XiaoMi-AI文件搜索系统
World File Search SystemPP2A
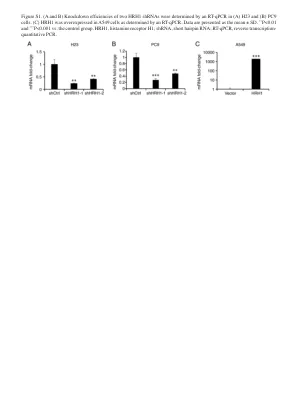
图 S1. (A 和 B) 两个 HRH1 的击倒效率......
图 S3. 使用 Cell Counting Kit-8 检测法评估分别用 10 µM SB203580(p38 抑制剂)、5 µM JNK-in-8(JNK 抑制剂)、30 µM C188(STAT3 抑制剂)或 5 nM OA(PP2A 抑制剂)处理 24 小时的 H23 和 PC9 细胞的存活率。抑制剂处理细胞的存活率以相对于载体处理细胞的百分比表示,载体处理细胞设为 100%。OA,冈田酸。

靶向化疗可克服黑色素瘤的耐药性
耐药性的出现是黑色素瘤靶向治疗成功的主要障碍。此外,常规化疗无效,因为耐药细胞通过诱导生长停滞(通常称为细胞休眠)来逃避致命的 DNA 损伤作用。我们提出了一种称为“靶向化疗”的治疗策略,通过消耗蛋白磷酸酶 2A (PP2A) 或使用小分子抑制剂(1,10-菲咯啉-5,6-二酮 [苯二酮])抑制耐药黑色素瘤。靶向化疗可诱导 DNA 损伤反应,而不会导致 DNA 断裂或允许细胞休眠。苯二酮治疗可减少 BRAF V600E 驱动的黑色素瘤患者异种移植 (PDX) 的肿瘤生长,并抑制 NRAS Q61R 驱动的黑色素瘤(一种尚无有效疗法的癌症)的生长。值得注意的是,苯二酮治疗可抑制 BRAF V600E PDX 中对 BRAF 抑制产生耐药性,凸显了其在对抗耐药性出现方面的有效性。

PRPE,一种来自枯草芽孢杆菌的PPP蛋白磷酸酶,具有异常的底物
蛋白质磷酸化或去磷酸化是在所有生物体中发现的信号传递的重要机制。多年来,蛋白激酶和磷酸酶的性质被认为在原核生物和真核生物中是不同的。证明主要发生在组氨酸和天冬氨酸残基上,而相反,通常在丝氨酸,苏氨酸或酪氨酸残基上修饰真核蛋白。然而,近年来在细菌中报道了真核样蛋白激酶和磷酸酶,相反,在真核生物中发现了原核性蛋白质的ASP酶的同源物(有关评论,请参见[1-7])。这些研究表明,真核生物和原核生物可能具有所有类型的信号转导的相似机制。蛋白磷酸酶可以根据其酶特异性(即促磷酸酶和Tyr磷酸酶)分为两组[8,9]。ser} THR磷酸酶在ITRO中显示出广泛的特异性,并已分为四类:PP1,PP2A,PP2B和PP2C,根据保守的基序,它们对抑制剂和离子的抑制剂和离子需求的敏感性[9-11]。氨基酸序列比较表明PP1,PP2A和PP2B是同一PPP家族的成员[10]。PPP家族代表了较高的真核生物中蛋白质ser}的最大蛋白质ser} [12]。这些酶还与对称的折断氨酸四磷酸酶具有序列相似性[13]。被识别的PPP家族的第一个原核生物是噬菌体λ221的乘积[14]。目前,几个成员在ARCHEA和细菌中均已详细介绍[15-19]。但是,关于生理学的数据很少

靶向阿尔茨海默氏症治疗药的异常tau磷酸化
阿尔茨海默氏病(AD)是一种广泛的神经退行性疾病,其特征是进行性记忆和认知能力下降,带来了强大的公共卫生挑战。此重新探讨了AD发病机理中两个关键玩具之间的复杂相互作用:β-淀粉样蛋白(Aβ)和tau蛋白。虽然淀粉样蛋白级联理论长期以来一直在广告研究中占主导地位,但最近的发展引发了有关其中心性的辩论。Aβ斑块和tau nfts是AD中的标志性病理。adu-canumab和lecanemab,靶向Aβ的单克隆抗体,尽管存在争议,但已得到批准,这引起了人们对以Aβ为中心的中间疗法的治疗功效的问题。另一方面,tau特别是其高磷酸化,破坏了微管稳定性,并导致神经元功能障碍。tau的各种翻译后修改将其聚集驱动到NFT中。针对tau的新兴治疗方法,例如GSK-3β和CDK5抑制剂,在临床前和临床研究中都表现出了希望。恢复蛋白激酶和磷酸酶之间的等位基库,尤其是蛋白质磷酸酶-2a(PP2A),是AD治疗的有前途的途径,因为TAU主要受其磷酸化状态的调节。tau特异性磷酸酶的激活为减轻tau病理的潜力提供了潜力。AD药物开发的不断发展的景观强调以tau为中心的疗法和淀粉样蛋白级联假设的重新评估。此外,探索神经炎症的作用及其与Tau病理学的相互作用提出了有希望的研究方向。

使用深... 的MR图像中脑肿瘤的分类 用lomitapide靶向PP2A,通过激活AMPK/Beclin1介导的自噬 基于脑肌肉混合信号的机器人手臂控制系统 通过Fastai 在脑MR扫描上检测大脑异常检测的混合体系结构
脑肿瘤是大脑中异常细胞的质量或簇,由于其能够侵入邻近组织并形成转移酶的能力,因此可能会威胁生命。准确的诊断对于成功的治疗计划和磁共振成像是必不可少的,这是诊断脑肿瘤及其程度的主要成像方式。近年来,计算机视觉应用程序中的深度学习方法已显示出显着的改进,其中大多数可以将大量数据可用于培训模型,并且模型体系结构的改进在有监督的环境中产生更好的近似值。使用这种深度学习方法对肿瘤进行分类,这使得带有可靠注释的开放数据集的可用性取得了重大进展。通常这些方法是3D模型,它使用3D体积MRI,甚至是2D模型,即分别考虑每个切片。然而,通过分别处理一个空间维度,或通过将切片作为一系列图像随着时间的推移来处理,时空模型可以用作此任务的“空间空间”模型。这些模型具有学习特定的空间和时间关系的功能,同时降低了计算成本。本文使用两个时空模型,即Resnet(2+1)D和Resnet混合卷积,以对不同类型的脑肿瘤进行分类。观察到,这两个模型的性能都优于纯3D卷积模型RESNET18。此外,还观察到,在训练肿瘤分类任务之前,将模型预先培训在不同的,甚至是无关的数据集上可以提高性能。最后,在这些实验中,预先训练的重新结合卷积是最佳模型,达到了0.9345的宏F1评分,测试准确性为96.98%,而同时是计算成本最少的模型。