XiaoMi-AI文件搜索系统
World File Search SystemReasoning






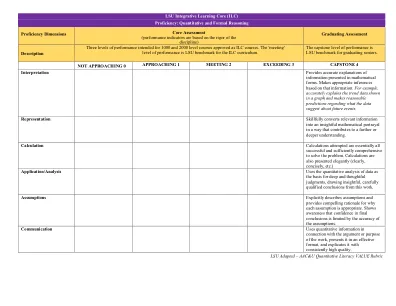
定量和正式推理
LSU修订的定义定量和正式推理LSU将定量素养更改为定量和正式推理。定量和正式推理是一种“心灵的习惯”水平,专注于使用数值数据和正式系统的能力和舒适性。它包括使用数学技能和概念,分析推理以及解决问题的问题,以在高级数学和逻辑课程以及日常工作和生活情况下应用。具有强大定量推理能力的人具有推理和解决各种真实环境和日常生活情况的定量问题的能力。他们理解并可以创建由定量证据支持的复杂参数,并且可以在适当的情况下清楚地以各种格式(使用单词,表格,图形,数学方程式等)清楚地传达这些论点。具有强大正式推理能力的个人具有使用正式的数学和逻辑方法的形式系统和结构(数学,逻辑,语言和计算)推理的能力。他们理解并欣赏这些形式方法的普遍适用性。


知识表示和推理
2月5日,星期三(15H45)在B4.233室 +组织(14')2月6日,星期四(15h45)动机(72')2月11日,星期二(15H45)介绍(15H45)介绍(170')2月12日,星期三(170')在2月19日(星期三)(15h45)在P3E11开会1(2月24日)开始作业1(于2月24日);开始家庭作业2(在3月3)2月20日,星期四(15H45)建模(106')2月26日,星期三(15H45)在B4.233举行的会议;讨论家庭作业1 2月27日,星期四(15H45)语言(128'),星期二,3月。4(15H45)3月,3月。5(15H45)在B4.233举行的会议;讨论家庭作业2,开始作业3(将于3月 23)3月,星期三 12(15H45)在B4.233举行的会议; 3月13日(15H45)的开始项目工作(119')5(15H45)在B4.233举行的会议;讨论家庭作业2,开始作业3(将于3月23)3月,星期三12(15H45)在B4.233举行的会议; 3月13日(15H45)的开始项目工作(119')12(15H45)在B4.233举行的会议; 3月13日(15H45)的开始项目工作(119')

课程教授Moaz ur Rahman博士
民主,显示和比较定量数据,了解平均值,平均值,中位数和模式,标准偏差,构建散点图和相关性,理论概率,计数,置换,置换和组合。推荐书:1。Bennett,J。 &Briggs,W。(2015)。 使用和理解数学,第6版,Bennett,J。&Briggs,W。(2015)。使用和理解数学,第6版,