XiaoMi-AI文件搜索系统
World File Search SystemRCNN

北欧车辆数据集 (NVD) - CVF 开放获取
摘要 无人机图像中的车辆检测和识别是一个复杂的问题,已用于不同的安全目的。这些图像的主要挑战是从斜角捕获的,并带来了一些挑战,例如非均匀照明效果、退化、模糊、遮挡、能见度丧失等。此外,天气条件在引起安全问题方面起着至关重要的作用,并为收集的数据增加了另一个高水平的挑战。在过去的几十年里,人们采用了各种技术来检测和跟踪不同天气条件下的车辆。然而,由于缺乏可用数据,在大雪中检测车辆仍处于早期阶段。此外,还没有使用无人机 (UAV) 拍摄的真实图像在雪天检测车辆的研究。本研究旨在通过向科学界提供北欧地区不同环境和各种积雪条件下无人机拍摄的车辆数据来解决这一空白。数据涵盖不同的恶劣天气条件,如阴天降雪、低光照和低对比度条件、积雪不均、高亮度、阳光、新雪,以及温度远低于-0摄氏度。该研究还评估了常用物体检测方法(如 YOLOv8s、YOLOv5s 和 Faster RCNN)的性能。此外,还探索了数据增强技术,以及那些增强检测器性能的技术

端到端对象检测的内在解释性
抽象的深度学习模型正在自动执行许多日常任务,表明将来,即使是高风险的任务也将是自动化的,例如医疗保健和自动化驱动区。但是,由于这种深度学习模型的复杂性,了解其推理是一项挑战。此外,设计的深度学习模型的黑匣子性质可能会破坏公众对关键领域的信心。当前对本质上可解释的模型的努力仅着眼于分类任务,而在对象检测中留下了差距。因此,本文提出了一个深度学习模型,该模型可用于对象检测任务。这种模型所选的设计是众所周知的快速RCNN模型与ProtopNet模型的组合。对于可解释的AI实验,所选的性能度量是Protopnet模型的相似性评分。我们的实验表明,这种组合导致了一个深度学习模型,该模型能够以相似性得分来解释其分类,并使用视觉上的“单词袋”(称为原型)在训练过程中学习。此外,采用这种可解释的方法似乎并没有阻碍提出的模型的性能,该模型在Kitti数据集中获得了69%的地图,而GrazpedWri-DX数据集则获得了66%的地图。此外,我们的解释对相似性得分的可靠性很高。
![arxiv:2311.14552v3 [CS.CV] 2024年10月8日](/simg/0\01bece2b02a718559491f0f4925c190c0dd412dd.webp)
arxiv:2311.14552v3 [CS.CV] 2024年10月8日
摘要。复制天生的人类根据任何粒度的自由形式文本检测所有对象仍然是大型视觉语言模型(LVLM)的强大挑战。当前的LVLM主要限制以定位单个预先存在的对象。此限制导致模型设计的妥协,因此需要进行视觉专家模型或定制的头部结构。除了这些约束之外,我们的研究还发现了LVLMS的基本观念能力,从而使它们能够准确地识别并找到感兴趣的对象。基于这种见解,我们引入了一种新颖的语言,促使本地化数据集充分释放了LVLM在细颗粒对象感知和精确的位置意识中的能力。更重要的是,我们提出了纯粹基于LVLM的基线Griffon,它不会引入任何特殊的代币,专家模型或其他分解模块。它通过在各种与本地化相关的方案中统一数据格式,通过统一数据格式保持与人口LVLM的一致结构,并通过设计良好的管道进行了端到端训练。全面的实验表明,格里芬不仅在细粒度的reccoco系列和flickr30k实体上实现了最新的性能,而且还可以在检测基准MSCOCO上更快地接近专家模型的能力。数据,代码和模型在https://github.com/jefferyzhan/griffon上发布。

AIRADF:人工智能启用
医学图像分析在医疗保健中起着至关重要的作用,特别是在计算机视觉应用中。人工智能 (AI) 为解决医疗保健行业的各种问题做出了巨大贡献,包括疾病诊断和分类。类风湿性关节炎 (RA) 是一种导致严重健康问题的自身免疫性疾病。目前基于学习的 RA 诊断方法需要改进流水线和优化。在本文中,我们提出了一个基于深度学习的框架,称为人工智能 (AI) RA 诊断框架 (AIRADF)。该框架包括用于预处理和训练感兴趣区域 (ROI) 的功能,用于自动 RA 检测和分类。RA 检测过程利用称为 Faster RCNN 的深度学习模型,而 RA 分类由增强的 UNet 模型执行。我们引入了一种称为基于学习的类风湿性关节炎检测 (LbRAD) 的算法。我们使用 X 射线图像进行的经验研究表明,所提出的算法在 RA 检测和分类方面优于许多现有的深度学习模型,分别达到 92.81% 和 94.58% 的最高准确率。此外,我们的框架除了 RA 检测之外还能够进行多类分类,从而形成临床决策支持系统 (CDSS),可帮助医疗专业人员进行 RA 预后。关键词 – 类风湿性关节炎、深度学习、人工智能、图像处理、类风湿

MPAR-RCNN:具有属性识别的多人检测的多任务网络
多标签属性识别是计算机视觉中的一项关键任务,应用程序范围在不同的领域。这个问题通常涉及检测具有多个属性的对象,需要具有高级差异和精细的特征提取的复杂模型。对象检测和属性识别的集成通常依赖于诸如双阶段网络之类的方法,其中准确的预测取决于高级特征提取技术,例如感兴趣的区域(ROI)池。为了满足这些要求,在统一框架中既可以实现可靠的检测和属性进行分类,这是必不可少的。这项研究介绍了一个创新的MTL框架,旨在将多人属性识别(MPAR)纳入单模型体系结构中。命名为MPAR-RCNN,该框架通过空间意识到的,共享的骨干,促进效果和准确的多标签预测来符合对象检测和属性识别任务。与传统的基于快速区域的卷积神经网络(R-CNN)不同,该网络(R-CNN)分别管理人的检测和归因于双阶段网络的分类,MPAR-RCNN体系结构在单个结构中优化了两个任务。在更宽的(用于事件识别的Web图像数据集)数据集上进行了验证,提出的模型展示了对当前最新ART(SOTA)体系结构的改进,展示了其在推进多标签属性识别方面的潜力。
北欧车辆数据集 (NVD) - CVF 开放获取
摘要 无人机图像中的车辆检测和识别是一个复杂的问题,已用于不同的安全目的。这些图像的主要挑战是从斜角捕获的,并带来了一些挑战,例如不均匀的照明效果、退化、模糊、遮挡、能见度丧失等。此外,天气条件在引起安全问题方面起着至关重要的作用,并为收集的数据增加了另一个高水平的挑战。在过去的几十年里,人们采用了各种技术来检测和跟踪不同天气条件下的车辆。然而,由于缺乏可用数据,在大雪中检测车辆仍处于早期阶段。此外,还没有使用无人机 (UAV) 拍摄的真实图像在雪天检测车辆的研究。本研究旨在通过向科学界提供北欧地区不同环境和不同积雪条件下无人机拍摄的车辆数据来解决这一空白。数据涵盖不同的恶劣天气条件,如阴天降雪、低光照和低对比度条件、积雪不均、高亮度、阳光、新雪,以及温度远低于-0摄氏度。该研究还评估了常用物体检测方法(如 YOLOv8s、YOLOv5s 和 Faster RCNN)的性能。此外,还探索了数据增强技术,并提出了在此类场景中增强检测器性能的技术。代码和数据集将在 https://nvd.ltu-ai.dev 上提供

bin选择的几个透明实例细分
摘要在本文中,我们考虑了从机器人箱拾取设置中从RGB或灰度相机图像中分割多个实例的问题。用于解决此任务的先前方法通常是在Mask-RCNN框架上构建的,但是它们需要大量注释的数据集进行填充。取而代之的是,我们在几个拍摄设置中考虑任务,并在trinseg中考虑了基于mask-rcnn的透明对象的数据效率和健壮的实例分割方法。我们在trinseg中的关键创新是双重的:i)一种被称为transmixup的新颖方法,用于使用合成透明的对象实例生成新的训练图像,该图像是通过空间转换带注释的示例创建的; ii)一种评分理想对象模板的预测段和旋转之间一致性的方法。在我们的新评分方法中,空间转换是由辅助神经网络产生的,然后将得分用于填充不一致的实例预测。为了证明我们方法的效果,我们介绍了一个新的几种数据集的实验,该数据集由七个类别的非偏见(透明和半透明)对象组成,每个类别的大小,形状和透明度的透明度变化。我们的结果表明,Trinseg实现了最先进的性能,在MIOU中提高了14%以上的细化面膜RCNN,同时需要很少的带注释的培训样本。

图像字幕生成方法
快速浏览的图像。尽管在计算机视觉中已经进行了巨大的发展,但诸如识别对象,动作分类,图像分类,属性分类和场景识别之类的任务是可能的,但是让计算机描述以类似人类句子的形式向其转发到它的图像是一个相对较新的任务。2。文献回顾了Andrej Karpathy等人的有影响力论文之一。在图像字幕中将任务划分为两个步骤:将句子段映射到图像中的视觉区域,然后使用这些通信来生成新的描述(Karpathy and Fei-Fei 2015)。作者使用区域卷积神经网络(RCNN)表示图像作为一组H维矢量,每个向量代表图像中的对象,基于200个Imagenet类检测到。作者在同一h维空间中的双向复发神经网络(BRNN)代表句子。每个句子是一组H维向量,代表片段或单词。BRNN的使用丰富了此表示,因为它学习了句子中每个单词上下文的知识。作者发现,有了这样的表示,单词的最终表示与与同一概念相关的视觉区域的表示密切一致。他们在单词和视觉区域的表示形式上定义了对齐得分,并在马尔可夫随机字段的帮助下,将各种单词与生成文本片段的同一区域对齐。借助图像区域和文本片段之间的这些对应关系,作者训练了另一个为新看不见的图像生成文本说明的模型(Karpathy and Fei-Fei 2015)。
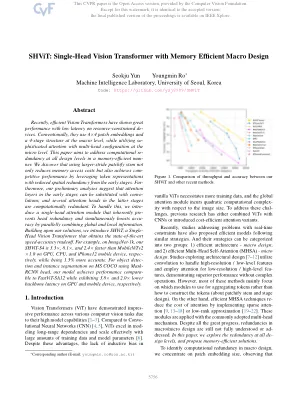
shvit:带有内存有效宏设计的单头视觉变压器
最近,有效的视觉变压器表现出出色的性能,并且在资源受限的范围内延迟较低。通常,他们在宏观水平上使用4×4贴片嵌入式和4阶段结构,同时在微观级别利用多头配置的同时注意力。本文旨在解决记忆效率高的人中所有设计级别的计算重复。我们发现,使用较大的修补茎不仅降低了内存访问成本,而且还通过利用令牌表示,从早期阶段降低了空间冗余,从而实现了态度性能。fur-hoverore,我们的初步分析表明,在早期阶段的注意力层可以用会议代替,并且后期阶段的几个注意力头在计算上是多余的。为了处理这一点,我们介绍了一个单头注意模块,该模块固有地预先预先冗余,并同时通过相结合的全局和本地信息来提高准确性。在解决方案的基础上,我们引入了Shvit,这是一种单头视觉变压器,获得了最先进的速度准确性权衡。例如,在ImagEnet-1k上,我们的SHVIT-S4在GPU,CPU和iPhone12移动设备上比MobileVitV2×1.0快3.3×,8.1×和2.4倍,而同时更准确。用于使用Mask-RCNN头对MS Coco进行的对象检测和实例分割,我们的模型分别在GPU和移动设备上表现出3.8×和2.0×下骨架潜伏期时,可以与FastVit-SA12进行比较。

人工智能、3D 文档和岩画
摘要 岩画,最好被描述为岩石雕刻,是通过去除岩石表面的部分来产生负浮雕而产生的。这一传统在北欧青铜时代(公元前 1700 年 - 公元前 550 年)在斯堪的纳维亚南部尤为盛行,当时有超过 20,000 艘船只和成千上万的人、动物、马车等。这些生动且极具吸引力的材料提供了定量数据,对于了解青铜时代的社会结构和意识形态具有很高的潜力。提供技术上最好的记录以及自动识别和分类图像的能力将有助于充分利用斯堪的纳维亚南部和其他地方的岩画的研究潜力。因此,我们尝试使用更快的基于区域的卷积神经网络 (Faster-RCNN) 来训练一个模型,该模型基于一种新方法生成的数据来定位和分类图像对象,以改善 3D 记录内容的可视化。新创建的 3D 岩画记录层提供了目前可用的最佳数据,并且与旧方法相比减少了刻写偏差。我们根据输入图像训练了多个模型,这些输入图像上标注了使用不同参数生成的边界框,以找到最佳解决方案。数据包括 408 次岩画遗址扫描中的 4305 张单独图像。为了增强模型并丰富训练数据,我们使用了数据增强和迁移学习。成功的模型在船和圆圈以及人物和轮子上表现异常出色。这项工作是一项跨学科的事业,引发了对考古学、数字人文和人工智能的重要思考。经过训练的模型所代表的思考和成功为未来的岩画研究开辟了新途径。