XiaoMi-AI文件搜索系统
World File Search SystemQuant

乌克兰:2022 年 7 月 5 日至 6 日期间的情况
东部战线: • 乌克兰军队夺回了卢甘斯克州的一个村庄。俄罗斯军队继续向斯拉维扬斯克和克拉马托尔斯克城镇发动进攻。北顿涅茨克和利西昌斯克等城镇的抵抗为乌克兰人开发地形提供了时间。
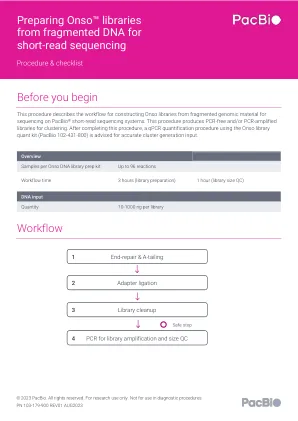
从碎片 DNA 中制备 Onso 文库以用于短...
对于每个样本,从步骤 4b.15 中取出 2 µL PCR 扩增文库进行定量分析:接下来必须按照“Onso TM 文库的 qPCR 定量分析”程序使用 Onso Library 定量试剂盒 (PacBio 102-431-800) 通过 qPCR 准确评估文库数量。这将确保在簇生成期间能够实现最佳簇密度。注意:步骤 4b.17 可以与步骤 4b.16 同时进行。
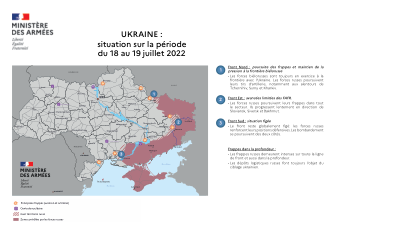
乌克兰:2022 年 7 月 18 日至 19 日期间的情况
东部战线: • 乌克兰军队夺回了卢甘斯克州的一个村庄。俄罗斯军队继续向斯拉维扬斯克和克拉马托尔斯克城镇发动进攻。北顿涅茨克和利西昌斯克等城镇的抵抗为乌克兰人开发地形提供了时间。
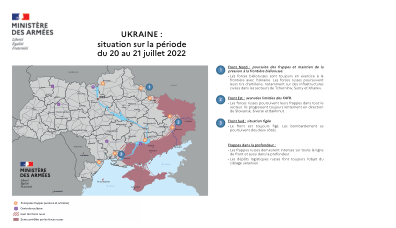
乌克兰:2022 年 7 月 20 日至 21 日期间的情况
东部战线: • 乌克兰军队夺回了卢甘斯克州的一个村庄。俄罗斯军队继续向斯拉维扬斯克和克拉马托尔斯克城镇发动进攻。北顿涅茨克和利西昌斯克等城镇的抵抗为乌克兰人开发地形提供了时间。
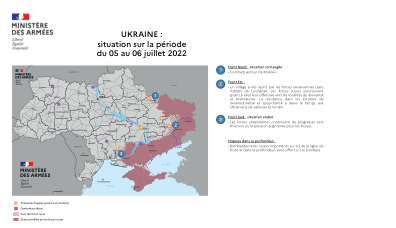
乌克兰:2022 年 7 月 5 日至 6 日期间的情况
东部战线: • 乌克兰军队夺回了卢甘斯克州的一个村庄。俄罗斯军队继续向斯拉维扬斯克和克拉马托尔斯克城镇发动进攻。北顿涅茨克和利西昌斯克等城镇的抵抗为乌克兰人开发地形提供了时间。
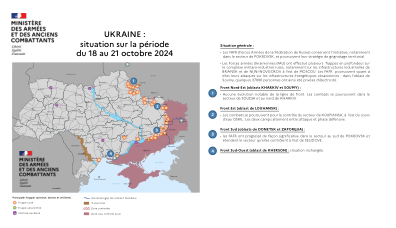
乌克兰:2024年10月18日至21日期间的局势
• 乌克兰武装部队(FAU)对俄罗斯军工联合体进行了数次纵深打击,特别是对莫斯科东部布良斯克和下诺夫哥罗夫的工业基础设施。FAFR 正在继续攻击乌克兰的能源基础设施:在苏梅州,约 37,000 人被剥夺了电力。
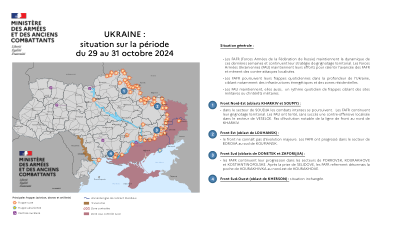
乌克兰:2024 年 10 月 29 日至 31 日期间的情况
• 乌克兰武装部队 (AFU) 对俄罗斯军工综合体进行了多次深度打击,包括莫斯科以东的布良斯克和下诺夫哥罗夫的工业基础设施。 FAFR 继续对乌克兰能源基础设施发起攻击:在苏梅州,约有 37,000 人断电。

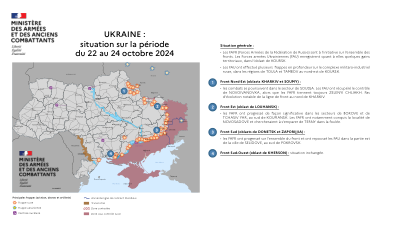
乌克兰:2024 年 10 月 22 日至 24 日期间的情况
• 乌克兰武装部队 (AFU) 对俄罗斯军工综合体进行了多次深度打击,包括莫斯科以东的布良斯克和下诺夫哥罗夫的工业基础设施。 FAFR 继续对乌克兰能源基础设施发起攻击:在苏梅州,约有 37,000 人断电。
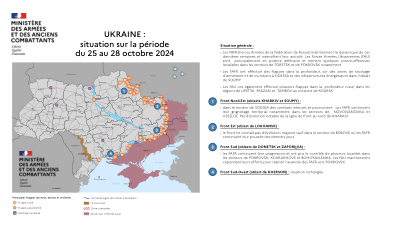
乌克兰:2024 年 10 月 25 日至 28 日期间的情况
• 乌克兰武装部队 (AFU) 对俄罗斯军工综合体进行了多次深度打击,包括莫斯科以东的布良斯克和下诺夫哥罗夫的工业基础设施。 FAFR 继续对乌克兰能源基础设施发起攻击:在苏梅州,约有 37,000 人断电。