XiaoMi-AI文件搜索系统
World File Search SystemPromega

PCR基因分型
Reagent/Material Vendor Stock Number Molecular grade H20 Sigma-Aldrich W4502 * GoTaq® G2 Colorless Master Mix Promega M7833 DNeasy® Tissue Kit Qiagen 69506 Agarose Sigma-Aldrich A9414 1kb+ DNA ladder Life Technologies 10787-018 SYBR SAFE DNA stain Life Technologies S33102 100% ETOH Gold Shield Chemicals DSP-CA-151 *GOTAQ®G2无色主混合混合物是一种预混合的现成溶液,其中含有GOTAQ®G2DNA聚合酶,DNTP,MGCL2和反应缓冲液,可在最佳浓度下以PCR有效地放大DNA模板。GOTAQ®G2DNA聚合酶表现出5´→3´外切核酸酶活性。gotaq®G2无色主混合物,2x:GoTaq®G2DNA聚合酶在2x无色GOTAQ®G2反应缓冲液(pH 8.5),400μMDATP,400μMDGTP,400μMDCTP,400μMDCTP,400μMDTTP和3MM DTTP和3MM MGCL2中提供。

通过CRISPR-CAS9-介导的Hibit标记
许多蛋白质家族由多种高度同源蛋白组成,无论它们是由不同基因编码还是来自相同基因组位置的编码。某些同工型的优势与各种病理状况(例如癌症)有关。研究中蛋白质同工型的检测和相对定量通常是通过免疫印迹,免疫组织化学或免疫荧光来完成的,其中使用针对特定家族成员的同工型特异性表位的抗体。但是,同工型特异性抗体并非总是可用的,因此无法破译同工型特异性蛋白表达模式。在这里,我们描述了多功能11氨基酸标签的插入到感兴趣蛋白质的基因组位置中。此标签是开发的,由Promega(美国威斯康星州Fitchburg)发行。本协议描述了高度同源蛋白的精确蛋白质表达分析,通过hibit标签的表达,当缺失特定抗体时,可以实现蛋白质表达定量。可以通过传统方法(例如蛋白质印迹或免疫荧光)以及在荧光素酶二元报道器系统中分析蛋白质表达,从而可以使用板读取器进行可靠且快速的相对表达定量。
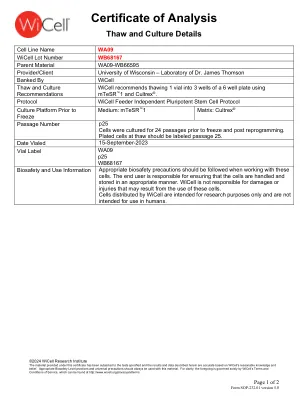
分析证书
测定描述:使用PromeGa TM使用PowerPlex 16 HS系统进行STR分析。结果据报道为13个Codis Str标记,用于确定性别的蛋白质蛋白和两个低端,高度歧视的果仁核苷酸STR标记。结果:在分析的15个STR基因座中,基因型谱构成了24-29个等位基因多态性的范围。解释:获得可接受的STR基因型(信号/噪声)所需的DNA浓度与人类基因组DNA的标准过程(〜1 ng/扩增反应)相当。这些结果表明,提交的细胞对应于命名的细胞系,且未被任何其他人类细胞或大量小鼠喂食器层细胞污染。敏感性:检测其特有的或其他人类细胞系的str多态性的灵敏度限制为〜2-4%。匹配:样本99356和99312彼此100%匹配,与97827、97437、97371、97171、97171、96184、96184、96183、95823、95823、95822、95822、93654、93654、93595和其他配置文件。可以根据要求提供其他匹配项。

同时抑制DNA-PK和Polϴ提高基因组编辑的整合效率和精度
3 数据科学与定量生物学、Discovery Sciences、生物制药研发、阿斯利康、英国剑桥 4 细胞分析开发、Discovery Sciences、生物制药研发、阿斯利康、瑞典哥德堡 5 细胞工程、Discovery Sciences、生物制药研发、阿斯利康、瑞典哥德堡 6 Promega Corporation、美国威斯康星州麦迪逊 7 转化基因组学、Discovery Sciences、生物制药研发、阿斯利康、瑞典哥德堡 8 转化科学与实验医学、研究与早期开发、呼吸与免疫学 (R&I)、生物制药研发、阿斯利康、瑞典哥德堡 9 细胞生物学与免疫学、Discovery Sciences、生物制药研发、阿斯利康、英国剑桥 10 数据科学与定量生物学、Discovery Sciences、生物制药研发部,阿斯利康,瑞典哥德堡 11 化合物合成与管理,Discovery Sciences,生物制药研发部,阿斯利康,瑞典哥德堡 43150 12 分子人工智能,Discovery Sciences,生物制药研发部,阿斯利康,瑞典哥德堡 13 Discovery Sciences,生物制药研发部,阿斯利康,英国剑桥 14 早期 TDE 发现,肿瘤学研发部,阿斯利康,英国剑桥 * 通讯联系人:电子邮件:marcello.maresca@astrazeneca.com 通讯也可寄给 Sandra Wimberger。电子邮件:sandra.wimberger@astrazeneca.com
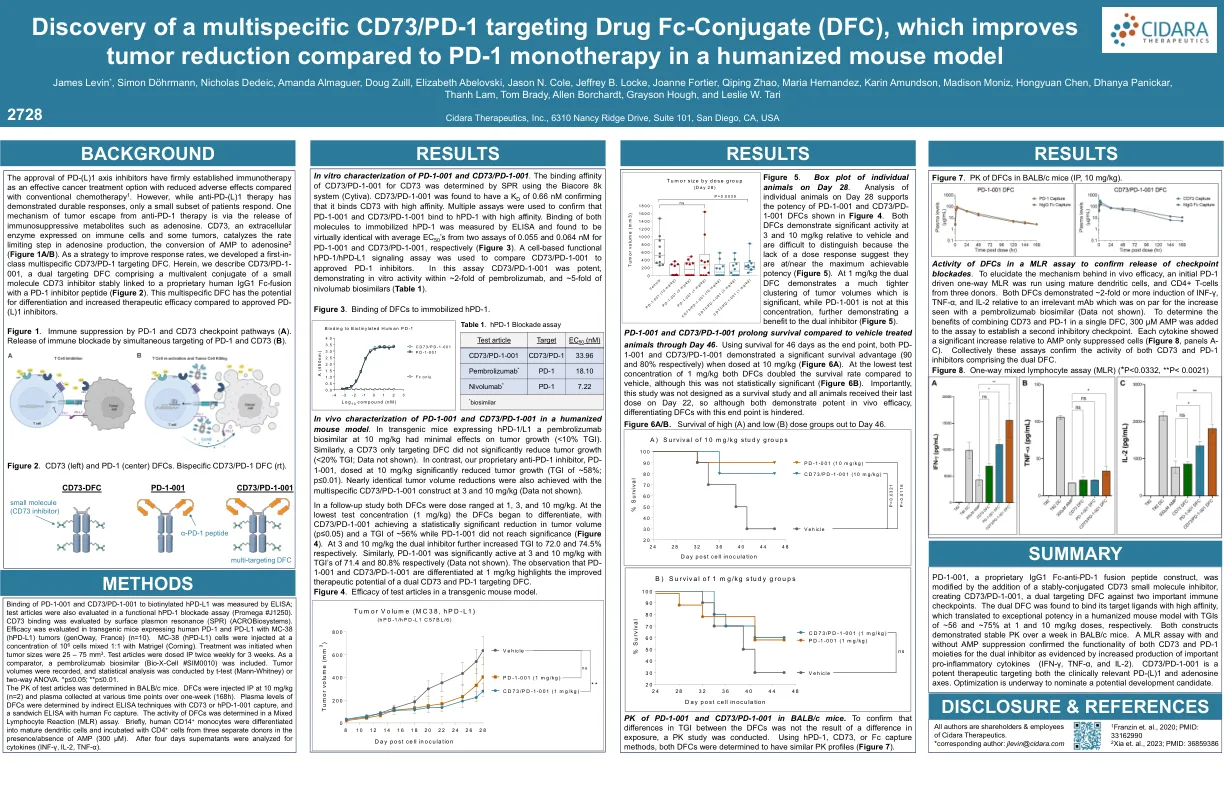
发现多特异性 CD73/PD-1 靶向药物 Fc-...
通过 ELISA 测量 PD-1-001 和 CD73/PD-1-001 与生物素化 hPD-L1 的结合;还通过功能性 hPD-1 阻断试验 (Promega #J1250) 评估了测试样品。通过表面等离子体共振 (SPR) (ACROBiosystems) 评估了 CD73 结合。在表达人类 PD-1 和 PD-L1 的转基因小鼠中评估了疗效,这些小鼠患有 MC-38 (hPD-L1) 肿瘤 (genOway,法国) (n=10)。以 10 6 个细胞的浓度注射 MC-38 (hPD-L1) 细胞,与 Matrigel (Corning) 以 1:1 混合。当肿瘤大小为 25 – 75 mm 3 时开始治疗。测试样品每周腹腔注射两次,持续 3 周。作为比较物,包括派姆单抗生物仿制药 (Bio-X-Cell #SIM0010)。记录肿瘤体积,并通过 t 检验 (Mann-Whitney) 或双向方差分析进行统计分析。 *p≤0.05;**p≤0.01。在 BALB/c 小鼠中确定测试样品的 PK。以 10 mg/kg (n=2) 的剂量腹腔注射 DFC,并在一周内 (168 小时) 的不同时间点收集血浆。通过间接 ELISA 技术 (使用 CD73 或 hPD-1-001 捕获) 和夹心 ELISA (使用人类 Fc 捕获) 确定 DFC 的血浆水平。在混合淋巴细胞反应 (MLR) 测定中确定 DFC 的活性。简而言之,人类 CD14 + 单核细胞分化为成熟的树突状细胞,并在有/无 AMP (300 µM) 的情况下与来自三个不同供体的 CD4 + 细胞一起孵育。四天后,对上清液进行细胞因子分析 (INF-γ、IL-2、TNF-α)。

机器的补充信息...
材料。Fmoc-β-amino acids, including Fmoc- L -β-homoalanine, Fmoc- L -β-homoisoleucine, Fmoc- L -β-homoleucine, Fmoc- L -β-homophenylalanine, Fmoc-(1S,2S)-2-aminocyclopentane carboxylic acid, Nβ-Fmoc-Nω-Boc- L -β-homolysine, Fmoc-O-tert-butyl- L -β-homoserine, and Fmoc-α-amino acids, including Fmoc-glycine, Fmoc- L -alanine, Fmoc- L -isoleucine, Fmoc- L - leucine, Fmoc- L -phenylalanine, Fmoc-O-tert-butyl- L -serine, FMOC-L-β-双晶,FMOC-L-主要酸β-TERT-丁基酯,FMOC-L-谷氨酸γ-tert-叔丁基酯,Nα-FMOC-Nε-boc-l-赖氨酸是从Chem-impex International,Inc.(Wood Dale,Inc.,IL,USA,USA,USA)购买的。fmoc-l-脱毛氨酸是从热科学化学品购买的。FMOC-L-Norvaline购自Santa Cruz Biotechnology。hatu是从奥克伍德化学品获得的。Tentagel S RAM FMOC购自Advanced Chemtech(肯塔基州路易斯维尔)。Menadione,N,N-二异丙甲胺,Mueller Hinton肉汤和磷酸二氮的磷酸钠,是从Sigma-Aldrich(密苏里州圣路易斯)获得的。3-(n-甲磷脂)丙烷磺酸(MOPS)获自Fisher Scientific(宾夕法尼亚州匹兹堡)。2,3-双(2-甲氧基-4-硝基-5-磺苯基)-2H-四唑-5-羧基(XTT)购自从Invitrogen购买。Gibco Brand RPMI 1640粉末(含有苯酚红和L-谷氨酰胺,没有碳酸氢钠或HEPES)和Dulbecco的磷酸盐缓冲盐水(DPB,无钙或镁)是从Thermo Fisher Scientific(MA)获得的。使用Millipore过滤系统纯化水(18.2MΩ)。细胞滴度GLO 2.0分析套件来自Promega(WI)。

修改的协议Wizard®基因组DNA纯化套件...
修改的方案向导®基因组DNA纯化试剂盒的基因组纯化试剂盒通过离心在10ml颗粒2ml中通过离心在13,000 rpm 1以13,000 rpm 1恢复5分钟,在540 µl EDTA中重悬于540 µl的EDTA中,在50 mm,PH 87 µL,pH 30 µl,在10 mg lysozeme中,lysozym/c在10 mL在13,000 rpm丢弃的13,000 rpm处离心3分钟,将沉淀物恢复为600 µl的“核酸溶液”(来自KIT),并在80°C下混合热量5分钟(允许下一步冷却至下一步)加入3 µL RNase(从KIT中)添加3 µL RNase(从KIT中)在37°C下添加200 µL,并加入200 µL(oft of kit)(oft of of kit),并加入200 µL(oft of of of kit)(oft of of Kit)。 ice for 5 min Centrifuge for 3 min at 13,000 rpm TRANSFER supernatant to a 1.5 mL tube Add 600 µL isopropanol at ambient temperature Mix by inverting the tube Centrifuge for 3 min at 13,000 rpm DISCARD the supernatant 2 Add 600 µL of 70% ethanol at ambient temperature Centrifuge for 3 min at 13,000 rpm 3 DISCARD ethanol Dry pellet at 37°C在50-100 µL的水或洗脱缓冲液中重悬于gDNA(套件):如果需要更多的DNA,则每个培养物多个管子以上一个管。这些可以在较小的体积中洗脱,并在洗脱步骤中合并。根据细菌菌株以达到所需的DNA量,提取1至4个颗粒可能是必需的。2 DNA颗粒可能并不总是可见。乙醇洗涤通常会显示出更长的3个离心机,如果白色颗粒保持松动,以促进收集干净的上清液。QC

与长期水族馆设施中的热带八放珊瑚相关的四种新型 Endozioicomonas 菌株的基因组序列
我们报告了从葡萄牙里斯本海洋馆 19 立方米热带展览水族馆中保存的两个 Litophy ton sp. 标本中分离出的四种 Endozoicomonas 菌株的基因组。如前所述 (2) 回收宿主衍生的微生物细胞悬浮液。将一克珊瑚组织在 9 mL 无菌 Ca 2+ - 和 Mg 2+ - 人工海水中均质化 (2)。将匀浆连续稀释,分别接种在 1:2 稀释的海洋琼脂和 1:10 稀释的 R2A 培养基上,并在 21°C 下孵育 4 周。使用 Wizard 基因组 DNA 纯化试剂盒 (Promega, USA) 从 1:2 海洋肉汤中新鲜生长的培养物中提取单个菌落的基因组 DNA。使用通用引物 (F27 和 R1492) 从基因组 DNA 中扩增 16S rRNA 基因,通过 Sanger 测序来确认纯度。使用 SILVA 比对、分类和树服务 (v1.2.12) 和数据库 (v138.1) 进行分类分配。使用 PacBio 测序技术 (5),相同的基因组 DNA 样本在 DOE 联合基因组研究所 (JGI) 进行基因组测序。对于每个样本,将基因组 DNA 剪切至 6-10 kb,使用 SMRTbell Express Template Prep Kit 3.0 进行处理,并用 SMRTbell 清理珠 (PacBio) 进行纯化。使用条形码扩增寡核苷酸 (IDT) 和 SMRTbell gDNA 样本扩增试剂盒 (PacBio) 富集纯化产物。构建了 10 kb PacBio SMRTbell 文库,并使用 HiFi 化学在 PacBio Revio 系统上进行测序。使用 BBTools v.38.86 ( http://bbtools.jgi.doe.gov ) 根据 JGI 标准操作规范 (SOP) 协议 1061 对原始读段进行质量过滤。使用 Flye v2.8.3 (6) 组装过滤后的 >5 kb 读段。生物体和项目元数据存放在 Genomes OnLine 数据库中 (7)。使用 NCBI 原核基因组注释流程 (PGAP v.6.7) (8) 和 DOE-JGI 微生物基因组注释流程 (MGAP v.4) (9) 对重叠群进行注释,并与集成微生物基因组和微生物组系统 v7 (IMG/M) 相结合进行比较分析 (10)。使用 CheckM 评估基因组完整性和污染

与长期水族馆设施中的热带八放珊瑚相关的四种新型 Endozioicomonas 菌株的基因组序列
我们报告了从葡萄牙里斯本海洋馆 19 立方米热带展览水族馆中保存的两个 Litophy ton sp. 标本中分离出的四种 Endozoicomonas 菌株的基因组。如前所述 (2) 回收宿主衍生的微生物细胞悬浮液。将一克珊瑚组织在 9 mL 无菌 Ca 2+ - 和 Mg 2+ - 人工海水中均质化 (2)。将匀浆连续稀释,分别接种在 1:2 稀释的海洋琼脂和 1:10 稀释的 R2A 培养基上,并在 21°C 下孵育 4 周。使用 Wizard 基因组 DNA 纯化试剂盒 (Promega, USA) 从 1:2 海洋肉汤中新鲜生长的培养物中提取单个菌落的基因组 DNA。使用通用引物 (F27 和 R1492) 从基因组 DNA 中扩增 16S rRNA 基因,通过 Sanger 测序来确认纯度。使用 SILVA 比对、分类和树服务 (v1.2.12) 和数据库 (v138.1) 进行分类分配。使用 PacBio 测序技术 (5),相同的基因组 DNA 样本在 DOE 联合基因组研究所 (JGI) 进行基因组测序。对于每个样本,将基因组 DNA 剪切至 6-10 kb,使用 SMRTbell Express Template Prep Kit 3.0 进行处理,并用 SMRTbell 清理珠 (PacBio) 进行纯化。使用条形码扩增寡核苷酸 (IDT) 和 SMRTbell gDNA 样本扩增试剂盒 (PacBio) 富集纯化产物。构建了 10 kb PacBio SMRTbell 文库,并使用 HiFi 化学在 PacBio Revio 系统上进行测序。使用 BBTools v.38.86 ( http://bbtools.jgi.doe.gov ) 根据 JGI 标准操作规范 (SOP) 协议 1061 对原始读段进行质量过滤。使用 Flye v2.8.3 (6) 组装过滤后的 >5 kb 读段。生物体和项目元数据存放在 Genomes OnLine 数据库中 (7)。使用 NCBI 原核基因组注释流程 (PGAP v.6.7) (8) 和 DOE-JGI 微生物基因组注释流程 (MGAP v.4) (9) 对重叠群进行注释,并与集成微生物基因组和微生物组系统 v7 (IMG/M) 相结合进行比较分析 (10)。使用 CheckM 评估基因组完整性和污染

无标记代谢成像增强嵌合抗原受体T细胞治疗的疗效
标题:无标记代谢成像增强嵌合抗原 1 受体 T 细胞治疗的疗效 2 3 作者: Dan L. Pham 1,2†、Daniel Cappabianca 1,3†、Matthew H. Forsberg 4、Cole Weaver 1,2、4 Katherine P. Mueller 5、Anna Tommasi 1,3、Jolanta Vidugiriene 6、Anthony Lauer 6、Kayla Sylvester 6、5 Madison Bugel 1,3、Christian M. Capitini 4,7、Krishanu Saha 1,3*、Melissa C. Skala 1,2* 6 7 附属机构: 8 1 威斯康星大学麦迪逊分校生物医学工程系;美国威斯康星州麦迪逊 9。 10 2 莫格里奇研究所;美国威斯康星州麦迪逊。 11 3 威斯康星大学麦迪逊分校威斯康星发现研究所;美国威斯康星州麦迪逊 12 4 威斯康星大学医学与公共卫生学院儿科系;13 美国威斯康星州麦迪逊。 14 5 宾夕法尼亚大学佩雷尔曼医学院肿瘤学部儿科系;15 美国宾夕法尼亚州费城。 16 6 Promega 公司;16 威斯康星州菲奇堡。 17 7 威斯康星大学麦迪逊分校威斯康星大学卡博内癌症中心;17 美国威斯康星州麦迪逊。 18 20 † 这些作者对本文贡献相同 21 * 通讯作者:ksaha@wisc.edu ,mcskala@wisc.edu 22 23 摘要:24 25 嵌合抗原受体 (CAR) T 细胞疗法治疗实体瘤不仅因为免疫抑制肿瘤微环境具有挑战性,还因为其制造过程复杂且难以监控。制造直接影响 CAR T 细胞的产量、表型和代谢,这些与体内效力和持久性相关。特别是,尽管代谢适应性是一项关键的质量属性,但 T 细胞代谢需求在整个制造过程中如何变化仍未得到探索。在这里,我们使用光学代谢成像 (OMI) 解决了这一限制,这是一种基于自发荧光代谢辅酶 NAD(P)H 和 FAD 评估单细胞代谢的非侵入性、无标记方法。使用 OMI,我们确定了培养基组成相对于抗体刺激和/或细胞因子的选择对抗 GD2 CAR T 细胞代谢、活化强度和动力学以及表型的主要影响。我们证明 OMI 参数可以指示病毒转导和基于电穿孔的 CRISPR/Cas9 的细胞周期阶段和最佳基因转移条件。值得注意的是,在 37 无病毒 CRISPR 编辑的抗 GD2 CAR T 细胞模型中,OMI 测量可以准确 38 预测氧化代谢表型,从而产生更高的体内抗神经母细胞瘤效力。我们的数据支持 OMI 作为一种强大、灵敏的分析工具的潜力,可以识别 40 最佳制造条件并在整个制造过程中监测细胞代谢,从而提高 41 CAR T 细胞产量和代谢适应性。42 43