XiaoMi-AI文件搜索系统
World File Search SystemPizarro

保利斯塔考试 2023 – 第三系列
(家庭化学/ Breno Pannia Espósito;Luiz Carlos Pizarro Marin 协调。第 4 版 - 圣保罗:Atual,2016 年,

ZSM-5沸石绩效评估...
Alessia Marino A,Alfredo Aloise A,B,Hector Hernando C,Javier Fermo C,Daniela Cozza A,Emanuele Giglio A,Massimo Migliore A,Patricia Pizarro C,D,D,Girolamo Giorolamo a,David P.

与自身免疫性疾病家族史的患者(PTS)患有免疫检查点抑制剂(ICI)的免疫相关不良事件(IRAE)的风险。
1。发帖,但是NEJM,2018年。 2。 HASAN,AO和AL EJC,2019年。 3。 Pizarro,C。和Al DMRR,2014年。 4。 Vaida,B。和Al 风湿病学,2002。 5。 Abdel-Whab,N和Al 在家庭医学中,2018年。 6。 Wu,C和Al 免疫疗法。 2021。 7。 Larkin,J和Al nejm,2015年。 8。 tawbi,他和al nejm,2022。 9。 riudavets,m和al oncol,2020。 10。 Favara,D和Al ESMO打开。 2020。 11。 Watson,A和Al JAMA NetW Open。 2022。NEJM,2018年。2。HASAN,AO和AL EJC,2019年。 3。 Pizarro,C。和Al DMRR,2014年。 4。 Vaida,B。和Al 风湿病学,2002。 5。 Abdel-Whab,N和Al 在家庭医学中,2018年。 6。 Wu,C和Al 免疫疗法。 2021。 7。 Larkin,J和Al nejm,2015年。 8。 tawbi,他和al nejm,2022。 9。 riudavets,m和al oncol,2020。 10。 Favara,D和Al ESMO打开。 2020。 11。 Watson,A和Al JAMA NetW Open。 2022。HASAN,AO和ALEJC,2019年。 3。 Pizarro,C。和Al DMRR,2014年。 4。 Vaida,B。和Al 风湿病学,2002。 5。 Abdel-Whab,N和Al 在家庭医学中,2018年。 6。 Wu,C和Al 免疫疗法。 2021。 7。 Larkin,J和Al nejm,2015年。 8。 tawbi,他和al nejm,2022。 9。 riudavets,m和al oncol,2020。 10。 Favara,D和Al ESMO打开。 2020。 11。 Watson,A和Al JAMA NetW Open。 2022。EJC,2019年。3。Pizarro,C。和AlDMRR,2014年。4。Vaida,B。和Al风湿病学,2002。5。Abdel-Whab,N和Al 在家庭医学中,2018年。 6。 Wu,C和Al 免疫疗法。 2021。 7。 Larkin,J和Al nejm,2015年。 8。 tawbi,他和al nejm,2022。 9。 riudavets,m和al oncol,2020。 10。 Favara,D和Al ESMO打开。 2020。 11。 Watson,A和Al JAMA NetW Open。 2022。Abdel-Whab,N和Al在家庭医学中,2018年。6。Wu,C和Al免疫疗法。2021。7。Larkin,J和Al nejm,2015年。 8。 tawbi,他和al nejm,2022。 9。 riudavets,m和al oncol,2020。 10。 Favara,D和Al ESMO打开。 2020。 11。 Watson,A和Al JAMA NetW Open。 2022。Larkin,J和Alnejm,2015年。8。tawbi,他和alnejm,2022。9。riudavets,m和aloncol,2020。10。Favara,D和Al ESMO打开。 2020。 11。 Watson,A和Al JAMA NetW Open。 2022。Favara,D和AlESMO打开。 2020。 11。 Watson,A和Al JAMA NetW Open。 2022。ESMO打开。2020。11。Watson,A和Al JAMA NetW Open。 2022。Watson,A和AlJAMA NetW Open。 2022。JAMA NetW Open。2022。


以演员为中心的可扩展土地系统类型,用于解决世界热带干燥林地中生物多样性损失
Marina Antongiovanni是Baldi,Statia antongiovanni。 Greggorio I. Gregory I. Gavier I. Pizarro或Pradeep Koulgi,Pradeep Koulgi,Daniel Mueller V,B,B,B,Robert Mueller W,Ranjini Murial A,X,X,Sofia Nanni G和,Mauricio No,AA AA A. Prieto-Torres AB,Jaysree Ratnam和Jaysree Ratnam和罗伊·罗伊(Roy Roy Roy)的聚会,菲利普·鲁芬(Philippe Rufin),A,玛丽安娜·罗芬(Mariana Roffin)和马沙·桑卡兰(Mashah Sankaran),巴斯克·托雷斯(Basque Torres)AJ,AK,Srinas Vaidanatan Al,Maria Valleys A,Am,Am,An,An,Malika Virah-Sawmy a。 Tobias Kummer。

截至2021年4月9日
A/C Sales & Services, Inc. 6/5/2017 CLB17-1327 9/7/2010 Perez, Francisco M. CLB10-0667 Corporation 201300487 AA Mechanical 3/26/2009 CLB09-0413 Tiru, Norberto Sole Proprietor 200900375 Abad's Construction 3/12/1998 7376 Abad, Cristituto C. Sole 68517 Abad的建筑3/12/1998 7376 ABAD,CRISTITUTO C. 1/22/2020 ABAD,HARRISON C. CLB20-1567唯一W/RME 98517能力解决方案,LLC 5/23/2016 Clb16-16-16-16-16-16-114 p.2014, CLB14-1047 LLC 201600100访问建筑商7/15/1997 7216 Mananes,Ismael P. Sole P. Sole Oprietor 98897 Ace Power Co.

能源技术展望 2024 - NET
Giovanni Andrean(贸易路线、港口)、Jose Miguel Bermudez(新兴市场)、Sara Budinis(战略考虑)、Leonardo Collina(钢铁、氨、贸易模型设计)、Elizabeth Connelly(新兴市场)、Laurence Cret(航运脱碳)、Chiara Delmastro(热泵、投资)、Hannes Gauch(航运脱碳)、Alexandre Gouy(商品价格、材料)、Johannes Hampp(数据管理、航运活动)、Mathilde Huismans(风能、数据管理、投资)、Jean-Baptiste Le Marois(制造业状况)、Teo Lombardo(电池、贸易模型设计)、Rafael Martínez Gordón(热泵)、Jennifer Ortiz(新兴市场)、Faidon Papadimoulis(太阳能光伏、数据管理、贸易模型设计)、Francesco Pavan(电解器)、Amalia Pizarro Alonso(工业战略、贸易政策)、Jules Sery(电动汽车)和 Richard Simon(铝、投资)。

能源技术展望 2024 - NET
Giovanni Andrean(贸易路线、港口)、Jose Miguel Bermudez(新兴市场)、Sara Budinis(战略考虑)、Leonardo Collina(钢铁、氨、贸易模型设计)、Elizabeth Connelly(新兴市场)、Laurence Cret(航运脱碳)、Chiara Delmastro(热泵、投资)、Hannes Gauch(航运脱碳)、Alexandre Gouy(商品价格、材料)、Johannes Hampp(数据管理、航运活动)、Mathilde Huismans(风能、数据管理、投资)、Jean-Baptiste Le Marois(制造业状况)、Teo Lombardo(电池、贸易模型设计)、Rafael Martínez Gordón(热泵)、Jennifer Ortiz(新兴市场)、Faidon Papadimoulis(太阳能光伏、数据管理、贸易模型设计)、Francesco Pavan(电解器)、Amalia Pizarro Alonso(工业战略、贸易政策)、Jules Sery(电动汽车)和 Richard Simon(铝、投资)。
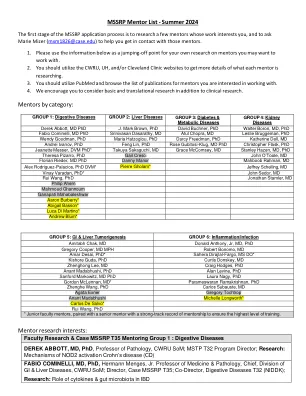
MSSRP导师列表 - 2024年夏季
疾病Derek Abbott,医学博士J.马克·布朗(Mark Brown),博士学位,大卫·布赫纳(David Buchner),博士学位,医学博士,医学博士,医学博士Fabio Cominelli,医学博士Srinivasan Dasarathy,医学博士Atul Chopra,MD Leslie Bruggeman,MD Leslie Bruggeman,博士 Rose Gubitosi-Klug, MD PhD Christopher Flask, PhD Jeanette Messer, DVM PhD* Takuya Sakaguchi, MD Grace McComsey, MD Stanley Hazen, MD, PhD Theresa Pizarro, PhD Gail Cresci John O'Toole, MD Florian Rieder, MD PhD Danny Manor Mahboob Rahman, MD Alex Rodriguez-Palacios,PhD DVM* Pierre Gholam* Jeffrey Schelling,MD Vinay Varadan,博士* John Sedor,Md Rui Wang,PhD Jonathan Stamler,MD Philip Ahern Mahern Mahmoud Ghannoum Ghannoum Ghannoum Ghannoum Ganapati Mahapati Mahabaleshwar

能源技术观点2024
Giovanni Andrean (trade routes, ports), Jose Miguel Bermudez (emerging markets), Sara Budinis (strategic considerations), Leonardo Collina (steel, ammonia, trade model design), Elizabeth Connelly (emerging markets), Laurence Cret (shipping decarbonisation), Chiara Delmastro (heat pumps, investments), Hannes Gauch (shipping脱碳),Alexandre Gouy(商品价格,材料),Johannes Hampp(数据管理,运输活动),Mathilde Huismans(Mathilde Huismans(风,数据管理,投资),Jean-Baptiste le Marois(制造业的状态),Teo Lombardo(Teo Lombardo(Teo Lombardo)(Teo Lombardo(Teo)(贸易模型设计),贸易模型设计) Faidon Papadimoulis(太阳能PV,数据管理,贸易模型设计),Francesco Pavan(Electrolysers),Amalia Pizarro Alonso(工业战略,贸易政策),Jules Sery(电动汽车)和Richard Simon(Richard Simon)(铝,投资)。