF)调查。可以在[4]中找到更多细节。

补充信息:使用中性原子并行实现高保真多量子比特门
我们使用 795 nm 拉曼激光器驱动量子比特状态之间的跃迁,该激光器从 5 S 1 / 2 到 5 P 1 / 2 跃迁红失谐 2 π × 100 GHz。我们将激光器耦合到基于光纤的 Mach-Zehnder 强度调制器 (Jenoptik AM785),该调制器在最小透射附近进行直流偏置。调制器以量子比特频率的一半 (ω 01 = 2 π × 6.83 GHz) 驱动,从而产生 ± 2 π × 3.42 GHz 的边带,而载波和高阶边带受到强烈抑制。与其他通过相位调制产生边带然后使用自由空间光腔或干涉仪单独抑制载波模式的方法相比,这种方法在一天的时间尺度上是被动稳定的,无需任何主动反馈。拉曼激光沿着原子阵列排列(与 8.5 G 偏置磁场共线),并且 σ +

全球卫生公共产品——nOPV2 给我们的启示。......
根除传染病是实现卫生领域全球公共利益的一个例子。迄今为止,人类中只有一种传染病——天花被根除。根除脊髓灰质炎被视为全球卫生公共利益,因为一旦实现,它将为所有国家带来普遍利益,不会排除任何人或区分任何群体。根除脊髓灰质炎需要集体努力,并带来健康和经济效益。新型口服脊髓灰质炎疫苗 2 型 (nOPV2) 的开发可以作为开发和提供其他全球卫生公共利益的典范,例如预防(重新)出现的传染病,例如过去几十年占新发疾病 75% 以上的人畜共患疾病。2

从控制角度看量子计算
量子计算是利用遵循量子力学定律的系统来存储和处理信息的科学[1]。量子力学在微小尺度上描述自然,其行为与我们的日常经验截然不同。在原子尺度上,系统表现出违反直觉的效应,如纠缠(一种强耦合形式)或固有的、无法解决的不确定性[2]。理查德·费曼在 20 世纪 80 年代首次提出,可以利用这些效应来以优于经典计算的方式执行计算[3]。量子计算机诞生后不久,人们就开发出了一些算法,它们可以比任何已知的经典算法更快地解决某些问题。例如,Grover 算法 [4] 可用于解决 N 元素上的非结构化搜索问题,复杂度仅为 O ( √

生成式人工智能与版权的碰撞
现在判断这将如何影响人工智能还为时过早,也不清楚其对某一特定工作岗位的影响是积极的还是消极的。研究开始强调哪些工作最有可能受到影响而不是消失 (8)。例如,图像识别等分类任务可以用人工智能来完成,这将影响那些工作涉及分类任务的工作者,如放射科医生 (7)。最近有研究表明,生成式人工智能 (特别是法学硕士) 和非生成式人工智能之间的差异 [如 (7) 所述],数百万个工作岗位可能会受到法学硕士的影响。值得注意的是,这些研究强调“影响”并不意味着“取代”。对于许多工作而言,将工作流程的某些方面自动化可能会提高生产率、从事该工作的员工的工资以及雇用该工作的员工数量。

指导学习的模型复杂性:为什么简单模型几乎总是最有效的,以及为什么它对应用研究很重要 *
受其他领域的启发,政治学家接受了将监督的学习用于词典,推断,测量和描述。这样做,他们通常使用在非社会科学环境中证明成功的相当复杂性的灵活模型。然而,这种方法的回报似乎有很大的限制,至少相对于使用非常模拟(广义线性)模型来进行此类任务的替代方案。我们解释了为什么这是,如何确定这将是真实的问题以及该如何处理。我们表明,政治学数据的内在维度很低,这意味着复杂性的回报是静音或不存在的。我们提供了一种“数据策划”理论来解释这种情况。我们的方法使我们可以诊断简单的模型是最佳的,并为寻求使用机器学习的从业者提供建议。

针对EBV糖蛋白42的高IgG滴度与鼻咽癌的较低风险相关
基于鼻咽癌EBV感染的基于抗体的筛查与中国南部等流行地区的鼻咽癌(NPC)密切相关(NPC)(1)。筛查高危抗体特征的种群可以通过改善早期诊断来减轻NPC的负担(2,3)。用于针对EBV蛋白的检查,粘膜特异性抗体(IGA),例如EBNA1和VCA病毒capsid抗原(VCA)p18和全身性抗体(IgG),针对BNLF2B可以分散患有早期NPC(2、4、5、5、5、5、5、5、5、5、5、5、5、5、5、5、5、5、5、5、5)的人。同样,通过对后来被诊断为NPC的健康个体中的抗体进行抗体(6-8)的健康个体中的抗体(6-8)。尽管此类研究揭示了NPC风险的生物标志物,但健康的EBV