XiaoMi-AI文件搜索系统
World File Search SystemQwen
阿里巴巴启动了高级AI模型,以竞争GPT-4
QWEN2.5-MAX现在可以通过阿里巴巴云服务向开发人员使用,并且可以通过公司的对话AI平台Qwen Chat访问。该系统提供了与OpenAI的API格式的兼容性,有可能简化已经使用类似AI服务的组织的采用。

外周血细胞图像分析的语言模型
摘要本文研究了视觉模型(VLM)在外周血细胞自动形态学分析中的应用。虽然手动显微镜分析仍然是血液学诊断的金标准,但它既耗时又可能会受到观察者间的变化。这项工作旨在开发和评估能够从微观图像中对血细胞进行准确的形态描述的微调VLM。我们的方法论包括三个主要阶段:首先,我们创建了一个合成数据集,该数据集由10,000个外周血细胞图像与专家制作的形态描述配对。第二,我们在三个开源VLMS上使用低级适应性(LORA)和量化Lora(Qlora)进行了微调方法:Llama 3.2,Qwen和Smovlm。最后,我们开发了一个基于Web的界面,用于实用部署。的结果表明,在预先调整后所有模型的所有模型中都有显着改善,QWEN的性能最高(BLEU:0.22,Rouge-1:0.55,Bertscore F1:0.89)。为了确保可访问性并实现正在进行的评估,该模型已被部署为网络空间的Web应用程序,使研究社区可自由使用。我们得出的结论是,微调的VLM可以有效地分析外周血细胞形态,从而为血液学分析提供了标准化的潜力。这项工作建立了一个框架,可以将视觉模型改编为专业的医疗成像任务,这对改善临床环境中的诊断工作流程的影响。完整的实现可在GitHub
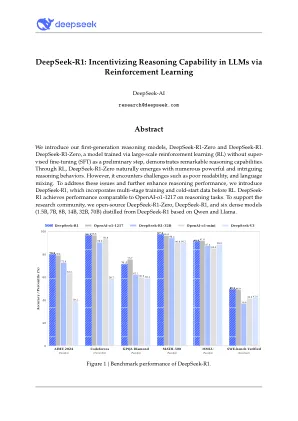
DeepSeek-R1:通过增强学习激励LLM中的推理能力
我们介绍了第一代推理模型,即DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero,一种通过大规模增强学习(RL)训练的模型,没有超级微调(SFT)作为初步的步骤,表现出显着的推理能力。通过RL,DeepSeek-R1-Zero自然出现,具有许多强大而有趣的推理行为。但是,它遇到了挑战,例如不良的可读性和语言混合。为了解决这些问题并进一步提高了推理性能,我们引入了DeepSeek-R1,该问题在RL之前结合了多阶段培训和冷启动数据。DeepSeek-R1在推理任务上实现与OpenAI-O1-1217相当的性能。为了支持研究社区,我们开放源DeepSeek-R1-Zero,DeepSeek-R1和六种密集的型号(1.5b,7b,8b,8b,14b,32b,32b,70b),根据Qwen和Llama蒸馏出了DeepSeek-R1。
![arXiv:2412.15115v2 [cs.CL] 2025 年 1 月 3 日](/simg/4\45710a4eac78ed92881e3cc343e9657224c66237.webp)
arXiv:2412.15115v2 [cs.CL] 2025 年 1 月 3 日
在本报告中,我们介绍了 Qwen2.5,这是一系列全面的大型语言模型 (LLM),旨在满足多样化的需求。与之前的迭代相比,Qwen 2.5 在预训练和后训练阶段都有了显著的提升。在预训练方面,我们将高质量的预训练数据集从之前的 7 万亿个 token 扩展到 18 万亿个 token,为常识、专家知识和推理能力提供了坚实的基础。在后训练方面,我们实现了超过 100 万个样本的复杂监督微调,以及多阶段强化学习,包括离线学习 DPO 和在线学习 GRPO。后训练技术显著增强了人类偏好,并显著改善了长文本生成、结构化数据分析和指令跟随。
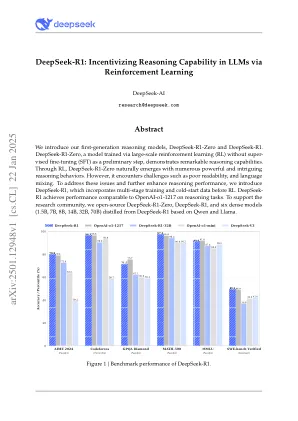
DeepSeek-R1:通过增强学习激励LLM中的推理能力
我们介绍了第一代推理模型,即DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero,一种通过大规模增强学习(RL)训练的模型,没有超级微调(SFT)作为初步的步骤,表现出显着的推理能力。通过RL,DeepSeek-R1-Zero自然出现,具有许多强大而有趣的推理行为。但是,它遇到了挑战,例如不良的可读性和语言混合。为了解决这些问题并进一步提高了推理性能,我们引入了DeepSeek-R1,该问题在RL之前结合了多阶段培训和冷启动数据。DeepSeek-R1在推理任务上实现与OpenAI-O1-1217相当的性能。为了支持研究社区,我们开放源DeepSeek-R1-Zero,DeepSeek-R1和六种密集的型号(1.5b,7b,8b,8b,14b,32b,32b,70b),根据Qwen和Llama蒸馏出了DeepSeek-R1。
![arxiv:2502.15224v1 [cs.lg] 2025年2月21日](/simg/c\c4e43d6e87f57c621b5360bfb0c134c00cdfa1cf.webp)
arxiv:2502.15224v1 [cs.lg] 2025年2月21日
鉴于大语言模型(LLMS)的出色表现,出现了一个重要的问题:LLM可以进行类似人类的科学研究并发现新知识,并充当AI科学家吗?科学分解是一个迭代过程,需要有效的知识更新和编码。它涉及理解环境,识别新的假设以及对行动的推理;但是,没有专门为LLM代理的科学发现设计的标准化基准。响应这些限制的局面,我们引入了一个新颖的基准,即自动基准,该基准包括必要的方面,以评估自然科学和社会科学中的科学发现的LLM。我们的基准测试基于因果图剖面的原理。它挑战模型以发现隐藏的结构并做出最佳决策,其中包括生成有效的理由。通过与甲骨文进行交互性结合,这些模型通过战略干预措施迭代地完善了他们对不认识的相互作用,化学和社会传播的理解。我们评估了最新的LLM,包括GPT-4,Gemini,Qwen,Claude和Llama,并且随着问题的复杂性的增加而观察到显着的性能下降,这表明机器和人类智慧之间的重要差距表明,未来LLMS的未来发展需要考虑。

生成代理社会可以模拟人类行为并为公共卫生政策提供信息?疫苗犹豫的案例研究
我们可以模拟一个用发电的代理人模拟人类行为的沙盒社会,从而减少对实际人类试验评估公共政策的过度依赖?在这项工作中,我们研究了使用疫苗犹豫,将与健康相关的决策模拟的可行性定义为尽管有疫苗接种服务的可用性,但作为案例研究,被定义为延迟接受或拒绝疫苗的可行性(Macdonald,2015年)。为此,我们引入了V ac S IM 1框架,其中100种由大型语言模型(LLMS)提供动力的生成代理。v ac s im模拟了通过以下步骤模拟VACINE政策结果:1)根据人口普查数据实例化具有人口统计信息的代理商; 2)通过社交网络连接代理商,并建模疫苗态度,这是社会动态和与疾病相关的信息的函数; 3)设计和评估各种旨在减轻疫苗犹豫的公共卫生干预措施。为了与现实世界的结果保持一致,我们还引入了模拟热身和态度调节以调整药物的态度。我们进行了一系列评估,以评估各种LLM模拟的可靠性。实验表明,诸如Llama和Qwen之类的模型可以模仿人类行为的各个方面,但也突出了现实世界的一致性挑战,例如与人口统计学特征的不一致的响应。对LLM驱动的模拟的这种早期探索并不意味着作为确定的政策指导;相反,它是采取行动检查政策制定的社会模拟的呼吁。

llms用于药物相互作用预测
现代治疗方案中药物组合的增加需要可靠的方法来预测药物相互作用(DDIS)。虽然大型语言模型(LLMS)已重新提到了各个领域,但它们在药物研究中的潜力,尤其是在DDI预测中,仍然在很大程度上没有探索。这项研究通过唯一处理分子结构(微笑),靶生物和基因相互作用数据作为最新药品库数据集的原始文本输入来彻底研究LLMS在预测DDI方面的能力。我们评估了18种不同的LLM,包括专有模型(GPT-4,Claude,Gemini)和开源变体(从1.5B到72B参数),首先评估其在DDI预测中的零击功能。然后我们微调选定的模型(GPT-4,PHI-3.5 2.7b,QWEN-2.5 3B,GEMMA-2 9B和DEEPSEEK R1蒸馏QWEN 1.5B),以优化其性能。我们的全面评估框架包括对13个外部DDI数据集进行验证,并与传统方法(例如L2登记的逻辑回归)进行了比较。微型LLMS表现出卓越的性能,PHI-3.5 2.7b在DDI预测中达到0.978的灵敏度,在平衡数据集中的准确性为0.919(50%正,50%负案例)。此结果代表了用于DDI预测的零射击预测和最新的机器学习方法的改进。我们的分析表明,LLM可以有效地捕获复杂的分子相互作用模式和药物对以共同基因为目标的情况,从而使其成为药物研究和临床环境中实际应用的宝贵工具。