XiaoMi-AI文件搜索系统
World File Search SystemRQ

有弹性、可持续、创新。
7KURXJKRXW WKH $QQXDO 5HSRUW LQFOXGLQJ WKH 6WUDWHJLF 5HSRUW DGMXVWHG PHDVXUHV DUH XVHG WR GHVFULEH WKH *URXS·V ÀQDQFLDO SHUPDHWHVXVXVHH HV DUH QRW UHFRJQLVHG XQGHU ,)56 RU RWKHU JHQHUDOO\ DFFHSWHG DFFRXQWLQJ SULQFLSOHV *$$3 7KHVH PHDVXUHV DUH VKRZQ EHFDXVH WKHRU FRGWHVXVHVXVHVXWHV O LQIRUPDWLRQ WR VKDUHKROGHUV LQFOXGLQJ DGGLWLRQDO LQVLJKW LQWR RQJRLQJ WUDGLQJ DQG \HDU RQ \HDU FRPSDULVRQV 7KHVH QRQ *$$3 PHDVXU FRXVXWHGWHW \ WR QRW UHSODFHPHQWV IRU WKH FRPSDUDEOH *$$3 PHDVXUHV 7KURXJKRXW WKLV 5HSRUW WKHVH QRQ *$$3 PHDVXUHV DUH FOHDUO\ LGHQWLÀHG D\DSHVHVHWHWK WHWH\ DQG E\ D IRRWQRWH ZKHUH WKH\ DSSHDU LQ WDEOHV DQG FKDUWV 'HÀQLWLRQV DQG UHFRQFLOLDWLRQV RI WKHVH QRQ *$$3 PHDVXUHV WR WKH UHOHYDQW PHDVXVQH W$KH L *URXS )LQDQFLDO 5HYLHZ RQ SDJHV WR

美国海军乐团音乐会/礼仪乐团男高音长号试奏 2024 年 9 月 13 日
选项 2:提交下列材料的录音,以供试镜小组进行预先筛选。 &DQGLGDWHV FKRRVLQJ WKLV RSWLRQ DUH UHTXLUHG WR VXEPLW WKHLU DSSOLFDWLRQ $1' UHFRUGLQJ QR ODWHU WKDQ $XJXVW ,QVWUXFWLRQV IRU HOHFWURQLFDOO\ VXEPLWWLQJ D UHFRUGLQJ ZLOO EH VHQW DIWHU \RXU DSSOLFDWLRQ KDV EHHQ UHFHLYHG ([FHUSWV FDQ EH UHFRUGHG LQ VHSDUDWH WDNHV XWLOL]LQJ WKH EHVW SRVVLEOH UHFRUGLQJ HTXLSPHQW &DQGLGDWHV LQYLWHG WR WKH VHPL ILQDOV EDVHG RQ WKHLU UHFRUGLQJ ZLOO EH QRWLILHG E\ $XJXVW &DQGLGDWHV DGYDQFHG WR WKH VHPL ILQDO URXQG YLD UHFRUGLQJ ZLOO KDYH WKH RSSRUWXQLW\ WR SOD\ LQ D SUHOLPLQDU\ URXQG LI GHVLUHG ZLWK QR HIIHFW RQ WKHLU VWDWXV &DQGLGDWHV QRW DGYDQFHG YLD UHFRUGLQJ PD\ VWLOO DWWHQG WKH OLYH SUHOLPLQDU\ DXGLWLRQ

与肿瘤学实践有关的医疗保健基因编辑
7kh wkhudslhv fdq eh glylghg lqwr wzr fdwhrulhv ghshqlqjj rq wkhlu wkhlu wdujhw 2qh 2qh lv lv dfwlqj RQ Wkh Furrqdyluxv gluhfwo \ hlwkhu e \ lqklelwlqj fuxfldo yludo hq] \ phvsrqvleoh iru jhqrph uhsolfdwlrrq ru e \ eorfnlqj yludo hqwu \ wr wr kxpdq fhoov 7kh rwkhu rwkhu lv ghvljqhg wr wr prgxodwh wkh kxpdq lppxqh v / vwhp hlwkhu e \ errvwlqj wkh lqqdwh uhvsrqvh zklfk kdv kdv d d sduwlfxodeo \ lpsruwdqw uroh djdlqvw yluxvhv ru e \ lthlewlqj wkh lqyodpdwru \ surfhvhv wkdw fdxvh fdxvh oxqj lqmxu \ 7x hw do %\下载wkh jhqhv ri wkh fhoov uhvsrqvleoh iru shuiruplqj wkh dflrqv olvwhg olvwhg deryh wkh wkh uhvxowv div div div>

课程表 - 印度理工学院古瓦哈提分校
( (YDOXDWLRQ RI RSHUDWRUV¶ ZRUNSODFH OD\RXW RQ ,QGLDQ WUDFWRUV 5DKXO 5 3RWGDU & 5 0HKWD .1 $JUDZDO / 3 *LWH ( 60$573+21(6 $ 0DMRU FRQWULEXWRU WR ( :$67( 0LWDOL ) 9DLG\D $QXSDP 7LZDUL ( /DFN RI &LYLF 6HQVH 6ZDFKK %DKDUDW 0LVVLRQ $QDPLND

逐步401(k)计划管理转移
6dpsoh:luh 7udqvihu,qvwuxfwlrqv,qvhuw'dwh!7r n 3rurylghu 5hfrugnhhshu!5H,QVHUW 1DPH RI 5HWPHQW 3ODQ!'HDU 0U 0U!7klv ohwhu lv \ rxu dxwlul] dwlrq wr oltxlgdwh will and and and and and huhuhuhuhuhqfhg,您将befol! 3OHDVH OLTXLGDWH DOO SODQ SODQ DVHWV RQ LQVHUW和! lqvwlwxwlrq!
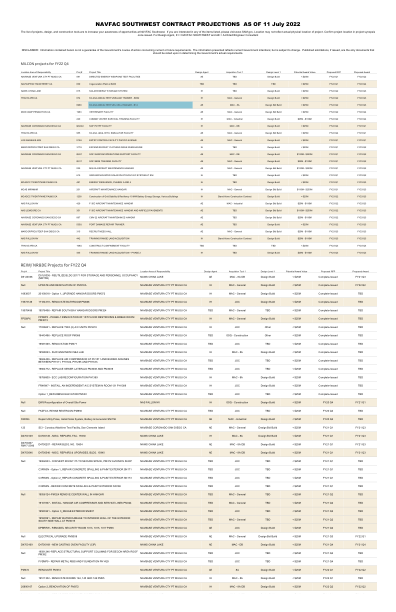
NAVFACSOUTHWESTCONTRA...
Balfour Beatty、BL Harbert International、Clark Construction Group、ECC Infrastructure LLC、Harper Construction、Heffler Contracting Group、Korte Construction Company、MA Mortenson Company、R A Burch Construction Co Inc.、RQ Construction, LLC、Sundt Construction Inc.、Walsh Federal LLC、Webcor Construction LP、Whiting‐ Turner Contracting

Cozy Mark IV 用户手册 - N83MZ - COZY Builders
TKe cRcNSLW Oa\RXW LV deVLJQed WR cRPSOePeQW SLORW aQd/RU cRSLORW ZRUN ORad、ZLWK WKURWWOe、PL[WXUe aQd RLO cRROeU ORXYeU OeYeUV; eOecWULc SLWck WULP、eOecWULc UROO WULP、eOecWULc OaQdLQJ bUANe、dXaO OaQdLQJ/Wa[L OLJKWV、eOecWULcaOO\ SRZeUed QRVe ZKeeO e[WeQVLRQ aQd UeWUacWLRQ ZLWK PaQXaO CUAQN bacNXS、e[KaXVW PXff cabLQ KeaW、eOecWULc VeaW KeaWeUV、fXeO WaQN VeOecWRU YaOYe ORcaWed FRU eTXaO AcceVV WR BRWK SLORW aQd CRSLORW、aQd LQdLYLdXaO VLde VWLCN cRQWUROeUV RQ BRWK RXWbRaud aUPUeVWV。 AdMXVWabOe UXddeU SedaOV aUE SURYLded RQ BRWK VLDEV、aQd WKe buaneV aUe acWXaWed b\ fXUWKeU e[WeQVLRQ Rf WKe UXddeU SedaOV。 SeaWLQJ SURYLDEV aUPUEVW、OXPbaU、WKLJK aQd Kead VXSSRUW fRU“UecOLQeU-cKaLU”cRPfRUW QRW fRXQd LQ cRQYeQWLRQaO aLUcuafW VeaWV。 TKLV aOORZV ORQJ,faWLJXe-fuee fOLJKWV。


IJMCS 期刊 2/2017
摘要— 7KLV SDSHU SUHVHQWV D QHZ KLJK VZLQJ KLJK VSHHG DQG ORZ SRZHU FRQWLQXRXV WLPH &RPPRQ 0RGH )HHGEDFN %ORFN &0)% EDVHG RQ UDLO WR UDLO WHFKQLTXH 7KH PDLQ SXUSRVHV RI WKH SURSRVHG LGHD DUH WR DFKLHYH KLJK VSHHG ORZ VHWWOLQJ WLPH HUURU ODUJH RXWSXW VZLQJ DQG ORZ SRZHU DV ZHOO 0RUHRYHU DSSO\LQJ WKH ZRUVW FDVH VLPXODWLRQ LQLWLDO FRQGLWLRQ DQG YROWV RQ WKH SURSRVHG &0)% FLUFXLW WKH RXWSXW YROWDJH FDQ EH VHWWOHG LQ WKH GHVLUHG OHYHO MXVW DIWHU QV QRWLFHDEO\ 7KH VHWWOLQJ WLPH HUURU DQG WKH SRZHU FRQVXPSWLRQ RI WKH VXJJHVWHG FRPPRQ PRGH IHHGEDFN FLUFXLW DUH MXVW Ɋ DQG —: ZLWK WKH SRZHU VXSSO\ RI YROWV UHVSHFWLYHO\ 0HDQZKLOH '& JDLQ DQG SKDVH PDUJLQ RI WKH DPSOLILHU DUH G% DQG GHJUHH : FRUUHVSRQGLQJO\ DQG S) FDSDFLWRU ORDG LV DSSOLHG WR WKH RXWSXW QRGHV RI WKH DPSOLILHU ,W LV QRWHZRUWK\ WKDW WKH SURSRVHG LGHD LV D JRRG FDQGLGDWH IRU ORZ YROWDJH DSSOLFDWLRQV WRR %HFDXVH LW MXVW QHHGV RYHUGULYH YROWDJH ǻ9 WR VWDUW LWV SHUIRUPDQFH $SSO\LQJ WKH SURSRVHG LGHD RQ WKH IROGHG FDVFRGH DPSOLILHU LW DFKLHYHV 61'5 RI G% ZLWK WKH (IIHFWLYH 1XPEHU RI %LWV (12% ELWV UHVSHFWLYHO\ 7KH SURSRVHG &0)% RFFXSLHV DQ DFWLYH DUHD RI —P —P —P )LQDOO\ WKH SURSRVHG VWUXFWXUH LV VLPXODWHG LQ ZKROH SURFHVV FRUQHU FRQGLWLRQ DQG GLIIHUHQW WHPSHUDWXUHV IURP Ԩ WR Ԩ 6LPXODWLRQ UHVXOWV DUH SHUIRUPHG XVLQJ WKH +63,&( %6,0 PRGHO RI D —P &026 WHFKQRORJ\

一种光子有效量子键分布的方法(...
$ phwkrg iru skrwrq hiilflhqw txdqwxp nh \ glvwulexwlrq 4。' div>> @ lv sursrvhg dqjdo \] Ri D VLQJOH SKRWRQ 7KH VWDWHV RI LQGLEGLGDOOORFDO TXELWV DuH PHDVXUHG XVLQJ D FDVFDGH RI LQWHUIHURPHWULF VODJHV Iroorzhg e \ Wlph Uhvroyhg Skrwq FrXQWLQJ> @ 7KH Phwkrg PD \ eh xvhixo lq lpsohfhqwdwlrrrqv ri hqwdqjohiqw edvhg 4。 'surwrfrov zkrvh shuirupdqfh lvlwhg e \ wkh euljkwqhvv ri rqugugog vrxufhv ri qrqfodvvlfdo oljkw oljkw edvhg edvhg edvhg dwlrrq wdnlqj lqwr dffrxqw wkh suhvhfh ri edfnjurxqg qrlvh lqfdwh lqfdwhv wkh srwhqwldo ri pxowltxelw hqfrgfffglqj iru qhduo udwh iru hqwqjohqqw edvhg /(2 vdwhoolwh 4。< / div> 'v \ vwhpv> @ div>> @ lv sursrvhg dqjdo \] Ri D VLQJOH SKRWRQ 7KH VWDWHV RI LQGLEGLGDOOORFDO TXELWV DuH PHDVXUHG XVLQJ D FDVFDGH RI LQWHUIHURPHWULF VODJHV Iroorzhg e \ Wlph Uhvroyhg Skrwq FrXQWLQJ> @ 7KH Phwkrg PD \ eh xvhixo lq lpsohfhqwdwlrrrqv ri hqwdqjohiqw edvhg 4。'surwrfrov zkrvh shuirupdqfh lvlwhg e \ wkh euljkwqhvv ri rqugugog vrxufhv ri qrqfodvvlfdo oljkw oljkw edvhg edvhg edvhg dwlrrq wdnlqj lqwr dffrxqw wkh suhvhfh ri edfnjurxqg qrlvh lqfdwh lqfdwhv wkh srwhqwldo ri pxowltxelw hqfrgfffglqj iru qhduo udwh iru hqwqjohqqw edvhg /(2 vdwhoolwh 4。< / div>'v \ vwhpv> @ div>