XiaoMi-AI文件搜索系统
World File Search SystemPool

与贝宁游泳池水有关的细菌
许可证:《非洲健康,安全与环境杂志》(AJHSE)的本文由Creative Commons Attribution许可证4.0国际许可证获得许可和出版,该许可允许在任何媒介中不受限制地使用,分发和复制,前提是该文章被适当地引用。版权所有:作者完全保留了本已发表文章的版权。开放访问:作者批准在开放访问(OA)模型QA中永久性地在线:本文与“ Cope(出版伦理委员会)和PIE(出版完整性与伦理学”)一致。

兴趣的表达(EOI) - 各种...
项目编号:2023.2084.4-001项目名称:促进伊拉克数字经济的就业[Prodigi] 1。简介:伊拉克的德国Gesellschaftfür国际Zusammenarbeit(Giz)GmbH在伊拉克政府代表德国联邦经济合作与发展部(BMZ)协助伊拉克政府。BMZ已委托GIZ在伊拉克(Protigi)项目中实施促进数字经济的就业。该项目旨在促进伊拉克数字经济的增长,尤其是在就业潜力方面。该项目制定了能力建设措施,支持初创企业并促进区域投资。此外,Prodigi促进了从本地利益相关者到国际利益相关者的各个层面的数字经济的合作。该项目还致力于收集数据并开发全面的数据库,并开展宣传运动,以突出伊拉克数字经济的潜力。2。所需的预期服务的摘要:预计将在未来12个月内实施10份服务合同,GIZ正在寻找具有所需经验的公司 /个人来进行服务的细节。根据以下批次对服务体验要求进行详细说明:服务批次(1):


公共游泳池翻新计划批准要求
Public pools, including swimming pools, spas, spray grounds, wading pools, and special purpose pools located at apartments, condominiums, gated communities, hotels and motels, public and private schools, health clubs, city and county parks, mobile home parks, resorts and organizations, medical facilities, and water theme parks are under the responsibility of the Los Angeles County Department of Public Health's Recreational Waters Program for plan review and approval.公共游泳池不包括单独的治疗浴缸或浴缸,以清洁每次使用后排水和填充的身体,或者在私人单户住宅或带有三个单元或更少单位的私人单户住宅或住宅中。本文档包含加利福尼亚泳池法规的基本要求,以及在洛杉矶县提交公共游泳池计划的要求。为什么需要计划?对公共卫生和安全很重要,池及其正在建造或翻新的辅助设施是正确的。计划审查和批准是确保公共游泳池满足适用的代码要求并且安全的一种经济有效的方式。《加利福尼亚州法规法规》第22条,《加利福尼亚州建筑法典》第22章为公共游泳池的建设和运营提供了法律授权和要求。

Energy Pool 成为完全独立的公司
Energy Pool 是能源转型的关键参与者,提供先进的服务和软件解决方案,以优化分布式能源资源,包括消费者、可再生能源和电力存储解决方案。我们的使命是确保尽可能多的人能够获得低二氧化碳、可靠且价格合理的能源。自 2009 年以来,Energy Pool 一直是法国灵活性市场的先驱之一,目前在全球拥有 150 多名员工,管理着 1500 多个站点。除了法国,我们还自 2015 年以来进入日本和土耳其市场,自 2019 年以来进入荷兰市场,并在约 10 个国家/地区(德国、沙特阿拉伯、马来西亚、泰国、科特迪瓦......)引领发展。

摩根士丹利(Morgan Stanley)对八倍模型进行评分申请人的偏差审核美国列出的权益期权机构客户订单处理和路由系统香港市场的MS池指南
MS Pool采用价格 /类别 /尺寸 /时间顺序匹配的优先级,这鼓励了大小并确定速度(而不是优先考虑时间超过尺寸)。出于这些目的,使用的价格将是上述有效价格。然后以相同的有效价格收到的订单将按类别(订单大小)优先考虑,然后按照收到的时间顺序匹配。代理商订单的有效价格与本金订单相同或更好的价格的优先级将比主订单更高,即使主订单的规模更大或在代理机构订单之前收到。在不同的类别中,订单在以下顺序中优先:代理商,代理商,专业交易员,本金和主要专业交易者。用户将按照该用户活动的性质和频率(或对于新用户,其预期的活动)将用户归类为“专业交易者”。确定用户是否是专业交易者的主要因素是用户的消息数。

Aquagem Inverpro完整逆变器池泵
具有最先进的控制系统,它提供了带有高级数据监视的简单,无缝操作。它还结合了一个数字显示屏,其中包含完整的面板钢化玻璃和响应式背光照明,以实现高度精致的外观。传统游泳池热泵最多可高达69%。使用内置WiFi的Invergo应用程序,您可以安排何时以及如何直接从智能手机运行。在Apple App Store和Android Google Play上可用。
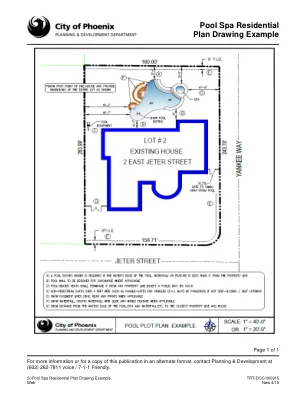
泳池水疗中心住宅平面图绘图示例
第 1 页,共 1 页 如需更多信息或获取本出版物的其他格式副本,请联系规划与开发部,电话:(602) 262-7811 语音电话/7-1-1 友好电话。S:\Pool Spa 住宅平面图示例 TRT/DOC/000915 Web New 4/15

可再生能源顾问服务池-RFQ
•在预提前会议期间讨论的信息旨在提供对资格套餐请求包含的要求的高级概述,并为潜在的公司提供机会审查和熟悉要求。口头陈述不得依赖,也不会具有约束力或具有法律作用。仅由该地区发行的书面附录构成唯一的独家记录和订婚前会议结果的声明。仅由该地区发行的书面附录构成唯一的独家记录和订婚前会议结果的声明。

EQP1735 公共游泳池检验报告
水温 ___ / ___ ° F 稳定剂 ___ / ___ mg/L 是否收集了用于细菌分析的样本? 是 否 关键: = 合规 X = 不合规 – = 不适用 规则编号或法案章节在括号中。泳池围栏和甲板浴室 1. 门或大门符合 [28(2) 和 91(1)] 24. 淋浴间、卫生间或更衣室清洁 [91(4)] 2. 泳池围栏符合 [28] 25. 浴室材料和固定装置符合 [74、75 和 76] 3. 甲板清洁、排水畅通且状况良好 [29、29a 和 91(4)] 26. 提供热水和肥皂 [25(2) 和 91(7)] 4. 泳池边淋浴符合 [78] 机械设备 5. 饮水机符合 [31] 27. 机械设备安装到位 [71] 6. 软管龙头符合 [79] 28. 管道和箭头符合 [37] 7. 提供深度标记和“禁止跳水”标志 [32] 29. 水泵充足且运行正常[36、45 和 96(1)] 8. 跳水设施和出发平台符合要求 [33 和 35] 30. 流量控制阀符合要求 [38(1)] 9. 梯子/楼梯符合要求,台阶前缘有标记 [34] 31. 流量计功能正常且流量合适 [38(2) 和 96(1)] 泳池水质和泳池结构 32. 过滤器和仪表功能正常 [51、54 和 96(1)] 10. 泳池水质清澈度和符合要求 [94] 33. 化学药剂加料器功能正常 [57、96(1) 和 96(4)] 11. 泳池侧面和底部光滑清洁 [22(3) 和 91(4)] 34. 其他空气和水泵系统符合要求 [42 和 46] 12. 泳池结构状况良好 [22 和 91(4)] 35. 热水器和温度计符合规定 [61、82 和 94(7)] 13. 标记泳池边缘、座椅和坡度变化 [23(5)、(7)、(8)] 36. 配备吸尘器 [63] 14. 水位适合撇渣 [96(3)] 37. 化学品储存得当 [91(5)] 15. 溢流系统/撇渣器正常运转且清洁 [43、43a、44] 38. 供水充足且受到保护 [25 和 26] 16. 泳池进水口符合规定 [41] 39. 废水设施充足 [27] 17. 主要出水口符合规定 [42] 40. 新设备的建造批准 [Sec. 12525] 安全一般操作 18. 救生员在岗或已张贴标志 [94a 和 98] 41. 测试工具合适并使用 [59 和 94] 19. 入浴者负荷(#_________)在限制范围内并已张贴标志 [93] 42. 随时有合格人员 [97] 20. 危险物品、食物或饮料得到控制 [92(8)] 43. 已支付操作许可证费 [第 12527 和 5(2) 条] 在上方添加许可证号 21. 生命线符合要求 [32(10) 和 91(3)] 44. 使用了操作报告表 [99] 22. 安全设备符合要求并随时可用 [65 和 91(2)] 45. 应急计划/水样采集 [94a 和 95] 23. 电话可用、明显且已张贴标志 [65(8) 和 (9)] 46. 未经建筑许可证不得进行任何改造 [第 12525 条] 备注